
「Pandasがどのようなライブラリかよくわからない」という方のために、本記事では「Pandas」の基本情報からメリット、具体的な使用方法まで解説します。「Pandas」についての基礎知識もわかりやすく解説しているので、参考にしてみてください。
「Python」でプログラミングをする際に、必ずと言ってよいほど使うのがライブラリです。数多くの種類がある「Python」のライブラリの中に、「Pandas」というライブラリがあります。
「Pandasというライブラリは聞いたことあるけど、どのようなライブラリかよくわからない」という方も多いのではないでしょうか。そこで本記事では、「Pandas」の基本情報やメリット、具体的な使用方法をわかりやすく解説します。
目次
PythonのライブラリPandasとは?

「Pandas」とは、「Python」のライブラリの一つです。ライブラリとは、ある特定の機能を持たせた複数のプログラムをまとめて「部品」のような状態にし、一つのファイルにしたものです。ライブラリを呼び出すコードを記述することで、その機能を使えます。
「Pandas」は、さまざまな機能の実装を行うときに使われる処理コードが集められています。「Pandas」に実装されている具体的な機能は、以下の通りです。
- データの読み込み
- データのグラフ表示
- データの統計的な分析
「Pandas」を使うことで、上記の処理を効率よくコーディングできるでしょう。とくに「Python」を使って機械学習を扱う場合は、前処理として読み込んだデータを整えるために「Pandas」を使用します。
「Pandas」は、オープンソース(著作権の表示と免責条項を明記することで、再配布や再利用が可能になるBSDライセンス)のライブラリであり、誰でも無料で利用できるだけでなく商用利用も可能です。
Pandasを利用するメリットは何?

「Pandas」を利用すると、どのようなメリットがあるのでしょうか。ここでは、「Pandas」を利用するメリットを3つ紹介します。
一つのデータフレームで異なる入力ができる
「Pandas」を利用するメリットに、異なる入力を一つのデータフレームに格納できる点があります。
たとえば、同じく「Python」のライブラリである「Numpy」は、すべての要素を同じデータ型にそろえる必要があります。しかし「Pandas」は、列ごとに違うデータ型の要素を入れてもエラーになりません。
そのため整数や小数、文字列、日付など、それぞれのデータ型が異なっていても一つのデータフレームとして扱うことが可能です。とくにCSVファイルの読み込みでは、データの配列を気にする必要がなくエラーがほぼ起きないため、処理を実装するのが容易になります。
データ処理に役立つ関数が豊富
データ処理に役立つ関数が豊富な点もメリットです。
たとえばデータの読み込みや切り出し、文字列と数値の型変換、特定の列の抽出、平均・分散・標準偏差の統計量計算など、データを解析する上で必要となる機能が多く備わっています。
そのため、「Pandas」を使って読み込んだCSVファイルのデータを使用することで、データを前処理する際の効率化が可能です。
他のライブラリとの連携も取れる
「Pandas」は、他のライブラリとの連携が可能です。
「Pandas」だけで行えないことは、他のライブラリと連携によって、さまざまな機能を実装できます。具体的な例としては、グラフを描画したり、加工したデータを表計算ソフトのファイル形式に合わせて出力したりといった処理が可能です。
Pandasをインストールしてみよう!

「Pandas」のインストールは、下記のように「pipコマンド」を使って行えます。「Mac」を使っている場合はターミナルから、「Windows」の場合はコマンドプロンプトから実行することでインストールができます。
pip install pandas
また、「Jupyter Notebook」や「Spyder」などを使う場合には、先頭に「!」をつけてから同じコマンドを実行することでインストールが可能です。
「pipコマンド」を使って「Pandas」のインストールができたら、次は「Pandas」のライブラリを「Python」で読み込みます。以下のコードでは、「Pandas」を読み込んで「pd」という名前で扱えるようになっています。
import pandas as pd
「Linux」を使っている場合は、ディストリビューションのパッケージマネージャでインストール可能です。しかしバージョンが古くなっている可能性が高いため、とくに理由がない場合には「conda」や「pip」によるインストールがおすすめです。
Pandasのデータ型は3種類ある

「Pandas」のデータ型は3つのデータ形式があり、それぞれシリーズ型、データフレーム型、パネル型と呼ばれています。ここからは、それぞれのデータ形式がどのようなものか詳しく見ていきます。
シリーズ型
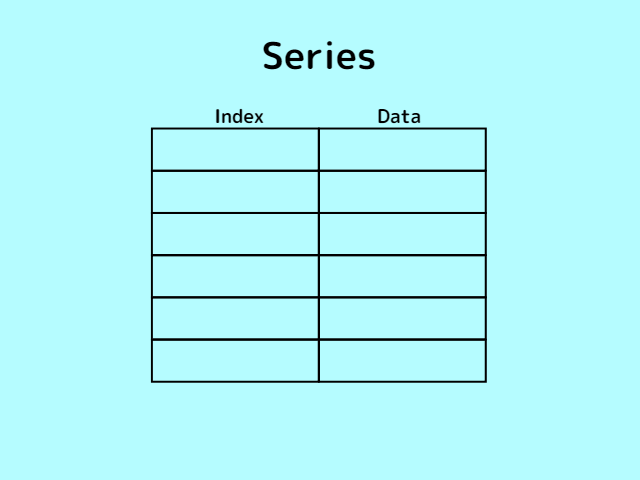
シリーズ型は、「Pandas」で扱える一次元の配列のことを指します。
「Python」や「Java」、「C言語」など通常のプログラミング言語で扱われる1次元と配列が違い、「Pandas」では配列にラベルを与えられます。
シリーズ型におけるラベルは「インデックス」と呼ばれ、「インデックス」を使って実際のデータにアクセスが可能です。
次に紹介するデータフレーム型から行もしくは列のみを抽出したものは、シリーズ型を指します。
データフレーム型
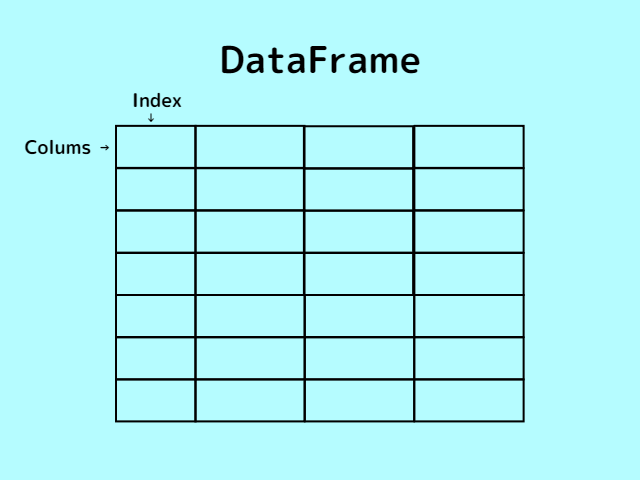
データフレーム型は、「Pandas」で扱える二次元配列を指します。データフレーム型では、インデックスラベルだけでなく、カラムラベルを与えることが可能です。
インデックスを「行ラベル」、カラムを「列ラベル」と呼ぶ場合もあります。
また、「DataFrame.index.values()」や「DataFrame.columns.values()」といった関数を用いて行や列の数を取得でき、「DataFrame.sort_index()」でソートを行うことも可能です。
パネル型
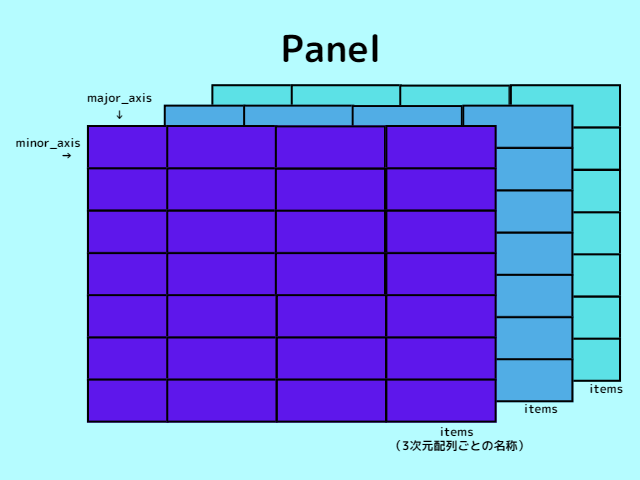
パネル型は、「Pandas」で扱う三次元配列です。パネル型には3つのラベルがあり、それぞれ「items」、「major_axis」、「minor_axis」と呼ばれています。先ほどのデータフレーム型においてインデックス、カラムに対応しているのが「major_axis」、「minor_axis」です。
三次元配列はイメージするのが難しく直感的な操作も少し難しいため、頻繁に使われることはありません。しかし、時系列データを扱うときに利用されます。
PandasにCSVファイルを読み込ませる方法

ここでは、CSVファイルを「Pandas」に組み込む方法について解説します。
「Pandas」は、「read_csv()」という関数を使ってCSVファイルを読み込むことで、データフレーム型オブジェクトの生成が可能です。この関数の「encoding引数」には、指定したいファイルの文字コードを渡します。具体的なコードの実装例は、以下の通りです。
test_data = pd.read_csv(‘test.csv’)
「head()メソッド」を使うと先頭の数行を表示させられるので、以下のようなコードを書いて最初の5行を表示してみましょう。
test_data.head(5)
また、データフレーム型のインデックス属性により、データフレームのインデックス情報を取得できます。さらに、「len()関数」を用いることで、以下のようなオブジェクトの行数表示が可能です。
print(test_data.index) print(len(test_data.index))
データフレーム型の基本の分析方法

「Pandas」は、CSVファイルから読み込んだデータフレーム型のデータを扱うことがあります。そこで、ここではデータフレーム型の分析を行う上で必要な基本の操作方法を解説します。
オブジェクトデータの作成方法
データフレームは以下のようなコードで、リストや配列、辞書などから作成します。
data1 = pd.DataFrame([[0,1,2],[3,4,5],[6,7,8]], index=[30, 31, 32], columns=[‘c1’, ‘c2’, ‘c3’])
これにより、次のようなデータフレームが作成されます。
c1 c2 c3 30 0 1 2 31 3 4 5 32 6 7 8
インデックスの指定を省略すると、0から始まる整数がインデックス番号として自動的に割り当てられます。
データフレームを辞書から作る場合は、「カラム引数」を用いて列を指定します。
data2 = pd.DataFrame({‘Fruits’: [‘banana’, ‘apple’], ‘Colors’: [‘yellow’, ‘red’]}, columns=[‘Fruits’, ‘Colors’])
このコードで次のデータフレームを作成できます。
Fruits Colors 0 banana yellow 1 apple red
列の追加と削除方法
データフレームに列を追加したい場合は追加する新しい列名を指定し、それを代入することで列を追加できます。具体的なコードの例は以下の通りです。
test_data[‘new_column’] = np.random.rand(len(test_data.index))
また「del文」を使うことで、以下のようにデータフレームから指定した列を削除できます。
del test_data[‘new_column’]
行の追加と削除方法
データフレームに新しい行を追加したい場合は、「Pandasライブラリ」の「append()メソッド」を使用します。test_dataの末尾に新しい行を挿入するコードの例は、以下の通りです。
new_row = pd.DataFrame([[‘a’, ‘b’, 1, 2]], columns=test_data.columns) test_data = test_data.append(new_row, ignore_index=True)
「drop()メソッド」を使用することで、行を削除できます。
データの抽出方法

まずは、一つの条件を指定してデータフレームからデータを抽出する方法を解説します。次のように、列「column1」の値が「A1」となる条件を指定すると、その条件を満たす行の情報のみが表示されます。
test_data[test_data[‘column1’] == ‘A1’]
続いて複数の条件を指定しすべての条件に合致するものを抽出するには、論理演算子andを表す「&」、いずれかの条件に一致させたい場合はorを表す「|」、条件を反転させるにはnotを表す「~」を使います。次のコードでは、test_dataデータフレームの列「column1」の値が「A1」もしくは「A2」であるものを抽出可能です。
test_data[(test_data[‘column1’] == ‘A1’) | (test_data[‘column1’] == ‘A2’)]
それでは、次に特定の場面でのデータ抽出方法を説明します。
head()の使い方
先頭の数行を表示させたい場合に使うのが、「head()メソッド」です。デフォルトは5行分になっており、引数を何も指定しなかった場合は最初の5行のみを表示します。
test_data.head()
次のコードのように引数を3に設定すると、最初の3行を表示します。
test_data.head(3)
データフレームにどのような要素が入っているのかを手軽に確認したい場合によく使われるメソッドです。
tail()の使い方
「head()メソッド」とは反対に、最後の数行を取得したい場合に使用されるのが「tail()メソッド」です。「head()メソッド」と同じくデフォルトは5行分となっており、以下のように引数に3を渡すと、最初の3行のみを返してくれます。
test_data.tail(3)
データの先頭と末尾から同時に要素を確認することも可能で、その際には、以下のように「append()メソッド」を使います。
test_data.head().append(test_data.tail())
locの使い方
「loc」は、行もしくは列の名前を指定すると、特定の値が抽出できるメソッドです。
たとえば、以下のようなデータフレーム「test_data」を考えます。
column1 column2 row1 10 20 row2 30 40
このとき、「test_data.loc[‘row1’, :]」と指定すると、行の名前が「row1」の行だけを抽出可能です。ここでも「:」は、その行のすべての要素を抽出することを示しています。
よって出力は、
column1 10 column2 20
となります。
ilocの使い方
「iloc」は、インデックスを指定することによって値の抽出を行うメソッドです。
ここでは、以下のデータフレームtest_dataを考えます。
column1 column2 row1 10 20 row2 30 40 row3 50 60
このとき、「test_data.iloc[0:2]」と指定すると、インデックスが0以上2未満の要素を抽出するため、出力は以下のようになります。
column1 column2 row1 10 20 row2 30 40
Pandasを使いこなしてデータ処理に挑戦しよう

「Pandas」は、データ解析を簡単に処理できる機能が用意された「Python」のライブラリです。
データ型の種類や基本の分析方法、データの抽出方法の正しい知識を身につけることで、一つのデータフレームに異なる入力ができたり、データ処理に役立つさまざまな関数が使えたりと、多くのメリットがあります。
本記事を参考に「Pandas」の使い方をマスターし、さまざまな機能の実装を効率よく行ってください。











アクセスランキング 人気のある記事をピックアップ!
コードカキタイがオススメする記事!

2024.06.17
子供におすすめのプログラミングスクール10選!学習メリットや教室選びのコツも紹介
#プログラミングスクール

2022.01.06
【完全版】大学生におすすめのプログラミングスクール13選!選ぶコツも詳しく解説
#プログラミングスクール

2024.01.26
【未経験でも転職可】30代におすすめプログラミングスクール8選!
#プログラミングスクール

2024.01.26
初心者必見!独学のJava学習方法とおすすめ本、アプリを詳しく解説
#JAVA

2024.01.26
忙しい社会人におすすめプログラミングスクール15選!失敗しない選び方も詳しく解説
#プログラミングスクール

2022.01.06
【無料あり】大阪のおすすめプログラミングスクール14選!スクール選びのコツも紹介
#プログラミングスクール

2024.01.26
【目的別】東京のおすすめプログラミングスクール20選!スクール選びのコツも徹底解説
#プログラミングスクール

2024.01.26
【無料あり】福岡のおすすめプログラミングスクール13選!選び方も詳しく解説
#プログラミングスクール

2024.01.26
【徹底比較】名古屋のおすすめプログラミングスクール13選!選び方も詳しく解説
#プログラミングスクール

2024.01.26
【徹底比較】おすすめのプログラミングスクール18選!失敗しない選び方も徹底解説
#プログラミングスクール