
Pythonの「辞書」とは、「キー」と「値」を関連付けて、複数のデータを管理できる機能です。中身の要素を取り出すときにキーを指定できるので、まるで辞書を引くときのように、直感的にアクセスできることが魅力です。
しかし辞書の使い方は、リストやタプルなど類似するほかの機能とは少し異なります。そのため、辞書は「わかりにくい」「使いにくい」と感じる人も少なくありません。そこで本記事では、Pythonの辞書機能の使い方と実践テクニックについて、サンプルコード付きでわかりやすく解説します。
目次
- Pythonの「辞書」とは?「キー」と「値」を関連付ける機能
- 【基礎編】Pythonの辞書型の使い方
- 【発展編】Pythonの辞書の代表的な関数・メソッド一覧
- dict関数|辞書オブジェクトを生成する
- dict.fromkeys関数|辞書のキーのみ作成する
- get関数|キーを指定して値を取得する
- keys関数|すべてのキーをまとめて取得する
- values関数|すべての値をまとめて取得する
- items関数|すべてのキーと値をまとめて取得する
- setdefault関数|辞書オブジェクトに新しい要素を追加する
- update関数|辞書オブジェクトに別の辞書を追加する
- pop関数|キーを指定して要素を削除する
- popitem関数|ランダムな要素を削除する
- clear関数|すべての要素を削除する
- copy関数|すべての要素を他オブジェクトにコピーする
- dict.fromkeys関数|辞書オブジェクトのキーだけコピーする
- Pythonの辞書オブジェクトで便利な演算子
- Pythonの辞書オブジェクトをソートする方法
- 辞書の値は「辞書」「リスト」「タプル」を格納できる
- 【応用編】Pythonの辞書で条件分岐を簡素化できる
- Pythonの辞書型を活用してソースコードを簡潔化しよう!
Pythonの「辞書」とは?「キー」と「値」を関連付ける機能

Pythonの「辞書(Dictionary)」とは、「キー(Key)」と「値(Value)」を関連付けて、データをまとめて管理できる機能のことです。「連想配列」とも呼ばれ、たとえばキーを「りんご」・値を「赤い」として、「りんごは赤い」などのように両者を関連付けられます。
複数のデータをまとめて管理できる機能として、「リスト」や「タプル」がありますが、これらは以下のように単独のデータをまとめて管理するためのものです。
//サンプルプログラム
# coding: Shift-JIS
# リストオブジェクトを生成する
list_nums = [0, 1, 2, 3, 4, 5]
# タプルオブジェクトを生成する
tuple_nums = (0, 1, 2, 3, 4, 5)
# リストの中身を表示する
print(list_nums)
# タプルの中身を表示する
print(tuple_nums)
//実行結果
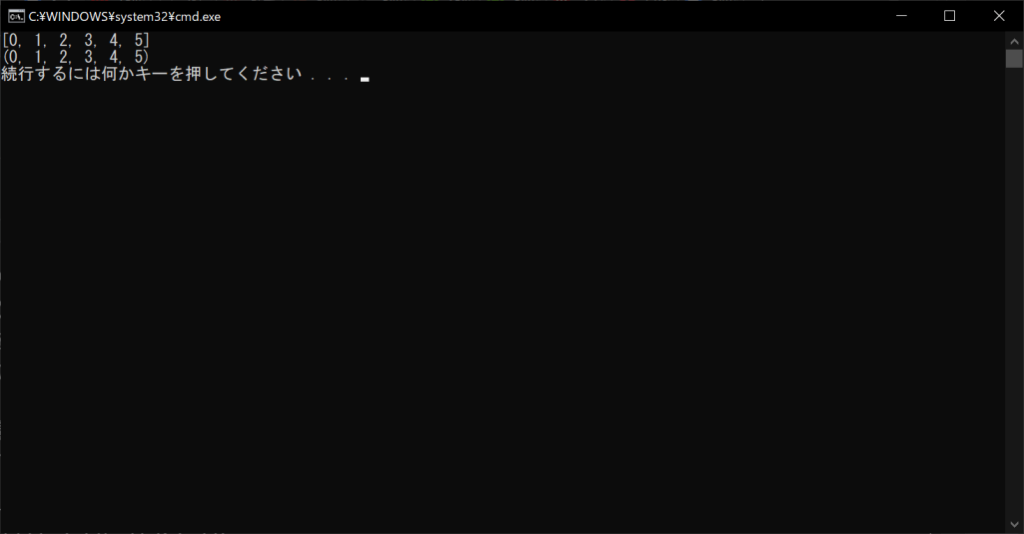
同じ変数にまとめて管理しているものの、それぞれの値は単独のものであり、互いに関連付けられているわけではありません。一方で辞書は、以下のように2つのデータをペアとして、関連性を明確化して管理できます。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
dictionary = {“バナナ”:198, “りんご”:298, “メロン”:998, “いちご”:598, “ぶどう”:398}
# 辞書の中身を表示する
print(dictionary)
//実行結果
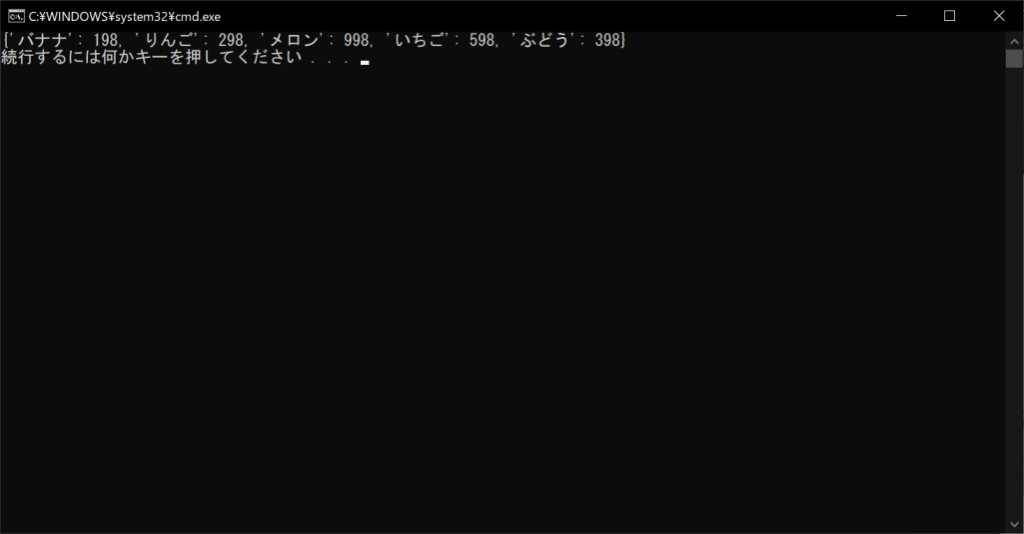
上記のサンプルプログラムは、商品名と価格をペアとして扱い、データをまとめた一例です。たとえば、キーを「りんご」・値を「298」とすれば、「りんごは298円」という情報を管理できます。情報にアクセスするときも、「りんご」というキーを指定すれば、すぐに298という値を取り出すことが可能です。
詳細は後述しますが、このように辞書型では「キー : 値」という形式で、キーと値の2つのデータを関連付けて管理できます。そのため、「Aに対応する値はB」のように、ペアのデータを管理したいときに最適です。
【基礎編】Pythonの辞書型の使い方

Pythonの辞書型の使い方について、以下3つのポイントに分けて解説します。
- 辞書オブジェクトを生成する
- 辞書オブジェクトの要素にアクセスする
- 辞書の要素の追加と変更を行う
辞書オブジェクトを生成する
辞書型オブジェクトを生成するときは、以下のように「{}」の中に「キー」と「値」のペアを「:」で組み、あとはリストやタプルなどと同じように「,」で区切って並べます。
たとえば、「商品名」と「価格」を関連付けて辞書オブジェクトで管理したい場合は、以下のサンプルコードのように記載します。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products = {“食パン”:198, “冷凍パスタ”:248, “野菜ジュース”:128}
# 辞書の中身を表示する
print(products)
//実行結果
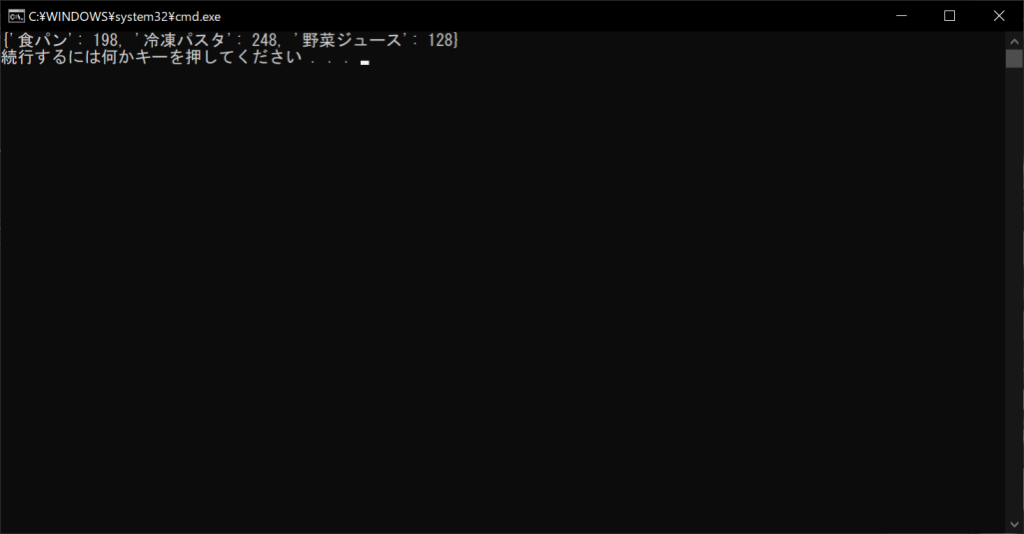
なお、辞書のキーはイミュータブル(変更不可能)なオブジェクト、つまり文字列・数値・タプルのみ使えます。これは、キーが意図せず変更されてしまい、バグの原因になることを防ぐためです。そのため、ミュータブルなリストやクラスオブジェクトなどは、キーに設定できません。一方、値はどのようなオブジェクトでも格納でき、値に辞書を含めることも可能です。
辞書オブジェクトの要素にアクセスする
辞書型では、リスト型のように多数の要素をまとめて管理できます。ただしリスト型とは異なり、辞書型には要素の順序関係がないため、リスト型のように「インデックス」でアクセスすることはできません。そのため、以下の構文のとおり「キー」を指定してアクセスします。
実際に、辞書オブジェクトを作り、任意のキーを指定して要素にアクセスしてみましょう。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products = {“食パン”:198, “冷凍パスタ”:248, “野菜ジュース”:128}
# 辞書の中身を表示する
print(products[“冷凍パスタ”])
//実行結果
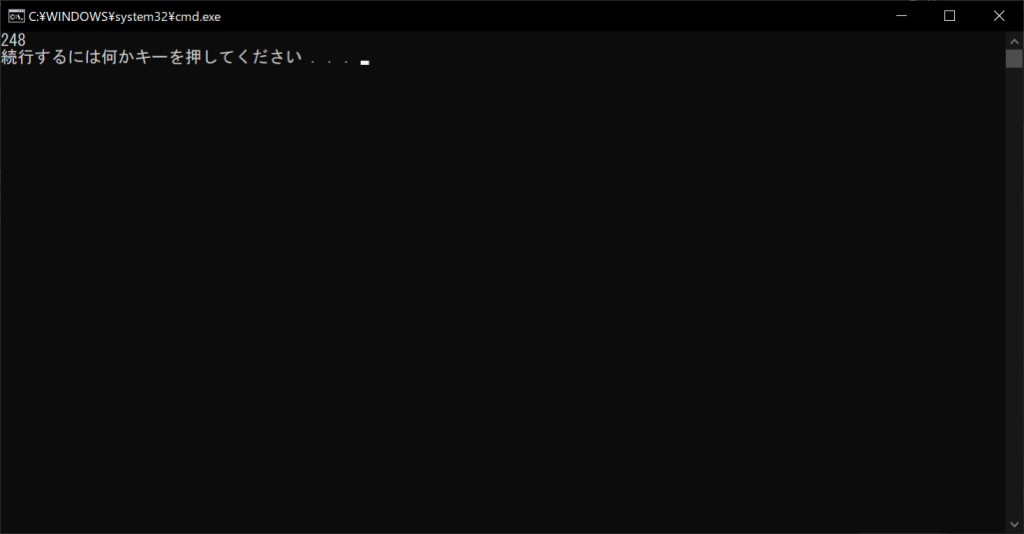
今回は「冷凍パスタ」というキーを指定したため、それと関連付けられた「248」という数値が表示されます。なお、辞書型オブジェクト内に存在しないキーを指定した場合は、エラーが表示されるので注意が必要です。
辞書の要素の追加と変更を行う
生成した辞書オブジェクトに新しい要素を追加したい場合は、以下の構文で記載すると自動的に新しい要素として追加される。
一方、すでに存在する要素の値を変更したい場合は、以下の構文で記載します。ただし、キーを変更することはできません。
辞書型では、要素の追加と変更はどちらも同じ構文となります。つまり、上記の構文で記載すると、すでに要素があるときは値が変更・更新されて、要素が存在しない場合は新規に追加されるということです。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products = {“食パン”:198, “冷凍パスタ”:248, “野菜ジュース”:128}
# 辞書の中身を表示する
print(products)
# 辞書オブジェクトに新しい要素を追加する
products[“豚バラ肉”] = 278
# 辞書の中身を表示する
print(products)
# 「冷凍パスタ」の値を変更する
products[“冷凍パスタ”] = 198
# 辞書の中身を表示する
print(products)
//実行結果
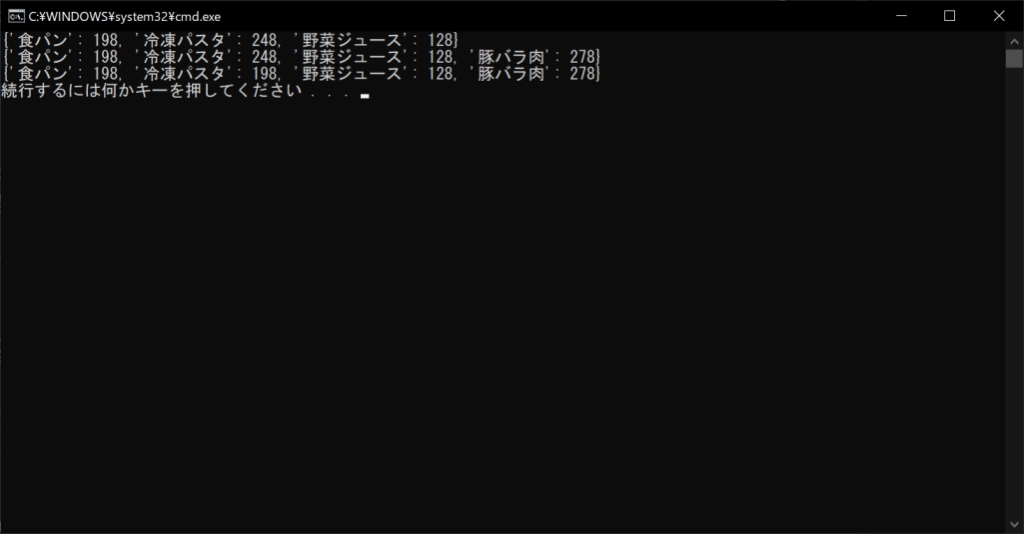
辞書オブジェクトを作成したあとで、まず「豚バラ肉」要素を追加していましょう。次に「冷凍パスタ」キーを指定していますが、こちらはすでに存在する要素なので、値の変更となります。
【発展編】Pythonの辞書の代表的な関数・メソッド一覧

Pythonの辞書にある代表的な以下13個の関数・メソッドについて解説します。いずれも重要な関数なので、ぜひ覚えておきましょう。
- dict関数|辞書オブジェクトを生成する
- dict.fromkeys関数|辞書のキーのみ作成する
- get関数|キーを指定して値を取得する
- keys関数|すべてのキーをまとめて取得する
- values関数|すべての値をまとめて取得する
- items関数|すべてのキーと値をまとめて取得する
- setdefault関数|辞書オブジェクトに新しい要素を追加する
- update関数|辞書オブジェクトに別の辞書を追加する
- pop関数|キーを指定して要素を削除する
- popitem関数|ランダムな要素を削除する
- clear関数|すべての要素を削除する
- copy関数|すべての要素を他オブジェクトにコピーする
- dict.fromkeys関数|辞書オブジェクトのキーだけコピーする
dict関数|辞書オブジェクトを生成する
「dict関数」は、辞書型オブジェクトを生成するためのメソッドです。dict関数の構文は以下のとおりです。
通常の初期化構文とは異なり、「:」ではなく「=」でキーと値を結びつけることがポイントです。 また、キーが文字列型であっても「’」や「”」といったクォーテーションが不要なので、dict関数を使うほうが便利なこともあります。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトをdict関数で生成する
products = dict(食パン = 198, 冷凍パスタ = 248, 野菜ジュース = 128)
# 辞書の中身を表示する
print(products)
//実行結果
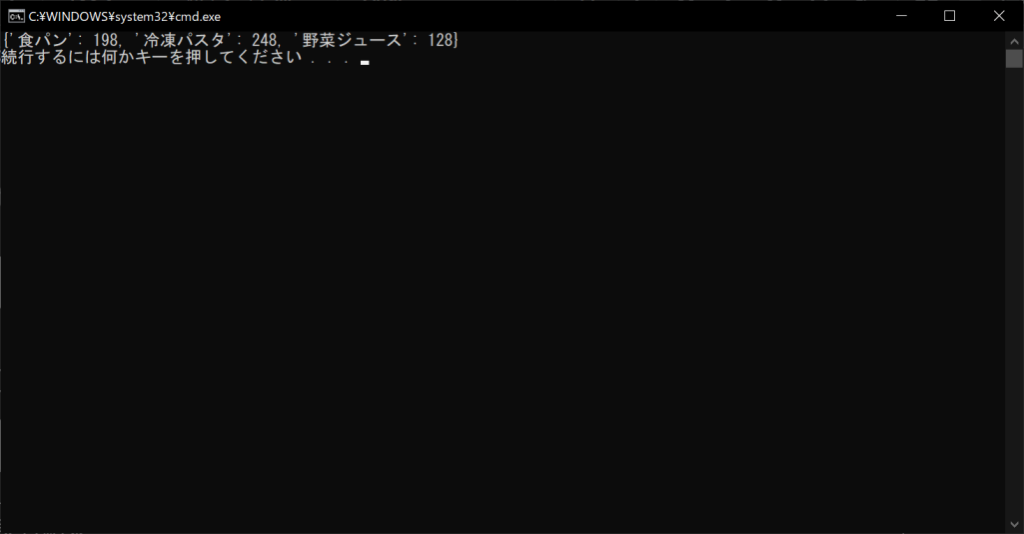
なお、もともとキーと値がペアとなっているリストやタプルは、dict変数に引数として渡すとそのまま辞書型に変換できます。
//サンプルプログラム
# coding: Shift-JIS
# リストオブジェクトを生成する
products_list = [(“食パン”, 198), (“冷凍パスタ”, 248), (“野菜ジュース”, 128)]
# リストオブジェクトを辞書オブジェクトに変換する
dictionary_products = dict(products_list)
# 辞書の中身を表示する
print(dictionary_products)
ただし、キーと値がペアになっていない要素がひとつでもあると、dict変数に引数として渡せないので注意が必要です。
dict.fromkeys関数|辞書のキーのみ作成する
「dict.fromkeys関数」は、キーのみを登録して、値が空の辞書を生成できます。dict.fromkeys関数の構文は以下のとおりで、キーを並べたリストやタプルを引数として渡します。
キーのみを登録した辞書を作成したあとは、いつでも値を設定できます。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: Shift-JIS
# キーのみを格納した辞書オブジェクトを生成する
products = dict.fromkeys([“食パン”, “冷凍パスタ”, “野菜ジュース”])
# 辞書の中身を表示する
print(products)
# 「冷凍パスタ」の値を設定する
products[“冷凍パスタ”] = 248
# 辞書の中身を表示する
print(products)
//実行結果
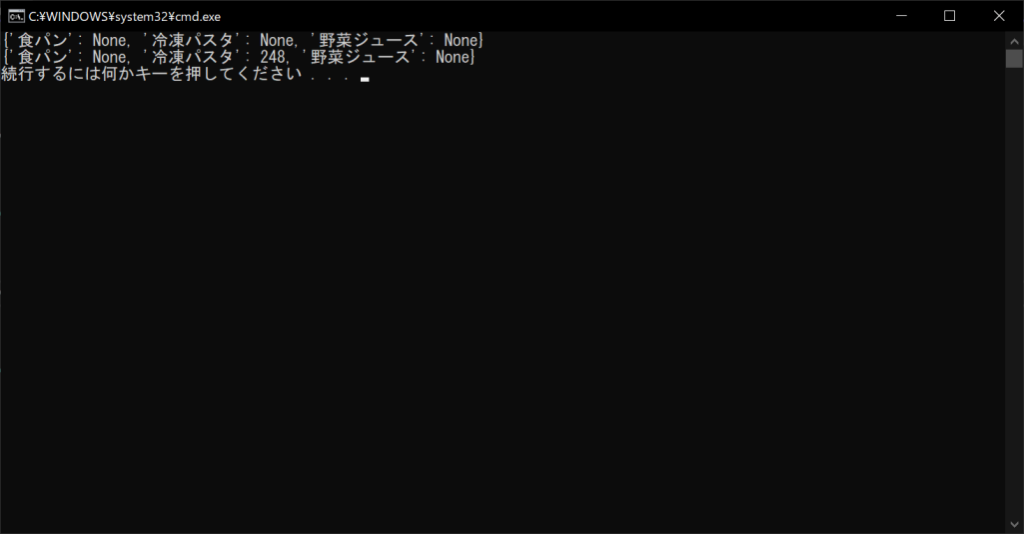
値の設定方法は前述したように、「[]演算子」でキーを指定するだけです。
get関数|キーを指定して値を取得する
「get関数」の引数にキーを指定すると、全要素から該当する値を取得できます。なお、値が存在しない場合は「None」が返るので、先ほど紹介した「[]演算子」より便利です。get関数の構文は以下のとおりです。
なお第2引数には、存在しないキーを指定した場合の戻り値を指定できます。たとえば「-1」を指定すると、キーが存在しない場合に「-1」が返ります。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products = {“食パン”:198, “冷凍パスタ”:248, “野菜ジュース”:128}
# 辞書の中身を表示する
print(products)
# 「冷凍パスタ」の値を取得する
print(products.get(“冷凍パスタ”, “キーが存在しません!”))
# 「冷凍ポテト」の値を取得する
print(products.get(“冷凍ポテト”, “キーが存在しません!”))
//実行結果
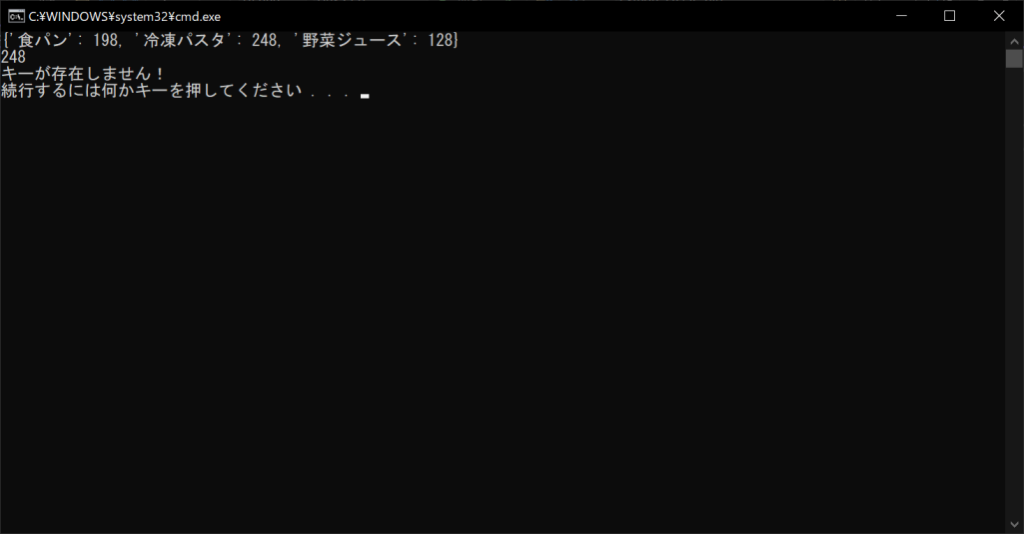
「冷凍パスタ」は辞書に含まれているため、「248」という数値が返ってきました。一方、「冷凍ポテト」は存在しないため、デフォルト値として設定した「キーが存在しません!」というメッセージが表示されます。
keys関数|すべてのキーをまとめて取得する
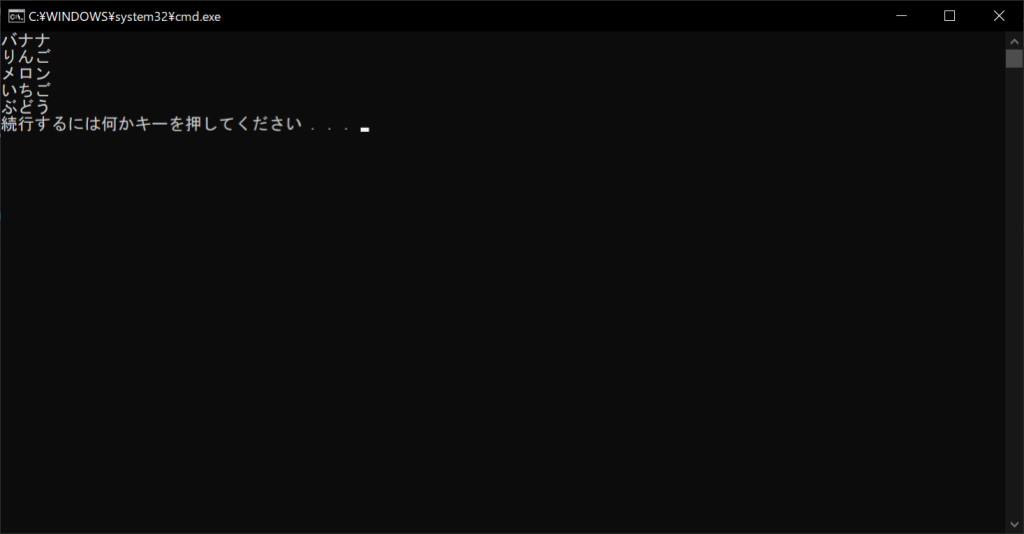
「keys関数」は、辞書型オブジェクトに含まれているすべてのキーを取り出すためのメソッドです。以下のように、forループのイテラブルオブジェクトに「辞書型変数.keys()」を指定すると、以下のようにキーの一覧を表示できます。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products = {"バナナ":198, "りんご":298, "メロン":998, "いちご":598, "ぶどう":398}
# すべてのキーを取得して表示する
for key in products.keys():
print(key)
//実行結果
values関数|すべての値をまとめて取得する
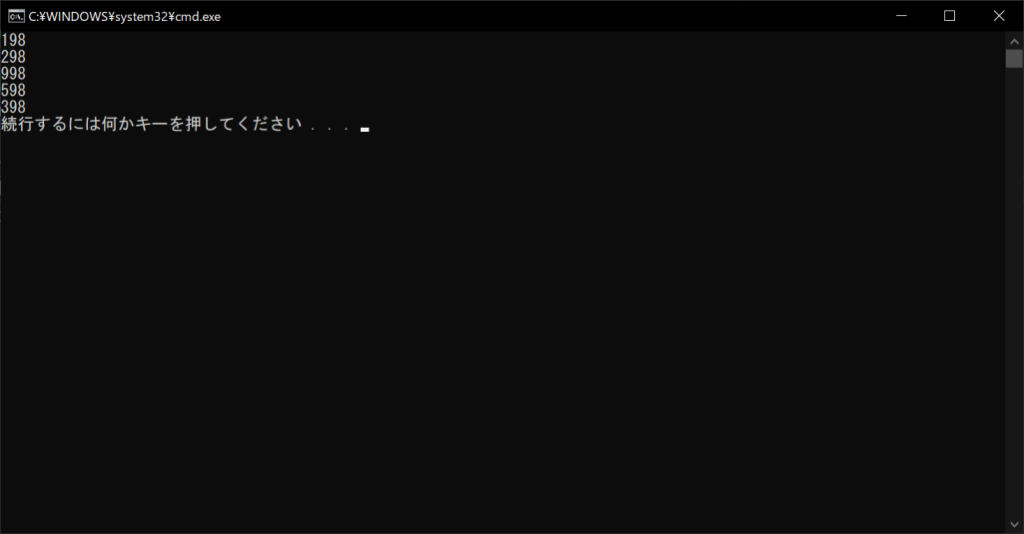
「values関数」は、辞書型オブジェクトに含まれているすべての値を取り出すためのメソッドです。前述したkeys関数と同じように、forループのイテラブルオブジェクトに「辞書型変数.values()」を指定すると、以下のようにすべての値を取得できます。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products = {"バナナ":198, "りんご":298, "メロン":998, "いちご":598, "ぶどう":398}
# すべての値を取得して表示する
for value in products.values():
print(value)
//実行結果
items関数|すべてのキーと値をまとめて取得する
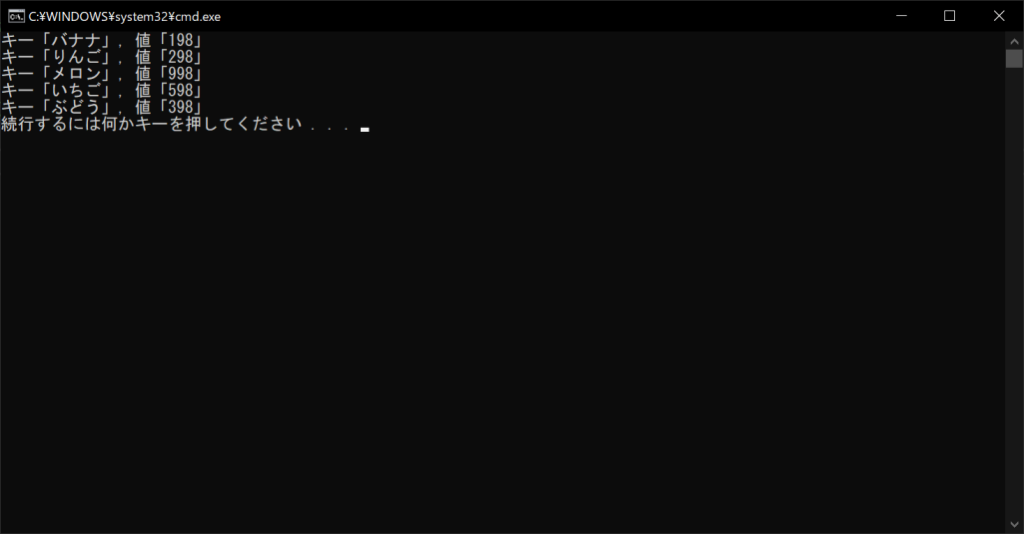
「items関数」を使用すると、辞書型オブジェクトに含まれているすべてのキーと値を、まとめて取り出せます。keys関数とvalues関数と同じように、forループのイテラブルオブジェクトとして指定しましょう。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products = {"バナナ":198, "りんご":298, "メロン":998, "いちご":598, "ぶどう":398}
# すべてのキーと値を取得して表示する
for key, value in products.items():
print("キー「" + key + "」, 値「" + str(value) + "」")
//実行結果
setdefault関数|辞書オブジェクトに新しい要素を追加する
「setdefault関数」は、既存の辞書オブジェクトに新しい要素を追加するためのメソッドです。以下のように、第1引数にキー・第2引数に値を設定すると、簡単に要素を追加できます。
ただし、指定したキーがすでに存在する場合は何も行わないので、値が変更されることはありません。既存値を書き換えたい場合は、前述したように「[]演算子」で要素にアクセスして、書き換える必要があります。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products = {“バナナ”:198, “りんご”:298, “メロン”:998, “いちご”:598, “ぶどう”:398}
# 辞書の中身を表示する
print(products)
# 新しい要素を追加する
products.setdefault(“パイナップル”, 498)
# 辞書の中身を表示する
print(products)
# 既存の要素は変更されない
products.setdefault(“バナナ”, 98)
# 辞書の中身を表示する
print(products)
//実行結果
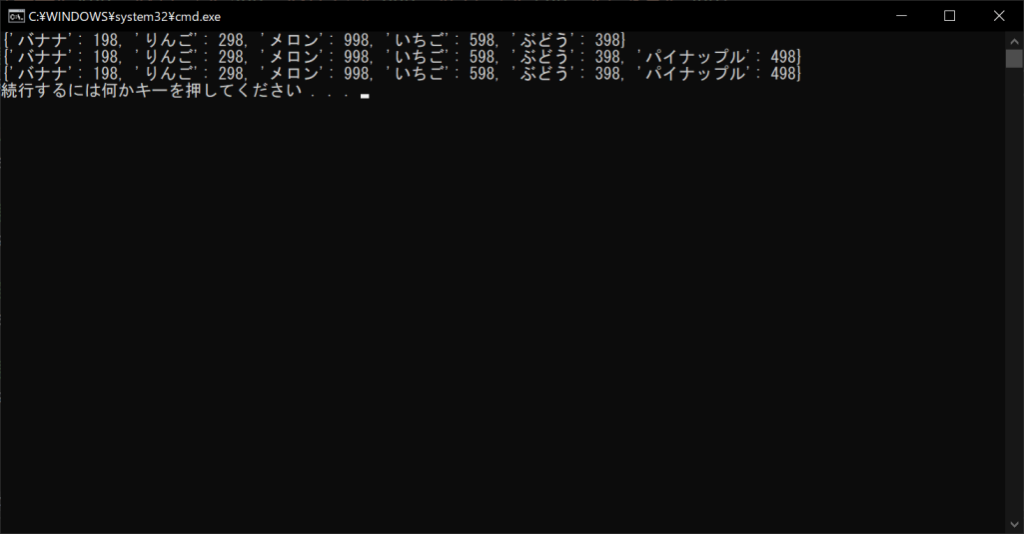
上記のように、辞書オブジェクトに存在しないキー「パイナップル」を指定した場合は、要素が追加されます。ただし、「バナナ」はすでに存在するので、何も行われません。
update関数|辞書オブジェクトに別の辞書を追加する
「update関数」は、2つの辞書オブジェクトを結合するためのメソッドです。update関数の構文は以下のとおりです。
このように記載すると、「辞書型変数1」に「辞書型変数2」の要素を追加できる。変数の順番を逆にすると、「辞書型変数2」に「辞書型変数1」の要素が追加されるので注意が必要です。update関数の使い方を以下のサンプルコードで確認しましょう。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products_1 = {“バナナ”:198, “りんご”:298, “メロン”:998}
products_2 = {“いちご”:598, “ぶどう”:398, “パイナップル”:498}
# 辞書の中身を表示する
print(products_1)
print(products_2)
# 「products_1」に「products_2」を結合する
products_1.update(products_2)
# 辞書の中身を表示する
print(products_1)
//実行結果
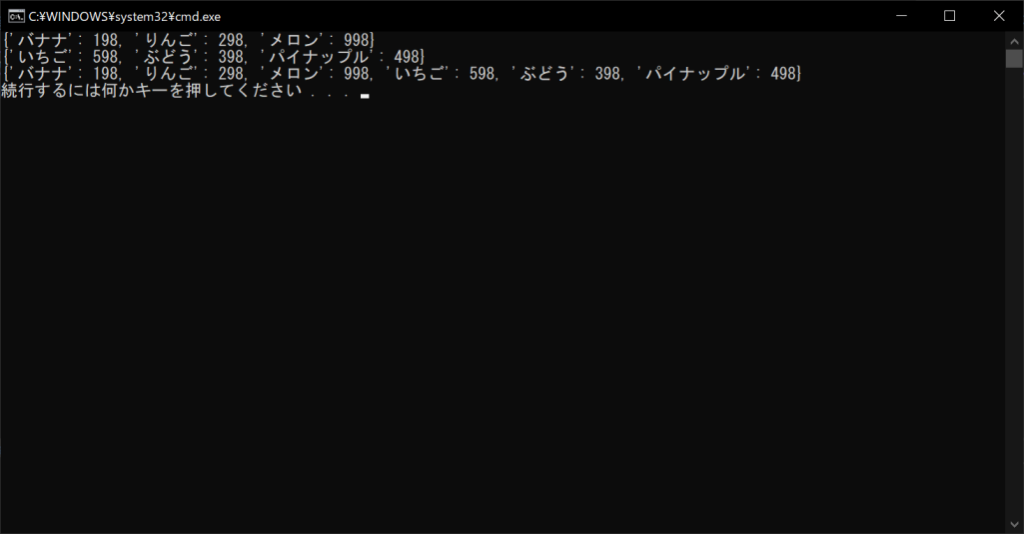
pop関数|キーを指定して要素を削除する
「pop関数」は、任意のキーを指定して要素を削除できます。pop関数の構文は以下のとおりです。
なお、pop関数は戻り値として、削除したキーに対応する値を返します。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products = {“バナナ”:198, “りんご”:298, “メロン”:998, “いちご”:598, “ぶどう”:398, “パイナップル”:498}
# 辞書の中身を表示する
print(products)
# 辞書オブジェクトから「メロン」を削除する
deleted = products.pop(“メロン”)
# 辞書の中身を表示する
print(products)
# 削除したキーに対応する値を表示する
print(deleted)
//実行結果
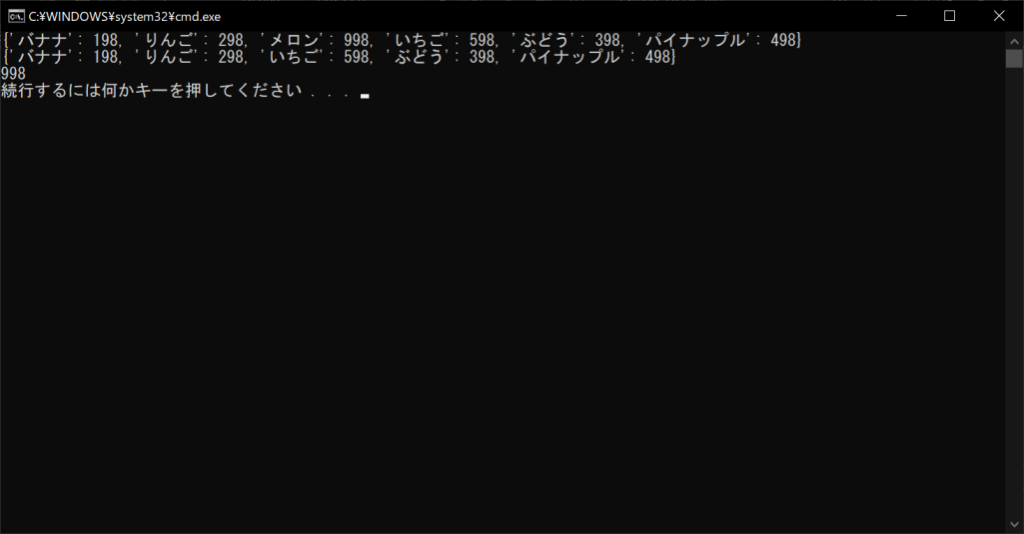
pop関数で「メロン」を指定したため、その値である「998」が戻り値として返ります。pop関数を呼び出したあとに辞書の中身を表示すると、メロンの部分が正しく削除されていることがわかります。
popitem関数|ランダムな要素を削除する
「popitem関数」は、ランダムな要素を削除するためのメソッドです。特定の要素ではなく、とにかくひとつの要素を取り除きたいときに役立ちます。popitem関数の構文は以下のとおりです。
なお、popitem関数は戻り値として、削除した要素のキーと値のタプルを返します。どの要素が削除されたか確認したいときは、戻り値のタプルを確認しましょう。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products = {“バナナ”:198, “りんご”:298, “メロン”:998, “いちご”:598, “ぶどう”:398, “パイナップル”:498}
# 辞書の中身を表示する
print(products)
# 辞書オブジェクトからランダムな要素を削除する
deleted = products.popitem()
# 辞書の中身を表示する
print(products)
# 削除した要素を表示する
print(deleted)
//実行結果
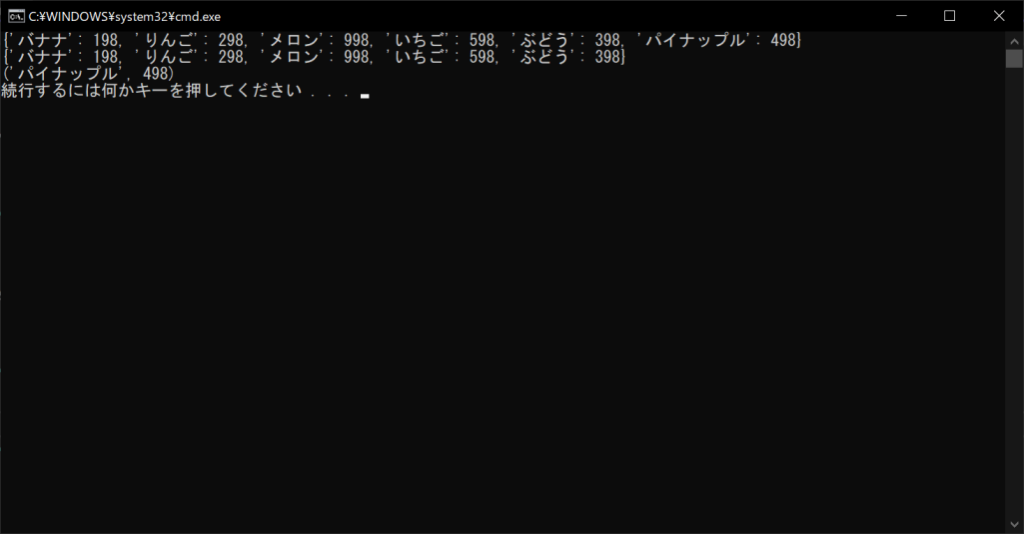
削除される要素はランダムに決まるため、実行するたびに結果は変わります。今回は「パイナップル:498」の要素が削除されました。
clear関数|すべての要素を削除する
「clear関数」は、すべての要素を削除して空の辞書にするためのメソッドです。以下のサンプルコードのように、clear関数を呼び出すだけでOKです。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products = {“バナナ”:198, “りんご”:298, “メロン”:998, “いちご”:598, “ぶどう”:398, “パイナップル”:498}
# 辞書の中身を表示する
print(products)
# 辞書オブジェクトからすべての要素を削除する
products.clear()
# 辞書の中身を表示する
print(products)
//実行結果
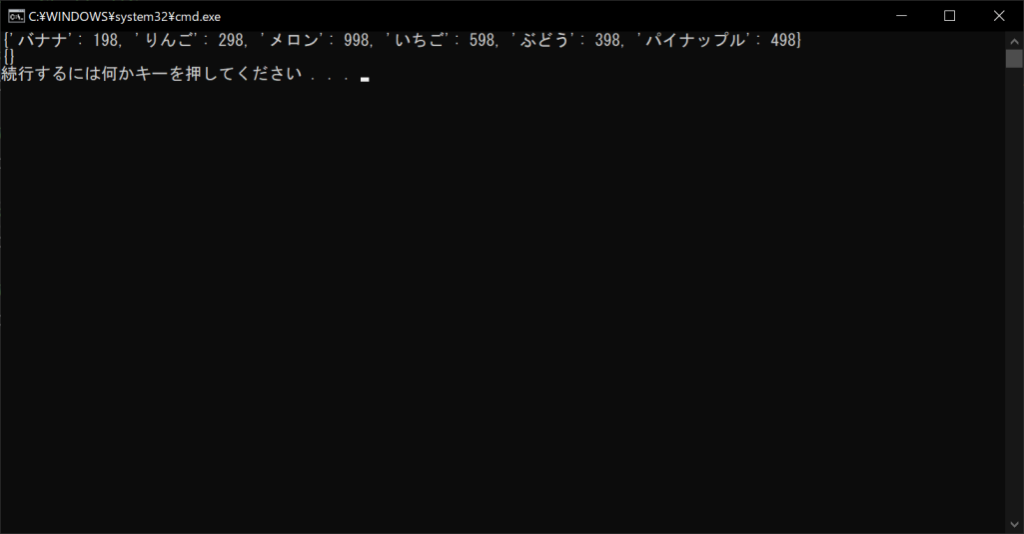
実際に中身を表示してみると、clear関数を呼び出すとすべて綺麗にクリアされることがわかります。
copy関数|すべての要素を他オブジェクトにコピーする
「copy関数」は、辞書オブジェクト内のすべてのキーと値をコピーするためのメソッドです。使い方は簡単で、以下のように記載するだけです。
Pythonの辞書オブジェクトをコピーしたいとき、「=演算子」を使うのはNGです。これは単に「代入」であり、オブジェクトのコピーではありません。辞書オブジェクトは変更不能な「ミュータブル」なので、「=演算子」を使うと参照値(アドレス)だけがコピーされ、中身までは複製されていません。そのため、コピー元の変数が変更されるとコピー先にも影響がおよびます。
一方、辞書オブジェクトのcopy関数を使うと、中身が正確にコピーされるため、コピー元の変数が書き換えられたとしても、コピー先に影響はおよびません。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
d1 = {“バナナ”:198, “りんご”:298, “メロン”:998, “いちご”:598, “ぶどう”:398, “パイナップル”:498}
# 辞書の中身を表示する
print(d1)
# 辞書オブジェクトを「=演算子」でコピーする
d2 = d1
# 辞書オブジェクトを「copy関数」でコピーする
d3 = d1.copy()
# 元の辞書を削除する
d1.clear()
# コピー先の辞書型変数の中身を表示する
print(f”=演算子によるコピー:{d2}”)
print(f”copy関数によるコピー:{d3}”)
//実行結果
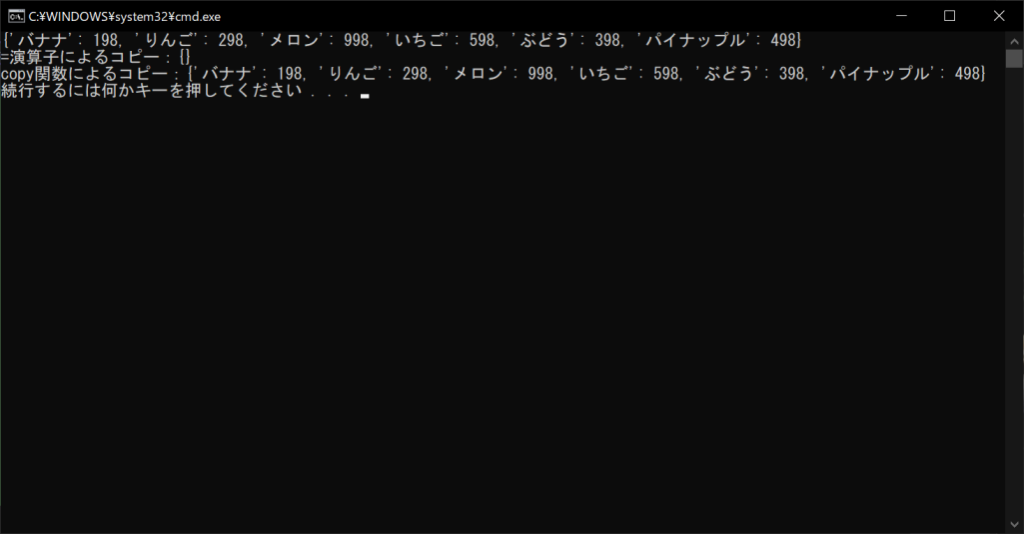
copy関数でコピーしたほうは、コピー元の変数をclear関数で削除しても、コピーした内容が保持されています。ただし、辞書の値がリストなどの「ミュータブルなオブジェクト」である場合は、コピー元が変更されるとその部分に影響が及んでしまいます。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
d1 = {“バナナ”:198, “りんご”:298, “メロン”:[998, 0], “いちご”:598, “ぶどう”:398, “パイナップル”:498}
# 辞書の中身を表示する
print(d1)
# 辞書オブジェクトを「=演算子」でコピーする
d2 = d1
# 辞書オブジェクトを「copy関数」でコピーする
d3 = d1.copy()
# 元の辞書の値を書き換える
d1[“バナナ”] = -1
# 元の辞書のリスト部分の値を書き換える
d1[“メロン”][0] = -1
d1[“メロン”][1] = -1
# コピー先の辞書型変数の中身を表示する
print(f”=演算子によるコピー:{d2}”)
print(f”copy関数によるコピー:{d3}”)
//実行結果
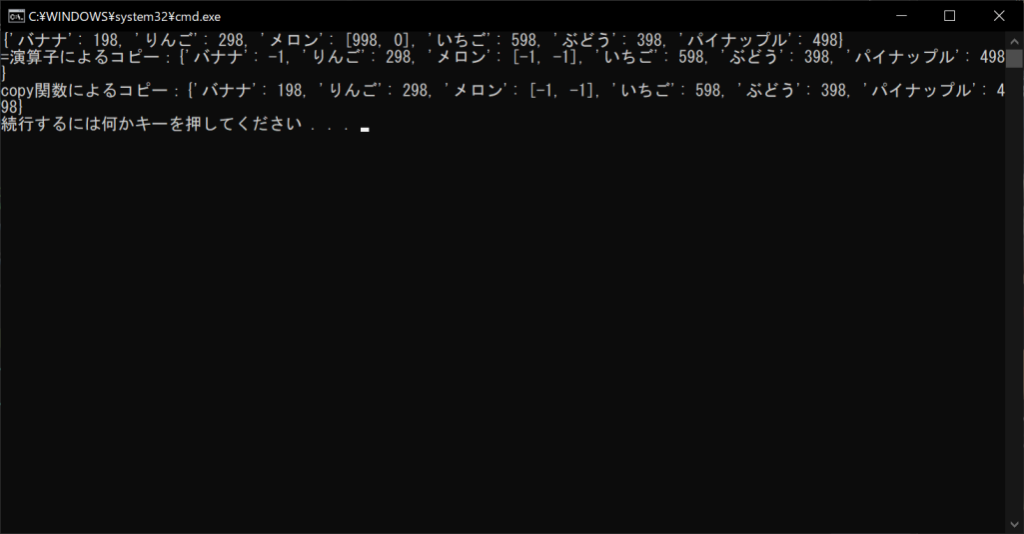
上記のように、辞書の値がイミュータブルである「バナナ」の値は、copy関数を使用すると変更の影響を受けません。しかし、ミュータブルなリストである「メロン」の値は、copy関数を使用しても影響されます。これを防ぐためには、以下のように「copy.deepcopy関数」が必要です。
//サンプルプログラム
# coding: Shift-JIS
# copyライブラリを使用する
import copy
# 辞書オブジェクトを生成する
d1 = {“バナナ”:198, “りんご”:298, “メロン”:[998, 0], “いちご”:598, “ぶどう”:398, “パイナップル”:498}
# 辞書の中身を表示する
print(d1)
# 辞書オブジェクトを「copy関数」でコピーする
d2 = d1.copy()
# 辞書オブジェクトを「copy.deepcopy関数」でコピーする
d3 = copy.deepcopy(d1)
# 元の辞書の値を書き換える
d1[“バナナ”] = -1
# 元の辞書のリスト部分の値を書き換える
d1[“メロン”][0] = -1
d1[“メロン”][1] = -1
# コピー先の辞書型変数の中身を表示する
print(f”copy関数によるコピー:{d2}”)
print(f”copy.deepcopy関数によるコピー:{d3}”)
//実行結果
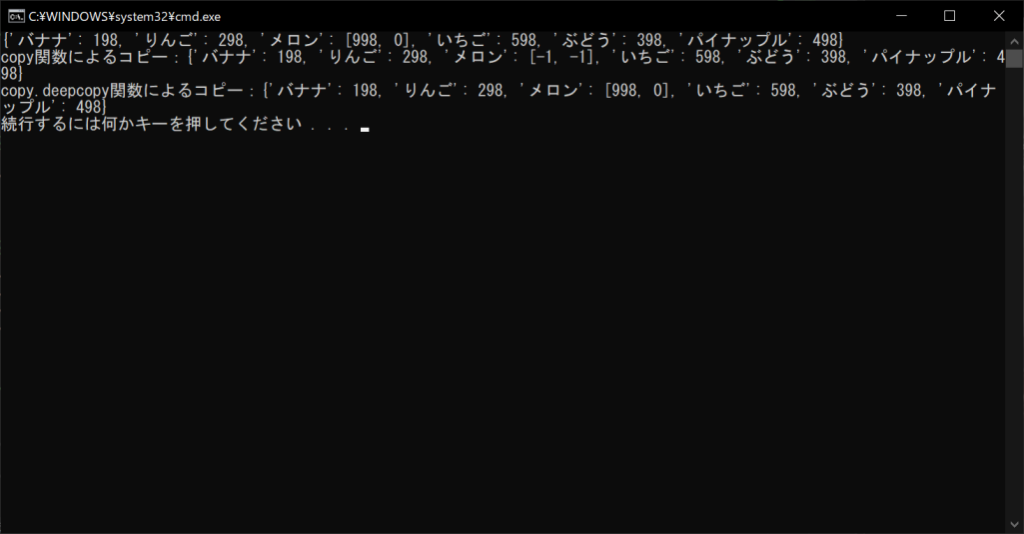
このように、copy.deepcopy関数を使用すると、辞書の値がミュータブルな場合でも安心です。ただし、辞書の値がイミュータブルな場合は、通常のcopy関数で十分です。なお、copy.deepcopy関数の使用時は、「copyライブラリ」をインポートする必要があります。
dict.fromkeys関数|辞書オブジェクトのキーだけコピーする
「dict.fromkeys関数」を使うと、辞書オブジェクトのキーだけコピーできます。dict.fromkeys関数の構文は以下のとおりです。
辞書オブジェクトのデータを取得したいものの、値は不要だという場合は、このdict.fromkeys関数が便利です。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
original = {“バナナ”:198, “りんご”:298, “メロン”:998, “いちご”:598, “ぶどう”:398, “パイナップル”:498}
# 辞書の中身を表示する
print(f”コピー元{original}”)
# 辞書オブジェクトのキーのみをdict.fromkeys関数で取得する
copy = dict.fromkeys(original)
# コピー先の辞書型変数の中身を表示する
print(f”コピー先{copy}”)
//実行結果
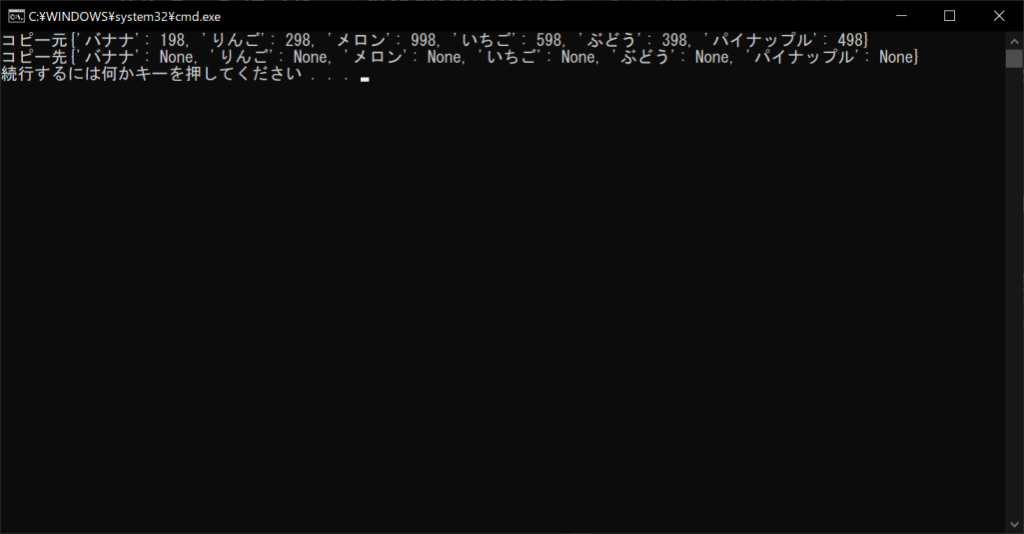
Pythonの辞書オブジェクトで便利な演算子

Pythonの辞書オブジェクトを使用するときは、以下のような演算子も知っておくと便利です。
- in演算子|キーや値が存在するか確認する
- del演算子|複数の要素をまとめて削除する
in演算子|キーや値が存在するか確認する
以下の構文で「in演算子」を使うと、そのキーが辞書型変数に存在するかどうか、その結果をTrueもしくはFalseで取得できます。
特定の値が存在するかどうかを調べたい場合は、以下のようにvalues関数を実行して値の一覧を取得し、in演算子を使いましょう。なお、values関数については前述したとおりです。
実際に、in演算子を使ってキーや値が存在するかどうかを調べる手順を、以下のサンプルコードで確認しましょう。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products = {“バナナ”:198, “りんご”:298, “メロン”:998, “いちご”:598, “ぶどう”:398, “パイナップル”:498}
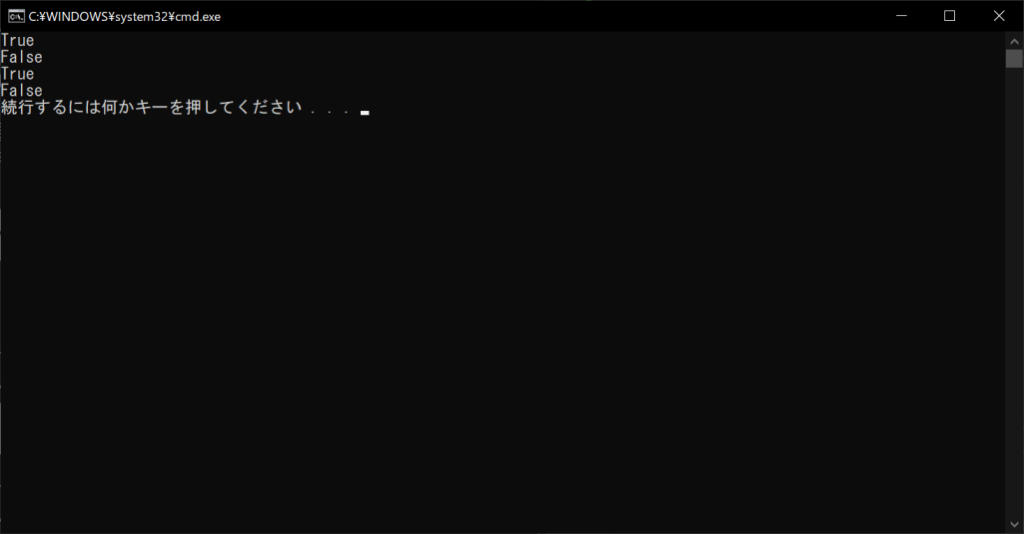
# 「バナナ」キーが存在するか調べる
print(“バナナ” in products)
# 「チョコレート」キーが存在するか調べる
print(“チョコレート” in products)
# 値の一覧を取得する
values = products.values()
# 「バナナ」キーが存在するか調べる
print(998 in values)
# 「チョコレート」キーが存在するか調べる
print(777 in values)
//実行結果
del演算子|複数の要素をまとめて削除する
前述したpop関数やpopitem関数は、一度に1個の要素しか削除できませんが、「del演算子」を使うことで複数まとめて削除できます。
上記のように、「[]演算子」でキーを指定する記述を「,」で並べることで、複数の要素を削除できます。ただし、辞書に含まれていないキーを指定するとエラーが出るので注意が必要です。
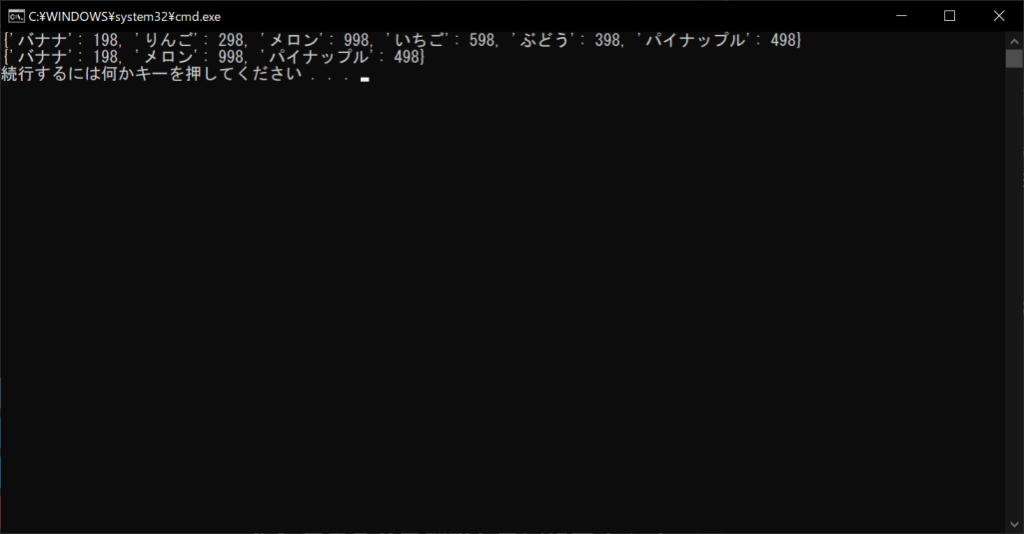
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products = {“バナナ”:198, “りんご”:298, “メロン”:998, “いちご”:598, “ぶどう”:398, “パイナップル”:498}
# 辞書の中身を表示する
print(products)
# 複数の要素をまとめて削除する
del products[“りんご”], products[“いちご”], products[“ぶどう”]
# 辞書の中身を表示する
print(products)
//実行結果
Pythonの辞書オブジェクトをソートする方法

Pythonの辞書オブジェクトのキーと値をソートしたい場合は、「sorted関数」を使いましょう。ただし、辞書オブジェクトのままではソートできないので、戻り値は「リスト」になります。
-
- sorted関数でキーをソートしてリスト化する
- sorted関数で値をソートしてリスト化する
- sorted関数でキーと値をソートしてリスト化する
sorted関数でキーをソートしてリスト化する
sorted関数を使用して、辞書オブジェクトのキーをソートする手順は以下のとおりです。
ソート結果はリスト形式で返ります。詳細をサンプルコードで確認しましょう。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products = {“バナナ”:198, “りんご”:298, “メロン”:998, “いちご”:598, “ぶどう”:398, “パイナップル”:498}
# 辞書の中身を表示する
print(products)
# 辞書オブジェクトのキーをソートする
sorted_keys = sorted(products.keys())
# ソート結果を表示する
print(sorted_keys)
//実行結果
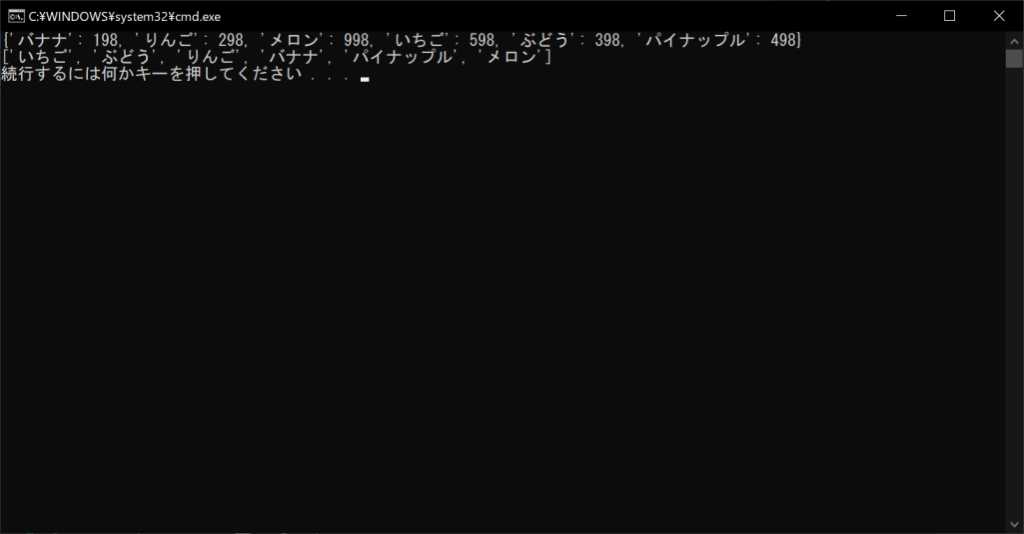
なお、降順ソートにしたい場合は、sorted関数の引数に「reverse = True」を追加しましょう。
sorted関数で値をソートしてリスト化する
sorted関数を使用して、辞書オブジェクトの値をソートする手順は以下のとおりです。
前述したように、ソート結果はリスト形式で返ります。詳細をサンプルコードで確認しましょう。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products = {“バナナ”:198, “りんご”:298, “メロン”:998, “いちご”:598, “ぶどう”:398, “パイナップル”:498}
# 辞書の中身を表示する
print(products)
# 辞書オブジェクトの値をソートする
sorted_keys = sorted(products.values())
# ソート結果を表示する
print(sorted_keys)
//実行結果
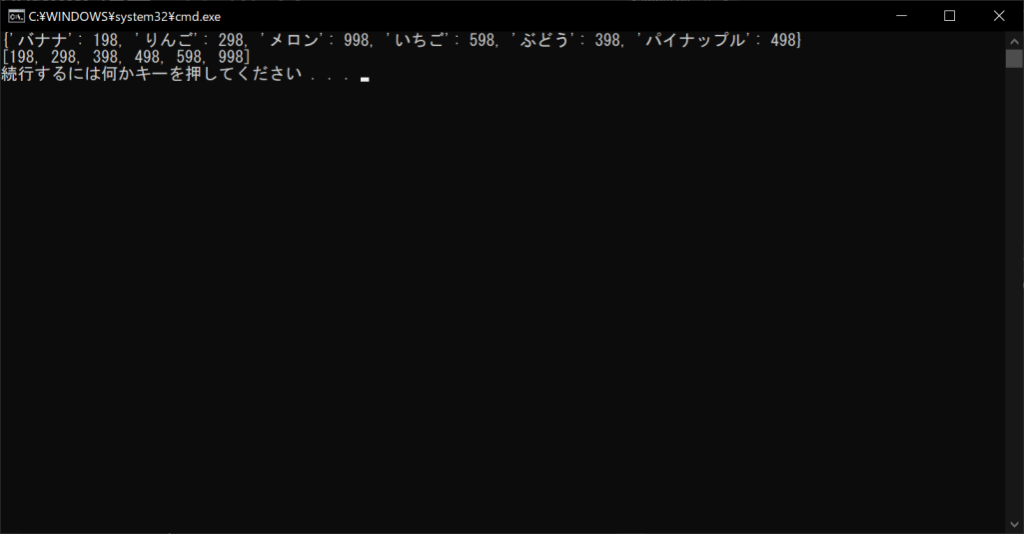
降順ソートにしたい場合は、sorted関数の「reverse引数」にTrueを指定します。
sorted関数でキーと値をソートしてリスト化する
sorted関数を使用して、辞書オブジェクトのキーと値をまとめてソートする手順は以下のとおりです。
ソート結果はリスト形式で返りますが、各要素は「(キー, 値)」というタプル形式となります。詳細をサンプルコードで確認しましょう。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
products = {“バナナ”:198, “りんご”:298, “メロン”:998, “いちご”:598, “ぶどう”:398, “パイナップル”:498}
# 辞書の中身を表示する
print(products)
# 辞書オブジェクトのキーと値をセットでソートする
sorted_keys = sorted(products.items())
# ソート結果を表示する
print(sorted_keys)
//実行結果
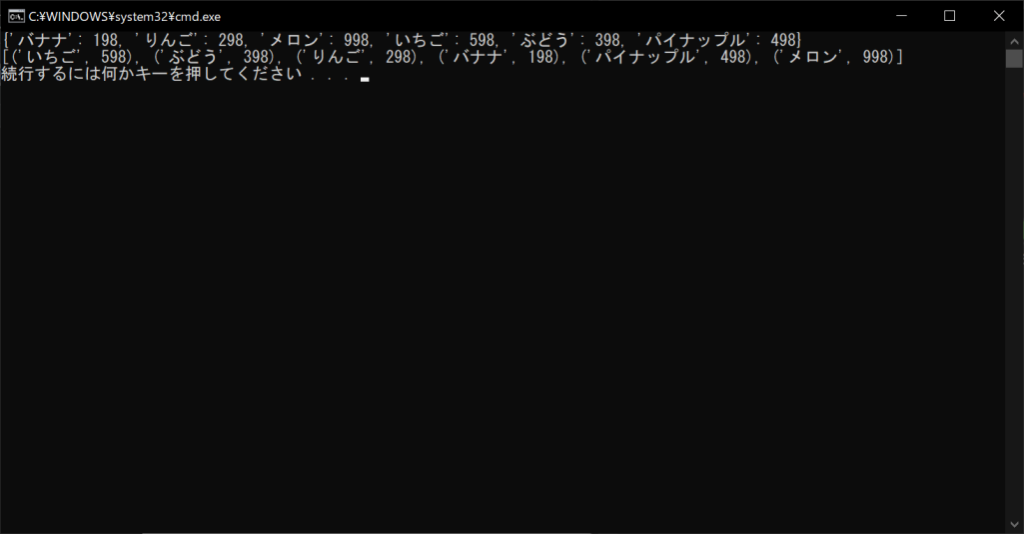
このように、ソート結果はタプルとなり、キーを基準としてソートされます。なお、降順ソートにしたい場合は、こちらもsorted関数の引数に「reverse = True」を追加するとOKです。
辞書の値は「辞書」「リスト」「タプル」を格納できる

辞書オブジェクトの値は、キーとは異なり基本的にどのようなものでもOKです。そのため、値が「辞書」「リスト」「タプル」などでも、問題なく動作します。
//サンプルプログラム
# coding: Shift-JIS
# 辞書オブジェクトを生成する
# 値の中身は「商品コード」「価格」「在庫数」という想定
products = {"バナナ":("A001", 198, 30),
"りんご":("A002", 298, 20),
"メロン":("A003", 998, 3),
"いちご":("B011", 598, 10),
"ぶどう":("B012", 398, 15),
"パイナップル":("C101", 498, 5)}
# 辞書の中身を表示する
print(products)
//実行結果
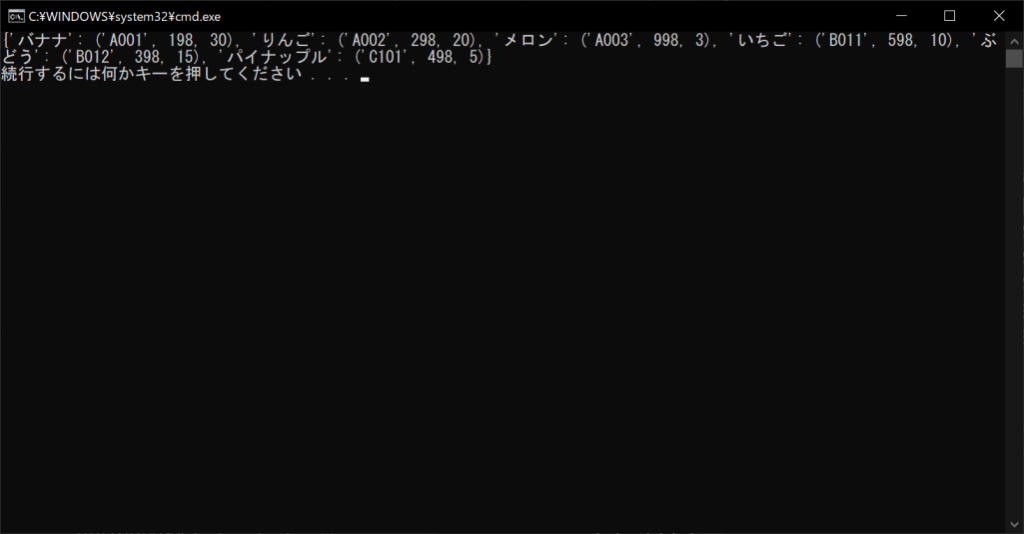
ただし、辞書の値がリストなどミュータブルなオブジェクトである場合は、前述したように「copy関数」の使用時に問題が生じる可能性があります。ミュータブルな値も含めて安全にコピーしたい場合は、「copy.deepcopy関数」を使用しましょう。
【応用編】Pythonの辞書で条件分岐を簡素化できる

Pythonの辞書型は、うまく使えばデータの管理以外に、「条件分岐」の効率化を行うことも可能です。ここでは、以下2つの応用テクニックを紹介します。
-
-
- 辞書を「switch-case文」の代替手段にする
- 辞書を使って「関数呼び出し」を分岐する
-
辞書を「switch-case文」の代替手段にする
Pythonには、C++やJavaなどにある「switch-case文」が使えないので、if文・elif文・else文で分岐するしかありません。たとえば以下のように、対応する値に対応する英単語を表示したい場合は、ひとつずつif文で分岐させないといけないのでソースコードが冗長になります。
//サンプルプログラム
# coding: Shift-JIS
# randomライブラリを使用する
import random
# 0から9の範囲でランダムな整数値を取得して表示する
num = random.randrange(10)
print(num)
# 該当する数値を英語で表示する
if num == 0:
print("zero")
elif num == 1:
print("one")
elif num == 2:
print("two")
elif num == 3:
print("three")
elif num == 4:
print("four")
elif num == 5:
print("five")
elif num == 6:
print("six")
elif num == 7:
print("seven")
elif num == 8:
print("eight")
else:
print("nine")
//実行結果
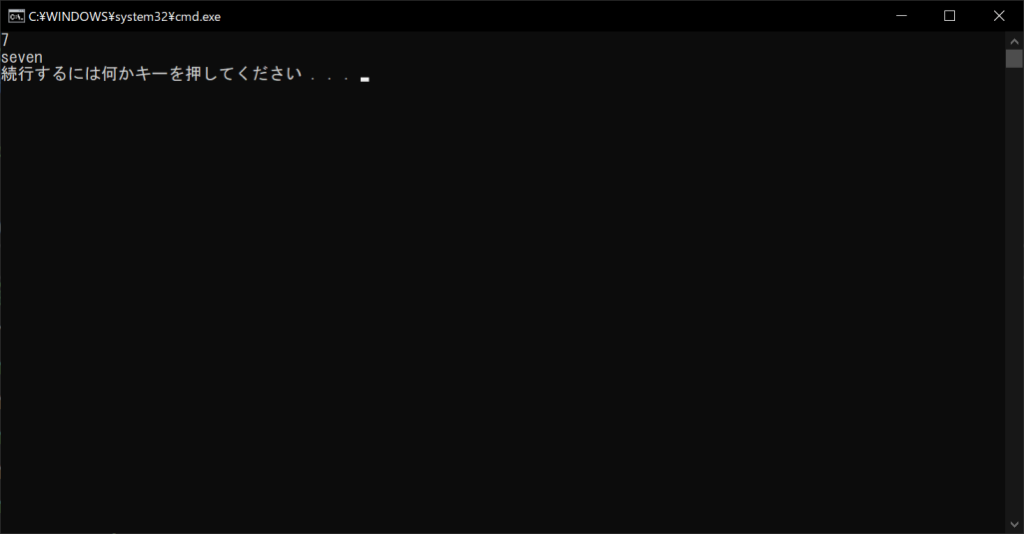
しかし、辞書型をうまく活用すればソースコードを簡潔化できます。具体的には以下のように、if文の条件となる値を「キー」に、処理内容を「値」に設定するだけです。
//サンプルプログラム
# coding: Shift-JIS
# randomライブラリを使用する
import random
# 数値と英語を対応させた辞書オブジェクトを生成する
dictionary = {0:"zero",
1:"one",
2:"two",
3:"three",
4:"four",
5:"five",
6:"six",
7:"seven",
8:"eight",
9:"nine"}
# 0から9の範囲でランダムな整数値を取得して表示する
num = random.randrange(10)
print(num)
# 該当する数値を英語で表示する
print(dictionary[num])
このようにすると、if文を記載することなく、値に応じて自動的に処理を分岐できます。さらに、辞書の内容を追加すれば、より多くのケースにも対応できるので、ソースコードの保守性も格段に高まることが魅力です。
辞書を使って「関数呼び出し」を分岐する
先ほど解説したテクニックを応用すると、関数呼び出しも辞書型で簡潔に分岐できるようになります。たとえば、2つの値を入力したうえで演算方法を選び、その結果を算出するプログラムを考えてみましょう。通常は以下のように、やはりif文で地道に分岐する必要があるので、ソースコードが冗長化してしまいます。
//サンプルプログラム
# coding: Shift-JIS
# reライブラリを使用する
import re
# 足し算を行う関数
def add(a, b):
return a + b
# 引き算を行う関数
def sub(a, b):
return a - b
# 掛け算を行う関数
def mul(a, b):
return a * b
# 割り算を行う関数
def div(a, b):
return a / b
# main関数を定義する
if __name__ == "__main__":
# 2つの数値を格納するためのリスト
nums = [None] * 2
# 2つの数値の入力を受け付ける
for i in range(2):
# 不正入力に対応するために無限ループを回す
while True:
# ユーザーの入力を受け付ける
string = input(f"{i + 1}つ目の数値を入力してください:")
# 正規表現を使って数値のみを抽出する
# 整数値だけではなく浮動小数点値も受け付ける
match = re.search("[+-]?\d+(?:\.\d+)?", string)
# 入力値が正常であれば浮動小数点値に変換する
if match:
nums[i] = float(match.group())
break
# 不正入力に対応するために無限ループを回す
while True:
# 演算モードの入力を受け付ける
mode = input("演算モードを「add」「sub」「mul」「div」から指定してください:")
# 入力値が正常であれば演算へ移る
if mode == "add" or mode == "sub" or mode == "mul" or mode == "div":
break
# モードに応じて呼び出す関数を分岐する
if mode == "add":
print(f"演算結果 = {add(nums[0], nums[1])}")
elif mode == "sub":
print(f"演算結果 = {sub(nums[0], nums[1])}")
elif mode == "mul":
print(f"演算結果 = {mul(nums[0], nums[1])}")
else:
print(f"演算結果 = {div(nums[0], nums[1])}")
//実行結果
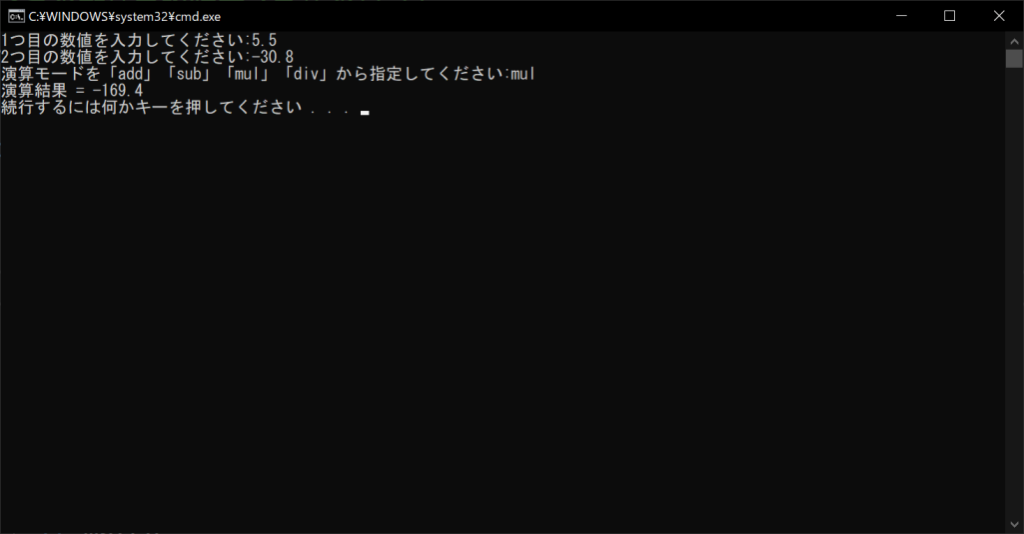
また、本プログラムでは、不整値の入力を防ぐために、reライブラリの「正規表現」を活用しています。正規表現を「[+-]?\d+(?:\.\d+)?」とすることで、整数や浮動小数点値のみを抽出し、不要な文字列を除去できます。今回のように、マイナス値や浮動小数点数も受け付けたい場合は、このように処理するのが現実的です。
上記のソースコードは、関数呼び出しを分岐する部分をif文で分岐させているため冗長です。そのため以下のように、あらかじめ辞書オブジェクトに分岐内容を登録しておくと、ソースコードを簡潔化できます。
//サンプルプログラム
# coding: Shift-JIS
# reライブラリを使用する
import re
# 足し算を行う関数
def add(a, b):
return a + b
# 引き算を行う関数
def sub(a, b):
return a - b
# 掛け算を行う関数
def mul(a, b):
return a * b
# 割り算を行う関数
def div(a, b):
return a / b
# main関数を定義する
if __name__ == "__main__":
# 関数呼び出しを分岐させるための辞書オブジェクトを生成する
functions = {"add":add, "sub":sub, "mul":mul, "div":div}
# 2つの数値を格納するためのリスト
nums = [None] * 2
# 2つの数値の入力を受け付ける
for i in range(2):
# 不正入力に対応するために無限ループを回す
while True:
# ユーザーの入力を受け付ける
string = input(f"{i + 1}つ目の数値を入力してください:")
# 正規表現を使って数値のみを抽出する
# 整数値だけではなく浮動小数点値も受け付ける
match = re.search("[+-]?\d+(?:\.\d+)?", string)
# 入力値が正常であれば浮動小数点値に変換する
if match:
nums[i] = float(match.group())
break
# 不正入力に対応するために無限ループを回す
while True:
# 演算モードの入力を受け付ける
mode = input("演算モードを「add」「sub」「mul」「div」から指定してください:")
# 入力値が正常であれば演算へ移る
if mode in functions:
break
# モードに応じて呼び出す関数を分岐する
print(f"演算結果 = {functions[mode](nums[0], nums[1])}")
演算モードの不正入力検出も、辞書オブジェクトのキーと照らし合わせることで、すぐにチェックできるので便利です。実際に関数を呼び出す部分は、「functions[mode]」と記載するだけで、条件に該当する関数が自動的に選ばれます。
Pythonの辞書型を活用してソースコードを簡潔化しよう!

Pythonの辞書型は、2つの要素を「キー」と「値」としてペアを組めるので、データ同士を関連付けて管理したいときに便利です。組み込みメソッドも豊富で、要素の追加・検索・ソートも簡単に行えます。また、辞書オブジェクトのキーと値をうまく設定すれば、if文の代替として条件分岐を行えるようになり、ソースコードを簡潔化も可能です。











アクセスランキング 人気のある記事をピックアップ!
コードカキタイがオススメする記事!

2024.06.17
子供におすすめのプログラミングスクール10選!学習メリットや教室選びのコツも紹介
#プログラミングスクール

2022.01.06
【完全版】大学生におすすめのプログラミングスクール13選!選ぶコツも詳しく解説
#プログラミングスクール

2024.01.26
【未経験でも転職可】30代におすすめプログラミングスクール8選!
#プログラミングスクール

2024.01.26
初心者必見!独学のJava学習方法とおすすめ本、アプリを詳しく解説
#JAVA

2024.01.26
忙しい社会人におすすめプログラミングスクール15選!失敗しない選び方も詳しく解説
#プログラミングスクール

2022.01.06
【無料あり】大阪のおすすめプログラミングスクール14選!スクール選びのコツも紹介
#プログラミングスクール

2024.01.26
【目的別】東京のおすすめプログラミングスクール20選!スクール選びのコツも徹底解説
#プログラミングスクール

2024.01.26
【無料あり】福岡のおすすめプログラミングスクール13選!選び方も詳しく解説
#プログラミングスクール

2024.01.26
【徹底比較】名古屋のおすすめプログラミングスクール13選!選び方も詳しく解説
#プログラミングスクール

2024.01.26
【徹底比較】おすすめのプログラミングスクール18選!失敗しない選び方も徹底解説
#プログラミングスクール