
Pythonでプログラミングをしていると、「ファイル」を扱いたいときがあるはずです。たとえば、テキストファイルから読み込んだデータを表示したり、データをファイルに書き出したりするなどです。そんなときに必ず使うのが、「open」という関数・メソッドです。
open関数には、ファイル操作の基本となる、「ファイルを開く」という役割があります。ただし、open関数にはさまざまなモード設定があるので、用途に合わせて適切に使うことが大切です。本記事では、Pythonのopen関数の使い方や、重要なポイントなどについて解説します。
目次
Pythonの「open」とは?ファイル操作に必須の関数・メソッド

Pythonの「open」は、ファイルを開くための関数・メソッドです。どのような種類のファイルであっても、Pythonでファイルを操作するときは、基本的にこのopen関数を使います。
「ファイルを開く」というと、「読み込み専用」のように感じるかもしれません。しかし、ファイルを「書き出す」ときも、最初にファイルを作成する必要があり、そのときにファイルオープンという動作は必須です。
つまりPythonのopenは、ファイルを読み込んだり、書き出したりするときに、欠かせない関数・メソッドだということです。これは、「テキストファイル」や「バイナリファイル」といった、ファイルの種類に関わらず当てはまります。
「テキストファイル」と「バイナリファイル」の違い
ファイルには、大きく分けて「テキストファイル」と「バイナリファイル」の2種類があります。テキストファイルはデータを「文字」として扱い、バイナリファイルはデータを「2進数の羅列」として扱うことが大きな違いです。
テキストファイルの代表例は、Windowsの「メモ帳」です。メモ帳は、テキストを入力・保存するためのソフトウェアで、扱うファイル形式はテキストファイルとなります。しかしテキストファイルは、一般的にあまり採用されていません。
バイナリファイルは、画像ファイルや音楽ファイルなど、さまざまな場面で活用されています。アプリケーションの実行ファイルやPDFファイルなども、バイナリファイルです。Pythonのopen関数は、いずれのファイルを開く場合も使用します。
Pythonの「open関数」の基本的な使い方

Pythonのopen関数・メソッドの基本的な使い方について、以下3つのステップに分けて解説します。
- open関数の最も単純な構文と使い方
- open関数の「モード」でファイルオブジェクトの機能が変わる
- 文字コードを「utf-8」に設定する
open関数の最も単純な構文と使い方
open関数にはさまざまな引数がありますが、最も単純な構文は以下のとおりです。
上記の構文でopen関数を使用すると、「テキストファイル」を読み込むことができます。実際に以下のサンプルコードで、適当なテキストファイルを開いてみましょう。Pythonのプロジェクトフォルダに、「Sample.txt」というファイルを作成し、以下のプログラムを実行してみてください。
//サンプルプログラム
# coding: Shift_JIS
# テキストファイルを開く
f = open("Sample.txt")
# ファイルオブジェクトが有効であればメッセージを表示する
if f:
print("ファイルオープンに成功しました!")
# 最後にファイルをクローズする
f.close()
//実行結果
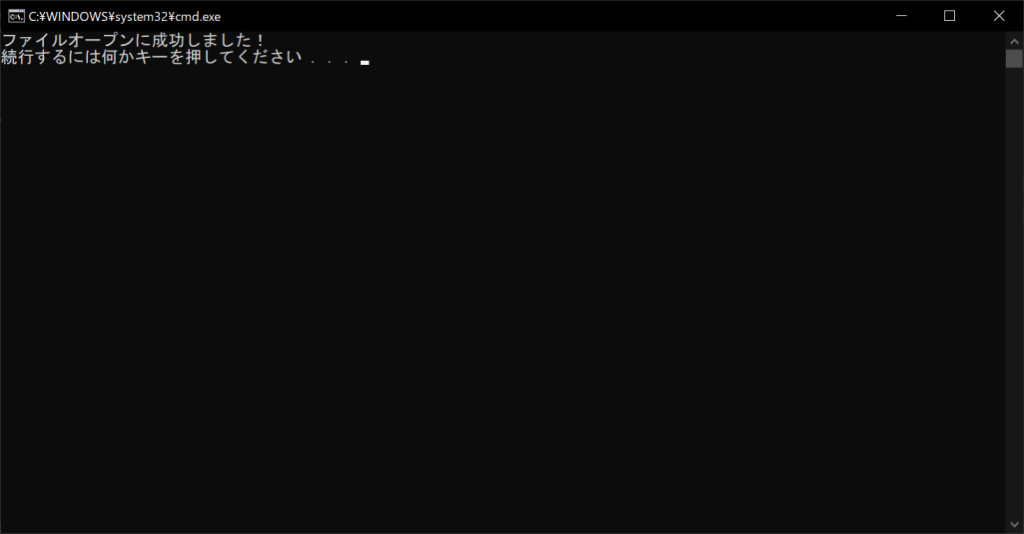
なお、ファイルを開いたときは、プログラムを終了する前に「close関数」でファイルをクローズする必要があります。close関数の使い方は以下のとおりです。
close関数を書き忘れたとしても、プログラムが終了すると自動的にクローズされます。しかし、プログラム実行中にほかの場所からファイルを開けなくなるので、たとえば大規模プロジェクトでさまざまな場所から同じファイルにアクセスする場合に、問題になる可能性があるので注意が必要です。
そのため、基本的にはopen関数とclose関数は、セットで使うことを意識しましょう。なお、close関数を省略できるようにする方法については、のちほど紹介します。
open関数の「モード」でファイルオブジェクトの機能が変わる
open関数は、ファイルパスさえ指定すれば使えますが、以下のようにファイルオープンの「モード」を指定することもできます。
モードには、ファイルオブジェクトの「機能」を指定するものと、開くファイルの「種類」を指定するものがあります。機能を指定するモードは以下のとおりです。
| モード | 概要 |
|---|---|
| r | 読み込み用にファイル開く |
| w | 書き込み用にファイルを新規作成する |
| a | 追記用にファイルを開く |
| r+ | 既存ファイルを読み込んだあと、データの書き込みも行える |
| w+ | 既存ファイルを読み込んだあと、データをすべて消去してから書き込む |
| a+ | 既存ファイルを読み込んだあと、データ末尾から追記する |
| x | 既存ファイルが存在しない場合に限り、ファイルを新規作成して書き込む |
詳細は後述しますが、どのモードを選ぶかによって、使える関数・メソッドや既存ファイルの扱い方などが異なります。また、ファイルの種類を指定するモードは、以下のとおりです。
| モード | 概要 |
|---|---|
| t | テキストファイル |
| b | バイナリファイル |
上記の機能とファイルのモードは、基本的にいずれか1つずつを組み合わせて使います。たとえば、テキストファイルを書き込む場合は「w」と「t」を組み合わせて「wt」となります。ただしデフォルト設定は、機能を指定するモードが「r」で、ファイルの種類を指定するモードは「t」なので、読み込み・テキストファイルの指定は省略できます。
文字コードを「utf-8」に設定する
モード以外に重要なことが、「文字コード」の設定です。文字コードとは、各文字に割り当てられるバイト(16進数)の表現方法を差し、さまざまな種類があります。Pythonのopen関数を使用する際は、基本的に以下のように「encoding = “utf-8″」を指定することが必須です。
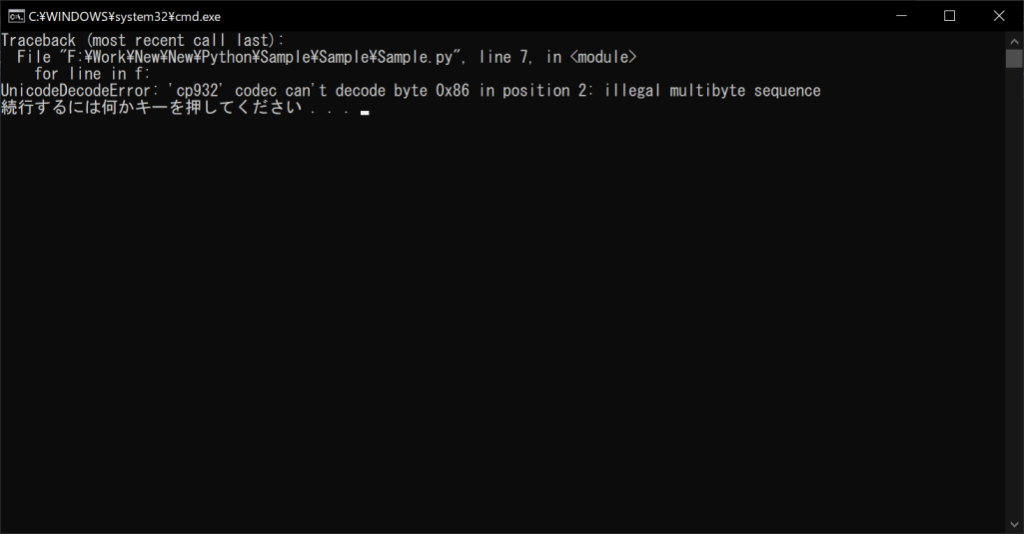
「utf-8」は、現在ほとんどの環境で使用されている文字コードであり、英数字はもちろん日本語や中国語などの「マルチバイト文字」も扱えます。しかし、Windowsの日本語環境では、「cp932」つまりShift_JISが標準形式となっているため、テキストファイルの「utf-8」形式との不整合が生じます。たとえば、適当なテキストファイルを以下のソースコードで表示しようとすると、「UnicodeDecodeError」というエラーが出ます。
//サンプルプログラム
# coding: Shift_JIS
# テキストファイルを開く
f = open("Sample.txt", "r")
# 読み込んだテキストファイルを1行ずつ表示する
for line in f:
print(line)
# 最後にファイルをクローズする
f.close()
//実行結果
一方で、open関数に「encoding = “utf-8″」という記載を追加することで、テキストファイルを問題なく表示できます。
//サンプルプログラム
# coding: Shift_JIS
# テキストファイルを開く
f = open("Sample.txt", "r", encoding = "utf-8")
# 読み込んだテキストファイルを1行ずつ表示する
for line in f:
print(line, end = "")
print()
# 最後にファイルをクローズする
f.close()
この「encoding」は、多くのサンプルコードでは省略されていますが、日本語環境でPythonプログラミングをする場合は必須といっても過言ではありません。以上のことから、Pythonのopen関数・メソッドを使用する際は、「ファイルパス」「モード」「文字コード」の3つを引数で指定する必要があることがわかりました。
open関数・メソッドでテキストファイルを読み込む方法

open関数・メソッドでテキストファイルを読み込む方法について、以下2つの観点から解説します。
- テキストファイルを1行ずつ読み込んで表示する
- テキストファイルをまとめて読み込んで表示する
まずは「メモ帳」を開き、Pythonのプロジェクトフォルダに以下のテキストを「Sample.txt」という名前で保存してから、サンプルコードを実行してください。
//Sample.txt
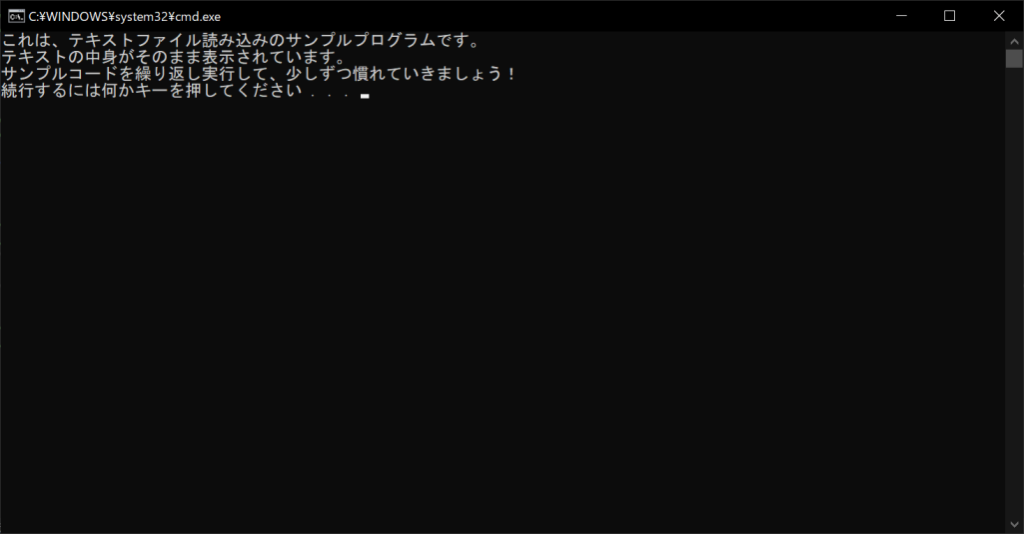
これは、テキストファイル読み込みのサンプルプログラムです。
テキストの中身がそのまま表示されています。
サンプルコードを繰り返し実行して、少しずつ慣れていきましょう!
テキストファイルを1行ずつ読み込んで表示する
Pythonのopen関数・メソッドで、先ほどのテキストファイルを読み込んで表示してみましょう。以下のようにforループを回すことで、テキストファイルを1行ずつ処理できます。
forループの「イテラブルオブジェクト」に、open関数の戻り値として受け取るファイルオブジェクトを指定すると、自動的に1行ずつ読み込むことができます。これを利用して、テキストファイルの中身を表示するプログラムは以下のとおりです。
//サンプルプログラム
# coding: Shift_JIS
# テキストファイルを開く
f = open("Sample.txt", "r", encoding = "utf-8")
# 読み込んだテキストファイルを1行ずつ表示する
for line in f:
print(line, end = "")
print()
# 最後にファイルをクローズする
f.close()
//実行結果
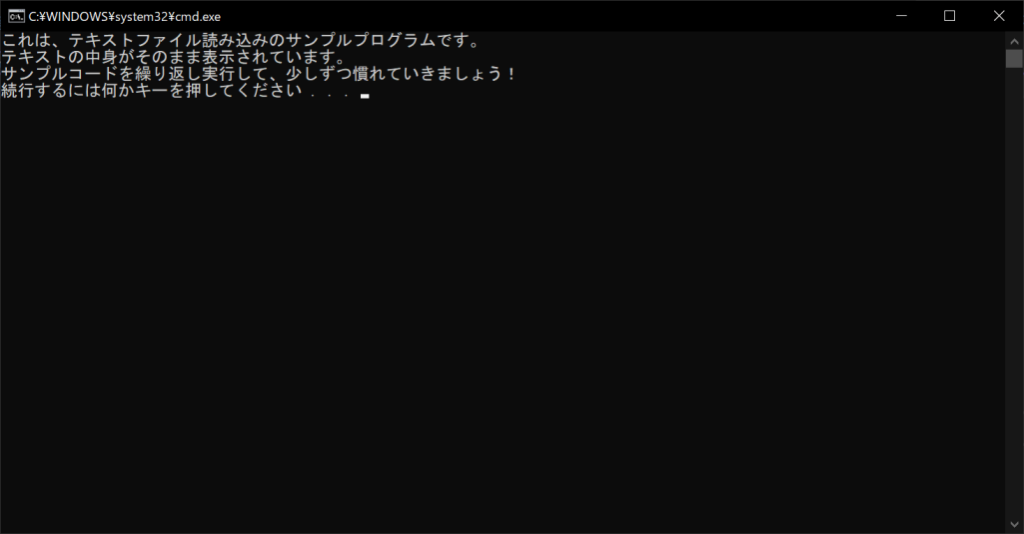
通常、print関数は自動的に改行を挟みますが、テキストファイル自体に改行が含まれているため、そのままでは余分な改行が入ってしまいます。そのため、print関数の「end」引数に、空文字を指定していることがポイントです。なお、「readline関数」を使うことでも、同じ結果が得られます。
//サンプルプログラム
# coding: Shift_JIS
# テキストファイルを開く
f = open("Sample.txt", "r", encoding = "utf-8")
# ファイル終端に達するまで、while文で読み込み続ける
while True:
# 1行分のテキストを読み込む
line = f.readline()
# ファイル終端に達していなければ中身を表示し、終端であればループを抜ける
if line:
print(line, end = "")
else:
break;
print()
# 最後にファイルをクローズする
f.close()
テキストファイルをまとめて読み込んで表示する
「readlines関数」や「read関数」を使うと、テキストファイルをまとめて読み込むことができます。readlines関数は、テキストを行単位でリストに格納するためのメソッドです。
//サンプルプログラム
# coding: Shift_JIS
# テキストファイルを開く
f = open("Sample.txt", "r", encoding = "utf-8")
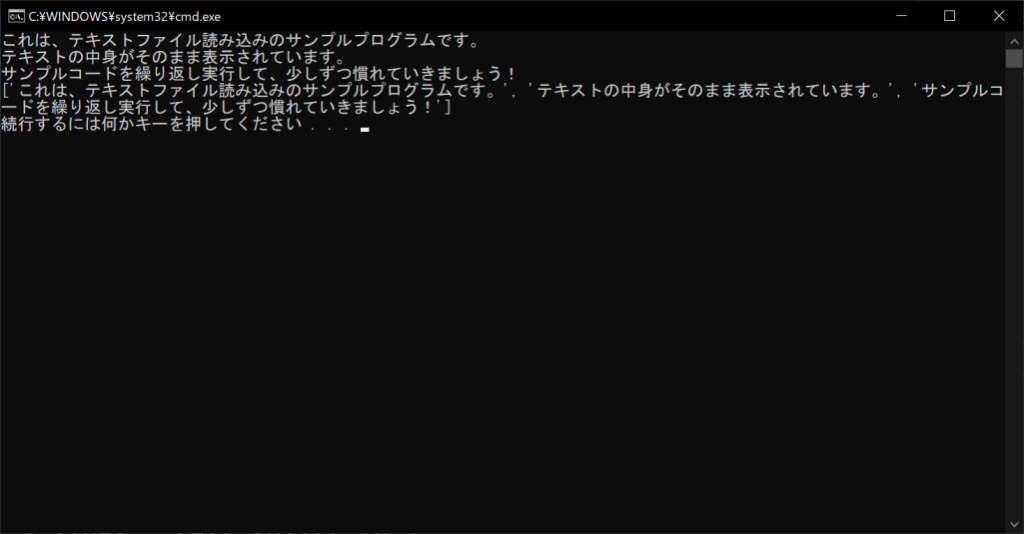
# テキストファイルの中身をまとめて読み込んでリストに格納する
lines = f.readlines()
# すべての行を表示する
print(lines)
# 最後にファイルをクローズする
f.close()
//実行結果
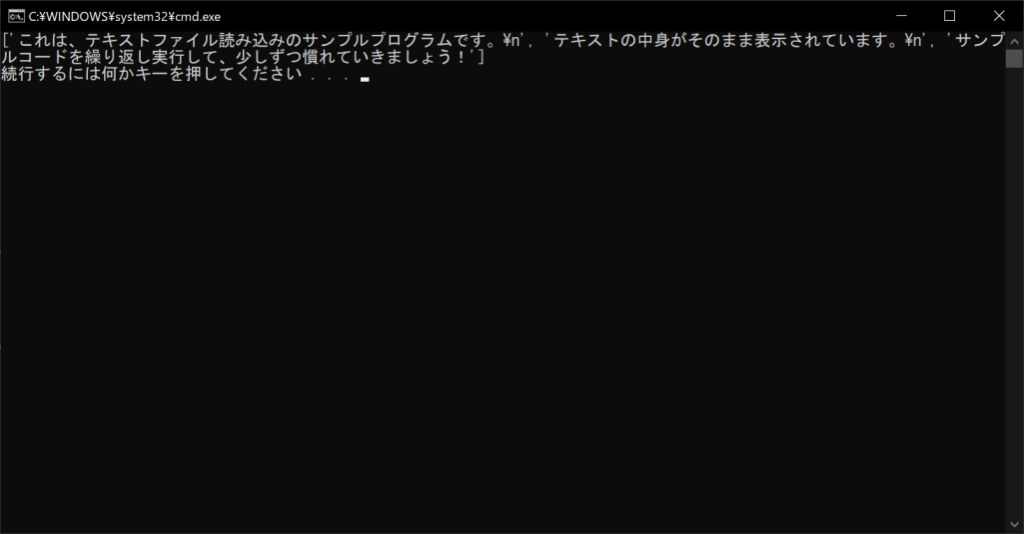
上記のように、readlines関数を使うと、すべての行が個別にリストの要素として格納されます。なお、各行の末尾にある「\n」は「改行コード」です。print関数で1行ずつ表示するときに余計な改行が挟まれるのは、このように各行の末尾に改行コードがあるからです。
一方で、read関数を使えば、以下のようにすべてのデータを文字列形式で一気に取得することができます。
//サンプルプログラム
# coding: Shift_JIS
# テキストファイルを開く
f = open("Sample.txt", "r", encoding = "utf-8")
# テキストファイルの中身をまとめて読み込む
text = f.read()
# すべての行を表示する
print(text)
# 最後にファイルをクローズする
f.close()
//実行結果
これまでに紹介した手法の中では、最も簡潔でわかりやすいのではないでしょうか。ちなみに、read関数でまとめて読み込んだあとに、行ごとに分割して格納したい場合は、以下のように「split関数」の引数に「\n」を渡せばOKです。
//サンプルプログラム
# coding: Shift_JIS
# osライブラリを使用する
import os
# テキストファイルを開く
f = open("Sample.txt", "r", encoding = "utf-8")
# テキストファイルの中身をまとめて読み込む
text = f.read()
# すべての行を表示する
print(text)
# 最後にファイルをクローズする
f.close()
# 改行コード「\n」を区切り文字として、行ごとにリストに格納する
lines = text.split("\n")
# 各行を表示する
print(lines)
//実行結果
open関数・メソッドでテキストファイルを書き出す方法

前述したように、open関数のモードを「w」にすると、書き込み用にファイルを開くことができます。open関数・メソッドでテキストファイルを書き出す方法を、以下3つご紹介します。
- 文字列をまとめてテキストファイルに書き出す
- 文字列のリストをテキストファイルに書き出す
- ファイルが存在しない場合のみ書き込む
文字列をまとめてテキストファイルに書き出す
文字列変数を作成し、それを「write関数」の引数に指定すると、テキストファイルにすべての文字列を書き出すことができます。詳細を以下のサンプルコードで確認しましょう。
//サンプルプログラム
# coding: Shift_JIS
# osライブラリを使用する
import os
# 適当な文章を作成する
text = “吾輩は猫である。名前はまだ無い。\n”\
“どこで生れたかとんと見当がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。しかもあとで聞くとそれは書生という人間中で一番獰悪な種族であったそうだ。\n”\
“この書生というのは時々我々を捕えて煮て食うという話である。しかしその当時は何という考もなかったから別段恐しいとも思わなかった。\n”
# テキストファイルを開く
f = open(“Test.txt”, “w”, encoding = “utf-8”)
# テキストファイルに文字列をまとめて書き込む
f.write(text)
# 最後にファイルをクローズする
f.close()
//実行結果
以下のようなテキストファイルが作成されます
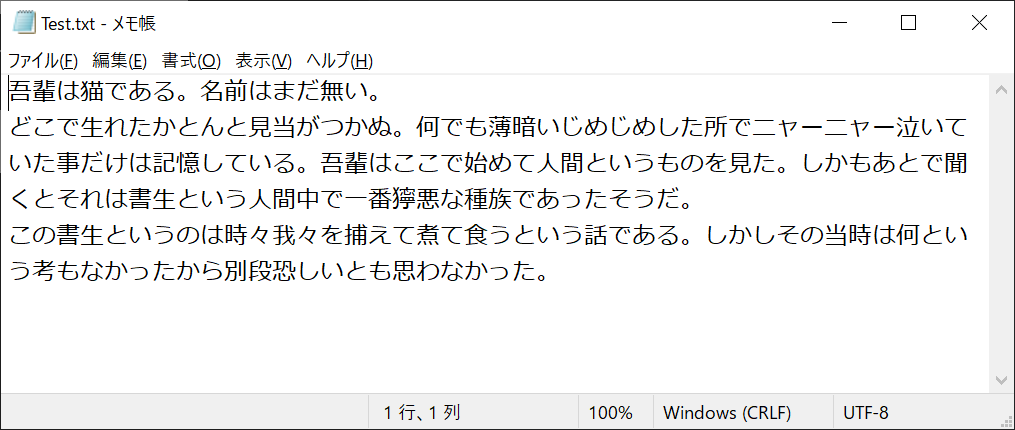
改行コードもそのまま出力されるので、テキストエディタで開いた場合も、上記のように整った状態で表示されます。テキストデータを書き出すときは、write関数を活用するのが最も簡単です。
文字列のリストをテキストファイルに書き出す
文字列リストを出力したい場合は、「writelines関数」でまとめて書き出すことができます。
//サンプルプログラム
# coding: Shift_JIS
# osライブラリを使用する
import os
# 適当な文字列リストを作成する
foods = ["ハンバーガー", "フライドポテト", "ラーメン", "寿司", "鰻重", "チョコレート"]
# テキストファイルを開く
f = open("Foods.txt", "w", encoding = "utf-8")
# テキストファイルに文字列リストを書き込む
f.writelines(foods)
# 最後にファイルをクローズする
f.close()
//実行結果
以下のようなテキストファイルが作成されます
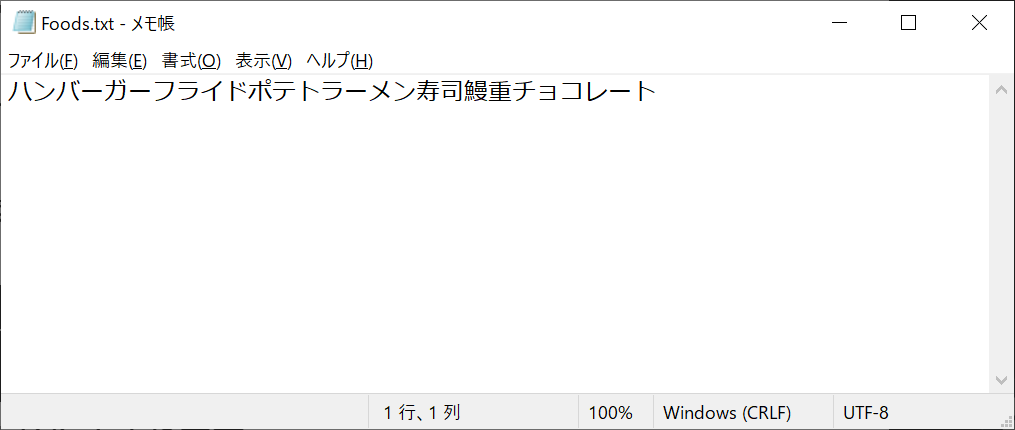
しかし、writelines関数では改行コードが出力されないため、上記のようにすべてがつながってしまいます。これを防ぐためには、「”\n”.join(文字列リスト)」として、改行コードが入ったリストを作成する必要があります。
//サンプルプログラム
# coding: Shift_JIS
# osライブラリを使用する
import os
# 適当な文字列リストを作成する
foods = ["ハンバーガー", "フライドポテト", "ラーメン", "寿司", "鰻重", "チョコレート"]
# テキストファイルを開く
f = open("Foods.txt", "w", encoding = "utf-8")
# 要素ごとに改行コードを挟み、テキストファイルに文字列リストを書き込む
f.write("\n".join(foods))
# 最後にファイルをクローズする
f.close()
//実行結果
以下のようなテキストファイルが作成されます
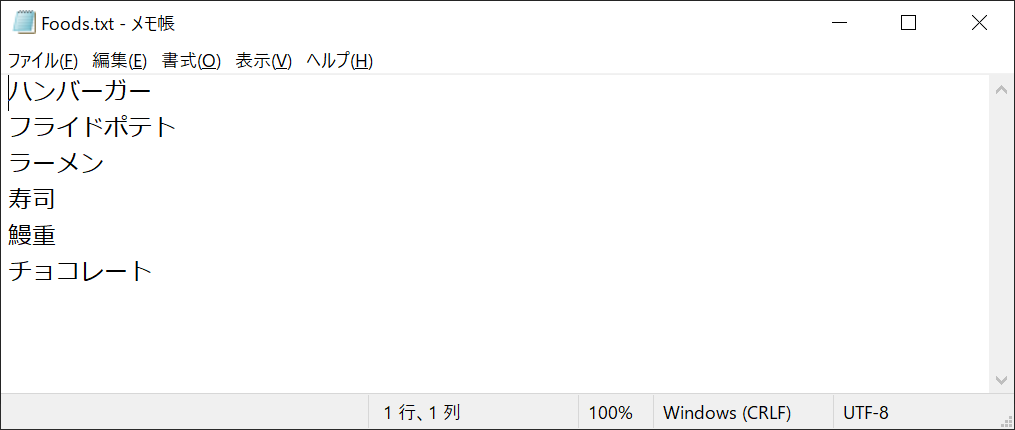
以上のように、個別に改行コードを挟むことで、リスト形式の出力でも見やすいテキストファイルを作成できます。
ファイルが存在しない場合のみ書き込む
前述した「w」モードでは、既存ファイルを上書きしてしまうため、必要なデータを消去してしまうなどトラブルの原因になることがあります。そのため、既存ファイルを変更したくない場合は、以下のように「x」モードでファイルを開くのが安全です。
//サンプルプログラム
# coding: Shift_JIS
# osライブラリを使用する
import os
# 既存のテキストファイルを開こうとする
f = open("Sample.txt", "x", encoding = "utf-8")
//実行結果
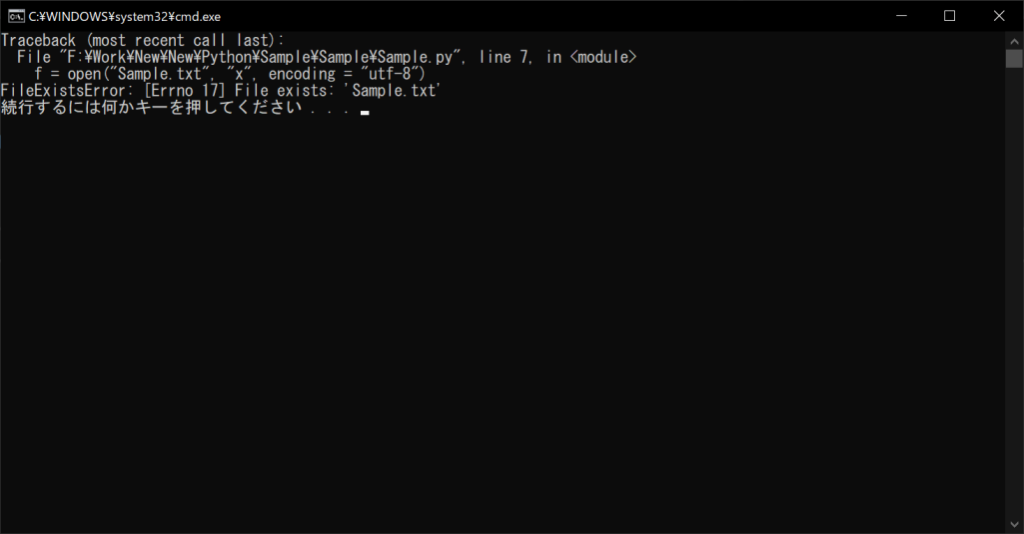
存在するファイルをopen関数で指定した場合は、上記のようにエラーが出ます。一方、存在しないファイルを指定した場合は、「w」モードと同じくファイルを新規作成できます。
open関数・メソッドでテキストファイルに追記する方法

前述したように、open関数のモードを追記モードにすると、既存ファイルにデータを追記できます。ただし、モードによって「どこから追記できるか」など挙動に違いがあるので、目的に応じて使い分けることが大切です。ここでは、以下2つのパターンに分けて追記方法を解説します。
- 既存ファイルの末尾にテキストを追記する
- 既存ファイルの任意の位置にテキストを追記する
既存ファイルの末尾にテキストを追記する
open関数のモードを「a」にすると、追記モードでファイルを開くことができます。そのうえで、write関数やwritelines関数で書き込むと既存ファイルの末尾に追記でき、既存データは上書きされません。「a」モードでの追記方法を以下のサンプルコードで確認しましょう。
//サンプルプログラム
# coding: Shift_JIS
# osライブラリを使用する
import os
# 適当な文章を作成する
text = “吾輩は猫である。名前はまだ無い。\n”\
“どこで生れたかとんと見当がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。しかもあとで聞くとそれは書生という人間中で一番獰悪な種族であったそうだ。\n”\
“この書生というのは時々我々を捕えて煮て食うという話である。しかしその当時は何という考もなかったから別段恐しいとも思わなかった。\n”
# テキストファイルを「書き込みモード」で開く
f = open(“Test.txt”, “w”, encoding = “utf-8”)
# テキストファイルに文字列をまとめて書き込む
f.write(text)
# 最後にファイルをクローズする
f.close()
# 適当な文章を作成する
text = “\nただ彼の掌に載せられてスーと持ち上げられた時何だかフワフワした感じがあったばかりである。掌の上で少し落ちついて書生の顔を見たのがいわゆる人間というものの見始であろう。”\
“この時妙なものだと思った感じが今でも残っている。第一毛をもって装飾されべきはずの顔がつるつるしてまるで薬缶だ。”
# テキストファイルを「追記モード」で開く
f = open(“Test.txt”, “a”, encoding = “utf-8”)
# テキストファイルに文字列をまとめて書き込む
f.write(text)
# 最後にファイルをクローズする
f.close()
//実行結果
以下のようなテキストファイルが作成されます
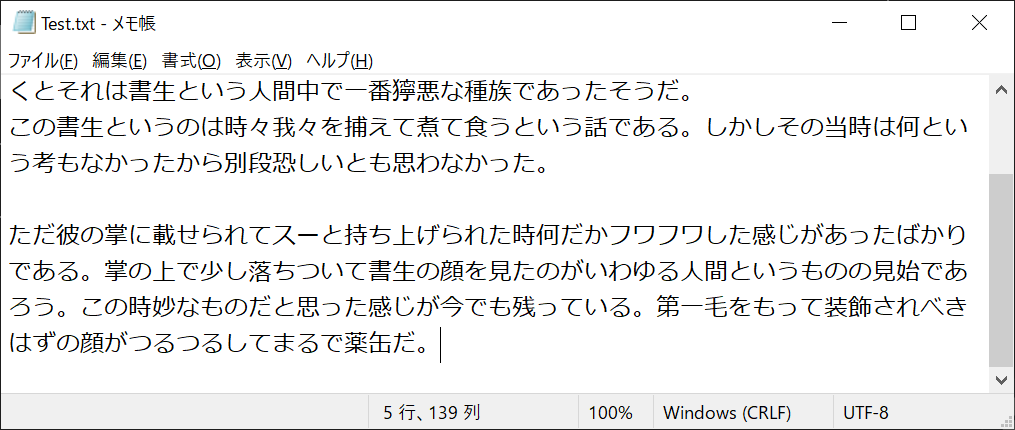
このように、一度ファイルを作成して閉じたあと、モードを「a」にして開くと、既存ファイルの最後から追記できます。後半のモードを「w」にしてみると、前半の文章は削除されて、後半の文章しか残らないことがわかります。
ちなみに、存在しないファイルに対して「a」モードで開くと、「w」モードと同じようにファイルが新規作成されるので、エラーにはなりません。
既存ファイルの任意の位置にテキストを追記する
既存ファイルの任意の位置にテキストを追記する場合は、以下の手順で進める必要があります。
- ファイルのすべての行をリスト形式で読み込む
- 任意の行に該当する部分にテキストを挿入する
- ファイルを新規作成し文字列リストを書き出す
ランダムアクセスができる「seek関数」を使用して、任意の位置に書き込むという手段も考えられます。しかし、seek関数で追記位置を指定したとしても、以下のように上書きされてしまいます。これは、単にファイルポインタの位置を動かして、そのまま書き込んでいるだけだからです。
//サンプルプログラム
# coding: Shift_JIS
# osライブラリを使用する
import os
# 適当な文章を作成する
text = "abcdef"
# テキストファイルを「書き込みモード」で開く
f = open("Test.txt", "w", encoding = "utf-8")
# テキストファイルに文字列をまとめて書き込む
f.write(text)
# 最後にファイルをクローズする
f.close()
# 適当な文章を作成する
text = "uvwxyz"
# テキストファイルを「追記モード」で開く
f = open("Test.txt", "r+", encoding = "utf-8")
# テキストファイルに文字列をまとめて書き込む
f.seek(0, os.SEEK_SET)
f.write(text)
# 最後にファイルをクローズする
f.close()
//実行結果
以下のようなテキストファイルが作成されます
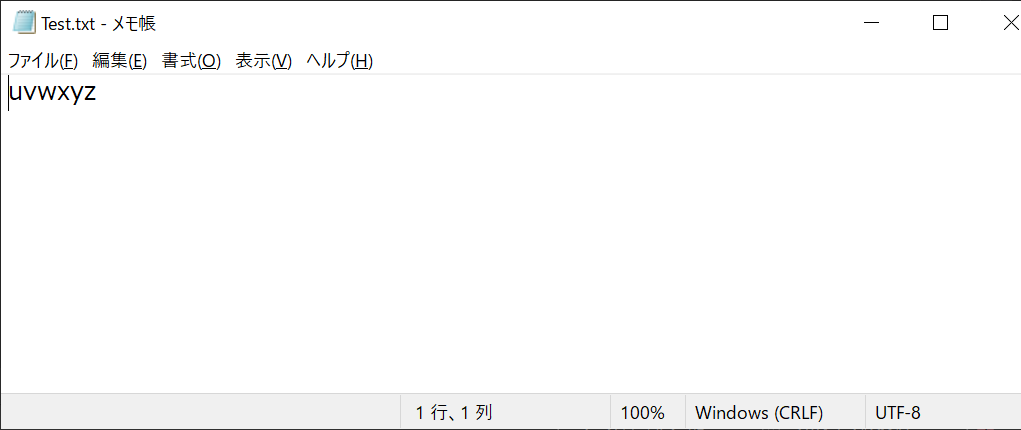
上記のように、seek関数でポインタを先頭に戻したとしても、上書きされるだけなので既存の「abcdef」という文字列は消えてしまいます。また、seek関数はバイト単位でダイレクトに位置を指定する必要があるので、日本語のようなマルチバイト文字の場合は扱いが厄介です。
そのため、前述したように文字列リストを作成し、リスト上でテキストを追記してからファイルに書き出すのが現実的です。
//サンプルプログラム
# coding: Shift_JIS
# osライブラリを使用する
import os
# 適当な文章を作成する
text = "abcdefg\nhijklmn\nvwxyz\n"
# テキストファイルを「書き込みモード」で開く
f = open("Test.txt", "w", encoding = "utf-8")
# テキストファイルに文字列をまとめて書き込む
f.write(text)
# 最後にファイルをクローズする
f.close()
# 適当な文章を作成する
text = "opqrstu\n"
# テキストファイルを「読み書きモード」で開く
f = open("Test.txt", "r+", encoding = "utf-8")
# すべての行をリスト形式で取得する
lines = f.readlines()
# 任意の場所に新しい行を挿入する
lines.insert(2, text)
# 既存ファイルの内容を破棄する
f.truncate(0)
# ファイルポインタを先頭に戻す
f.seek(0, os.SEEK_SET)
# 新たにテキストを書き込む
f.writelines(lines)
# 最後にファイルをクローズする
f.close()
//実行結果
以下のようなテキストファイルが作成されます
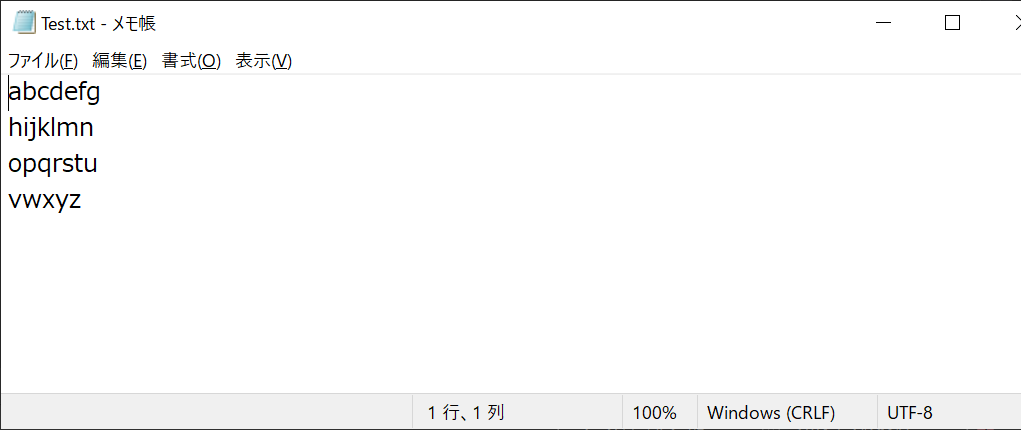
「w+」にすると、既存ファイルが削除されるため、既存のテキストを読み込むことができません。「a+」にした場合も、既存テキストの読み込みに不具合が生じるケースがあるため、この方法でテキストを追記する場合は「r+」モードを選ぶのが無難です。
バイナリファイルを読み書きする方法

バイナリファイルの読み書きの手順も、基本的にはテキストファイルと同じです。ただし、open関数のモードをバイナリに設定する必要があります。また、バイナリファイルを開くときは、テキストファイルとは異なり「文字コード」を設定する必要はありません。以上の点を踏まえて、バイナリファイルの読み書き方法を、以下2つのパターンに分けて解説します。
- バイナリファイルを読み込む手順
- テキストファイルをバイナリモードで読み込む
バイナリファイルを読み込む手順
バイナリファイルを読み込む手順は、基本的にはテキストファイルと同じですが、モード設定を「b」または「rb」にする必要があります。以下の画像ファイルを、Pythonプロジェクトのフォルダに「Sample.png」として保存してから、サンプルコードを実行してみましょう。

//サンプルプログラム
# coding: Shift_JIS
# osライブラリを使用する
import os
# バイナリファイルを開く
f = open("Sample.png", "rb")
# データを読み込む
data = f.read()
# データを表示する
print(data)
# 最後にファイルをクローズする
f.close()
//実行結果
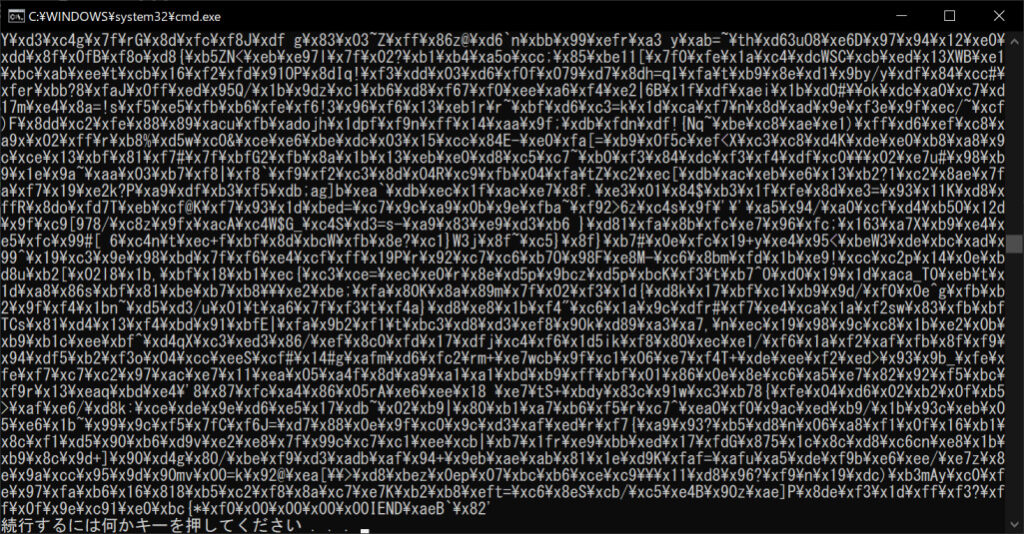
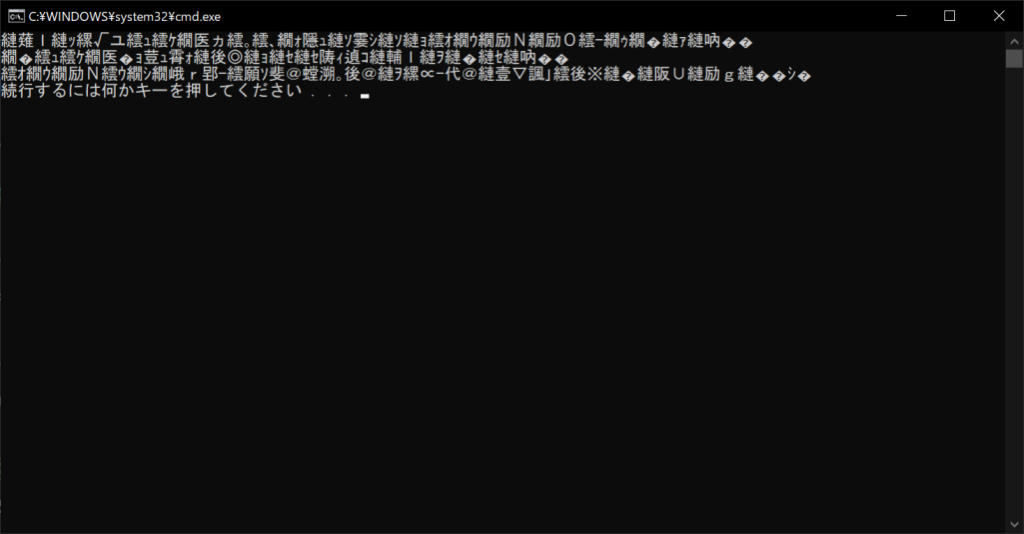
上記のように、16進数のバイトコードがずらりと並んでいます。これが画像ファイルの中身で、色情報がバイトコードで書き込まれていることがわかります。バイナリファイルは、専用のソフトウェアを使わなければ中身が見えないことや、データ配列の形式がわからなければデータを取得できないことなどから、安全性の高いファイル形式だといえます。
テキストファイルをバイナリモードで読み込む
テキストファイルをバイナリモードで読み込むことも可能です。冒頭の「Sample.txt」ファイルを、バイナリモードで読み込んでみましょう。
//サンプルプログラム
# coding: Shift_JIS
# osライブラリを使用する
import os
# バイナリファイルを開く
f = open("Sample.txt", "rb")
# データを読み込む
data = f.read()
# データを表示する
print(data)
# 最後にファイルをクローズする
f.close()
//実行結果
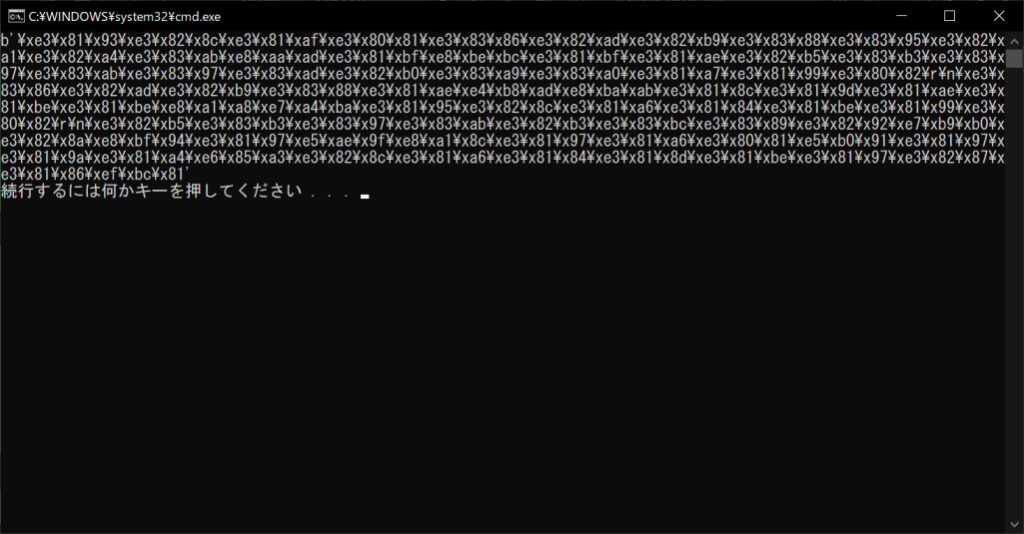
上記のように、文字列がすべてバイトコードで表示されています。テキストファイルは「UTF-8」形式でエンコードされているので、読み込んだバイトコードをUTF-8形式で独自にデコードすると、文字列として表示することができます。その場合は以下の構文のように、strオブジェクトのコンストラクタで文字コードを指定しましょう。
たとえば、「Sample.txt」をバイナリモードで読み込み、独自に「UTF-8」文字コードとしてエンコードすると以下のようになります。
//サンプルプログラム
# coding: Shift_JIS
# osライブラリを使用する
import os
# バイナリファイルを開く
f = open("Sample.txt", "rb")
# データを読み込む
data = f.read()
# データを表示する
print(str(data, encoding = "utf-8", errors = "replace"))
# 最後にファイルをクローズする
f.close()
//実行結果
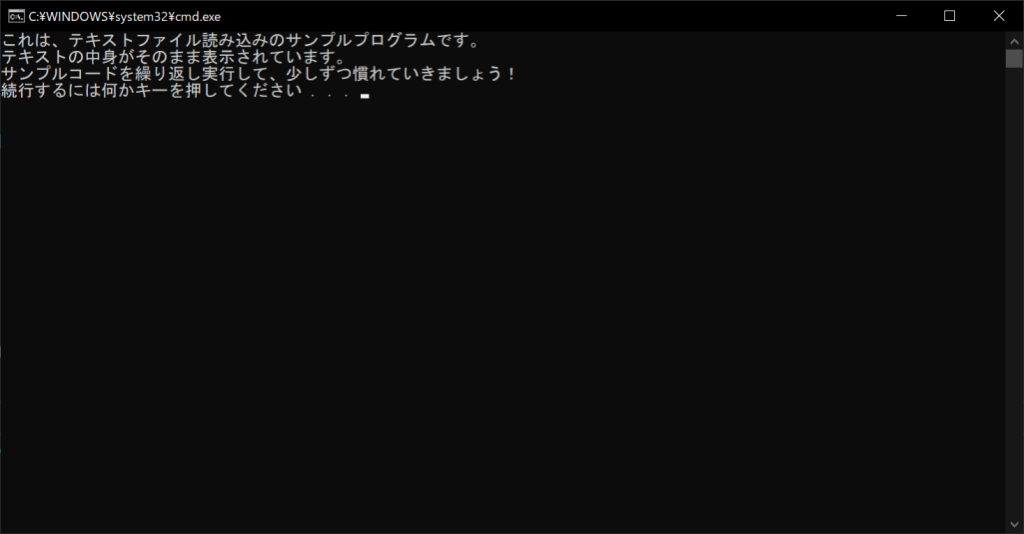
テキストモードで読み込んだ場合と同じく、綺麗に表示されます。これは、テキストファイルがそもそも「UTF-8」文字コードで作成されているためです。一方、「Shift-JIS」のような異なる文字コードでエンコードすると、以下のように文字化けしてしまいます。このように、文字コードはテキストを正しく表示するために重要な要素です。
バイナリファイルにデータを書き込む
バイナリファイルにデータを書き込む際も、テキストファイルと同じく「write関数」が使えます。しかし、データを事前に「バイト配列」に変換しておく必要があります。バイト配列への変換は、事前にデータをリスト形式でまとめておき、bytearray関数の引数としてリストを渡せばOKです。詳細を以下のサンプルコードで確認しましょう。
//サンプルプログラム
# coding: Shift_JIS
# osライブラリを使用する
import os
# 適当なデータをリスト形式で作成する
data = [1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233]
# データをバイト配列に変換する
byte = bytearray(data)
# バイナリファイルを開く
f = open("Data.bin", "wb")
# データを書き込む
f.write(byte)
# 最後にファイルをクローズする
f.close()
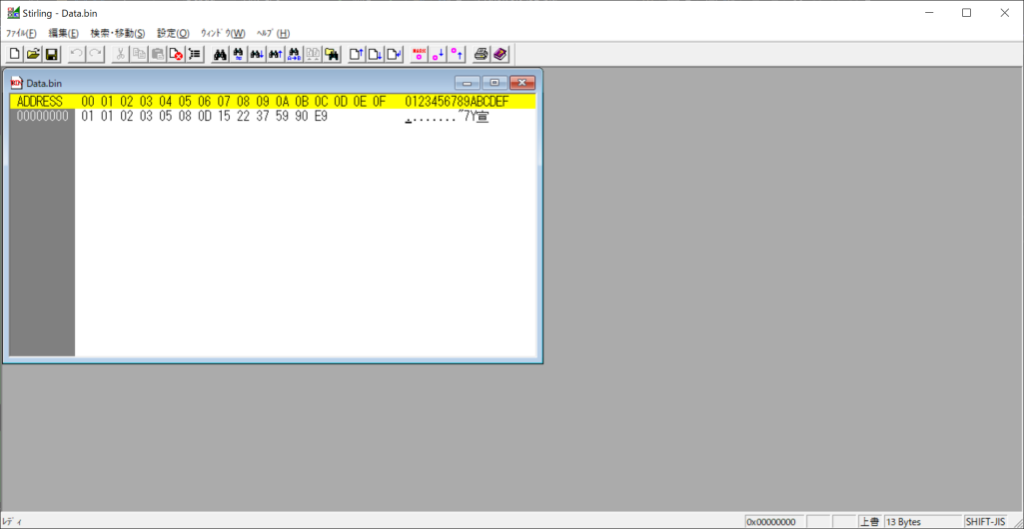
//実行結果
以下のようなバイナリファイルが作成されます
open関数・メソッドの「モード」による違い

Pythonのopen関数のモードは、設定内容によって以下のように挙動が異なるため、目的に合うものを選ぶことが重要です。モードごとの違いを確認しておきましょう。
| モード | ファイルがない場合の挙動 | 読み込み | 書き込み |
|---|---|---|---|
| r | エラー | ○ | × |
| w | 新規作成 | × | ○(上書き) |
| a | 新規作成 | × | ○(追記) |
| r+ | エラー | ○ | ○(追記) |
| w+ | 新規作成 | △(エラーは出ないが正確に読み込めない) | ○(上書き) |
| a+ | 新規作成 | △(エラーは出ないが正確に読み込めない) | ○(追記) |
「w+」と「a+」については、seek関数でファイルポインタを移動したとしても、既存データを正確に読み込めないので注意が必要です。そのため、既存ファイルに対して読み書きの双方を行う場合は、基本的には「r+」のみ使用するほうが良いでしょう。追記だけ行う場合は「a」を選ぶとわかりやすくなります。目的別の推奨モードは以下のとおりです。
| 目的 | モード |
|---|---|
| ファイルを読み込む | r |
| 新規ファイルとして書き出す | w |
| ファイル末尾に追記する | a |
| 読み込みと書き込みを行う | r+ |
| ファイルが存在しない場合だけ書き込む | x |
【応用】「csvファイル」の読み込み方法

Pythonのopen関数では、csvファイルも簡単に読み込むことができます。ちなみに「csvファイル」とは、各項目が「コンマ(,)」で区切られたファイルで、データ管理などで使われることが多いです。
Pythonには「csvライブラリ」があり、これを使うとcsvファイルを簡単にリスト形式に変換できます。まずは、以下のファイルを「List.csv」として保存し、サンプルコードを実行してみましょう。
//List.csv
バナナ,A001,フィリピン,198,50 ぶどう,A002,山梨,298,30 もも,A003,福島,598,10 チョコレート,B010,ベルギー,398,15
//サンプルプログラム
# coding: Shift_JIS
# csvライブラリを使用する
import csv
# csvファイルを開く
f = open("List.csv", "r", encoding = "utf-8")
# csvオブジェクトを作成する
reader = csv.reader(f)
# すべてのデータを表示する
for data in reader:
print(data)
# 最後にファイルをクローズする
f.close()
//実行結果
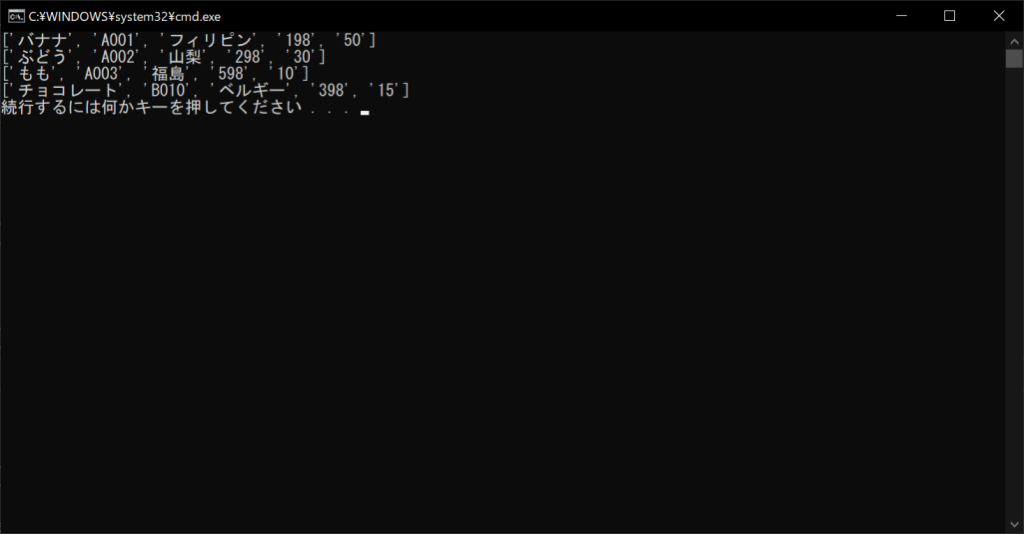
CSVファイルというと難しそうなイメージがあるかもしれませんが、csvライブラリの「reader関数」を使えば、上記のように簡単にcsvファイルのデータをリスト化できます。
Pythonのopen関数・メソッドでよくある質問

Pythonのopen関数に関する、よくある質問をまとめました。open関数の使い方を習得する際の参考にしてみてください。
- 改行コードを消す方法は?
- ファイルの存在をあらかじめ確認する方法は?
- ファイル操作終了時のcloseを省略する方法は?
- 複数のファイルをまとめて読み込む方法は?
改行コードを消す方法は?
open関数でテキストファイルを読み込むときに、改行コードが邪魔になることがあります。そんなときは、readlines関数ですべての行をリストに格納したあとで、forループを回して「strip関数」を実行すると改行コードを削除できます。
//サンプルプログラム
# coding: Shift_JIS
# テキストファイルを開く
f = open("Sample.txt", "r", encoding = "utf-8")
# テキストファイルの中身をまとめて読み込んでリストに格納する
lines = f.readlines()
# すべての行を表示する
print(lines)
# すべての行から「改行コード」を削除する
for i in range(len(lines)):
lines[i] = lines[i].strip()
# すべての行を表示する
print(lines)
# 最後にファイルをクローズする
f.close()
//実行結果
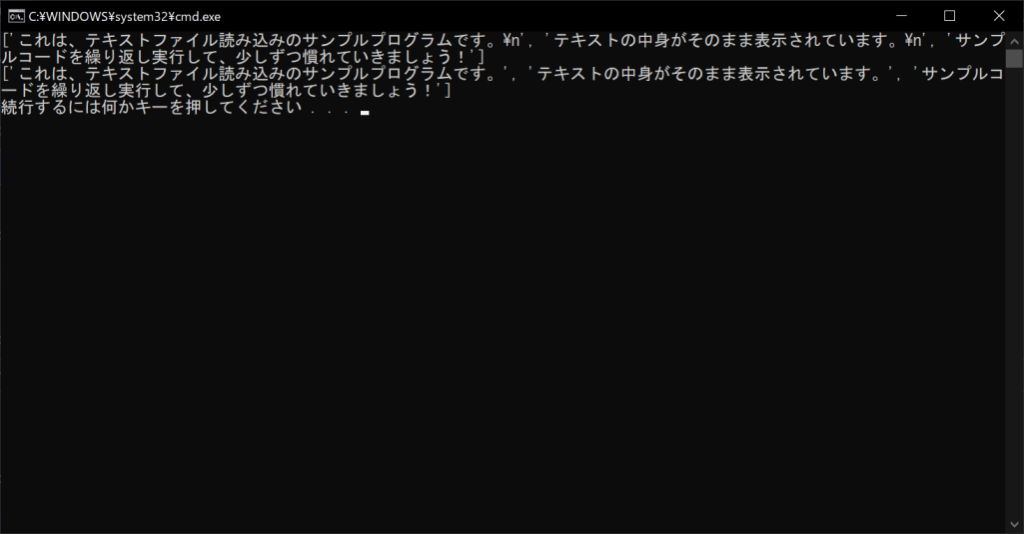
strip関数は引数を指定しない場合、文字列の両端にある空白文字を除去します。空白文字には改行コードも含まれるため、読み込んだテキストの改行を取り除くという目的に最適です。なお、引数に特定の文字を指定すれば、その文字が両端に位置する場合に同じように取り除けます。
ファイルの存在をあらかじめ確認する方法は?
open関数を書き込みモードで使用するときなどは、書き込みミスを防ぐため、ファイルの存在をあらかじめ確認しておきたいことがあるでしょう。その場合はosライブラリの「isfile関数」を使用すると、戻り値がTrue・Falseで返るので、ファイルの有無をチェックできます。
//サンプルプログラム
# coding: Shift_JIS
# osライブラリを使用する
import os
# 存在しないファイルパスを指定する
filepath = "Nothing.txt"
# ファイルの有無で処理を分岐する
if os.path.isfile(filepath):
print("ファイルが存在します")
else:
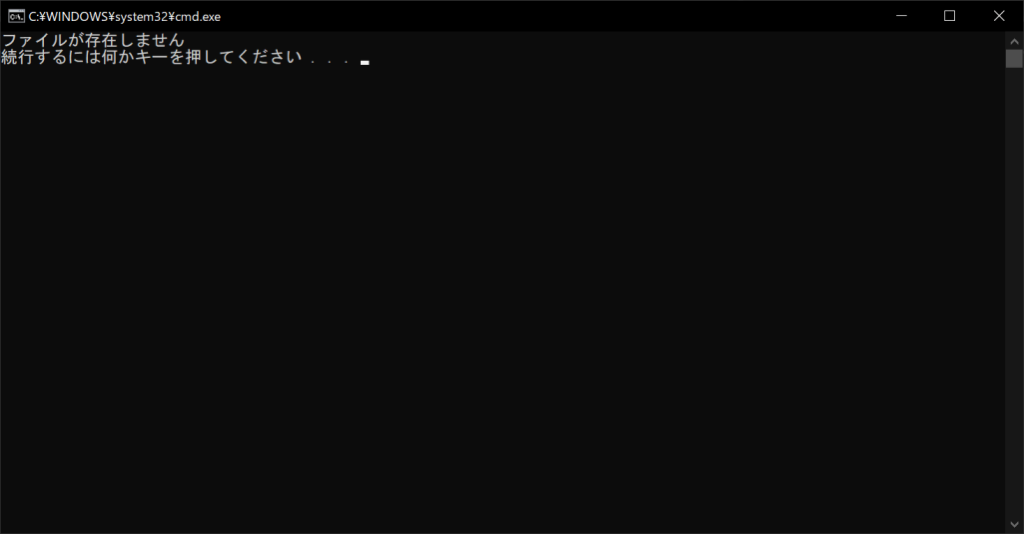
print("ファイルが存在しません")
//実行結果
ファイル操作終了時のcloseを省略する方法は?
open関数でファイルを開いたあとは、close関数でファイルを閉じる必要があります。しかし、ファイルを操作するたびに呼び出すのは面倒ですし、つい書き忘れてしまうこともあるでしょう。そこで、以下の構文で「with」を使えば、withブロックを抜けるときに自動的にclose関数が呼び出されるので、自分で書く必要がなくなります。
処理
重要なポイントは、with文の次の行に必ずインデントを挟むことです。Pythonはインデントの深さで処理のブロックを判断するため、インデントを挟まなければ正しく動作しません。with文のあとでインデントを下げ、処理を行ったあとで元のインデント位置に戻すことで、ファイル操作のブロックが終了したと見なされて、自動的にクローズ処理が行われます。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: Shift_JIS
# テキストファイルを開く
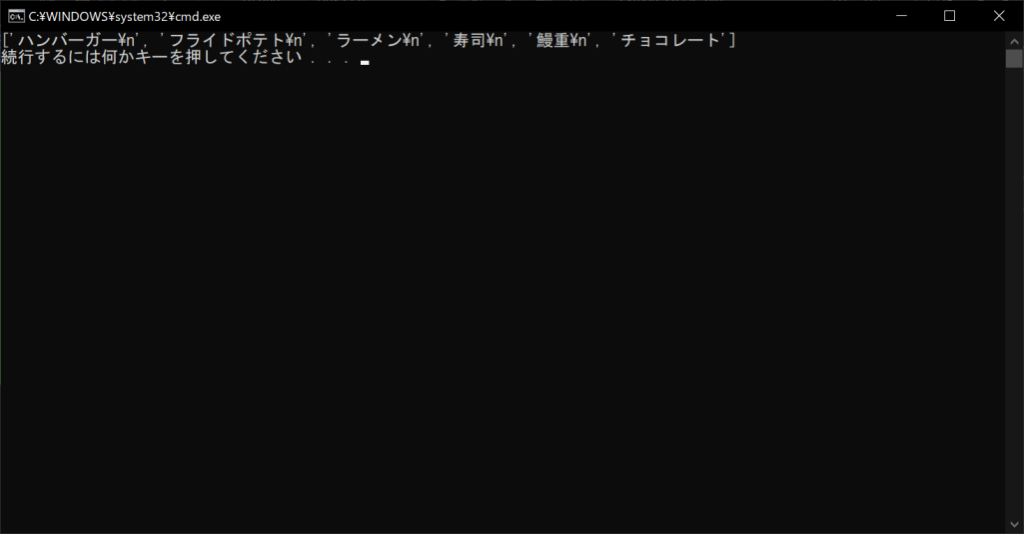
with open("Foods.txt", "r", encoding = "utf-8") as f:
# テキストファイルの中身をまとめて読み込んでリストに格納する
lines = f.readlines()
# すべての行を表示する
print(lines)
//実行結果
複数のファイルをまとめて読み込む方法は?
一度に複数のファイルをまとめて読み込みたいこともあるでしょう。以下の構文で「globライブラリ」を使うと、ワイルドカードに該当する複数のファイルパスをまとめて取得できるので便利です。
引数内には、ベースとなる「ファイル名」と、ワイルドカード「*」を指定します。たとえば、引数を「”Sample_*.txt”」とすると、「Sample_1.txt」など、「Sample_」と「.txt」を含む名称のファイルが該当します。
プロジェクトフォルダに「Sample_1.txt」「Sample_2.txt」「Sample_3.txt」という3つのテキストファイルを作成し、以下のサンプルコードを実行してみましょう。
//サンプルプログラム
# coding: Shift_JIS
# globライブラリを使用する
import glob
# ワイルドカードを指定して、ファイルパスのリストを取得する
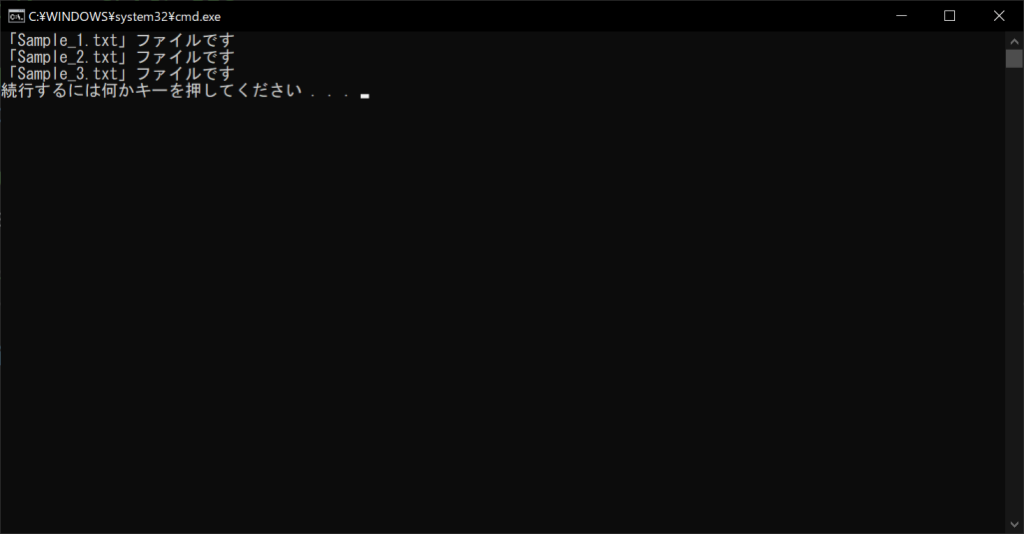
files = glob.glob("Sample_*.txt")
# すべてのファイルをオープンして読み込む
for filepath in files:
with open(filepath, "r", encoding = "utf-8") as f:
print(f.read())
//実行結果
open関数自体には、複数ファイルをまとめて読み込む機能はありません。そのため、glob関数でファイル名のリストを取得したあとで、forループを回して個別に読み込む必要があります。なお、ワイルドカードに該当しないファイルはリストに含まれません。
Pythonのopen関数・メソッドはファイル操作に必須!

Pythonのopen関数は、ファイルの読み込み・書き込みをする際に必須のメソッドです。今回ご紹介したように、open関数は引数としてファイルパス以外に、オープンモードや文字コードなどを指定する必要があります。とくに、モードは目的によって適するものが異なるので、機能の違いなどを少しずつ覚えていきましょう。











アクセスランキング 人気のある記事をピックアップ!
コードカキタイがオススメする記事!

2024.06.17
子供におすすめのプログラミングスクール10選!学習メリットや教室選びのコツも紹介
#プログラミングスクール

2022.01.06
【完全版】大学生におすすめのプログラミングスクール13選!選ぶコツも詳しく解説
#プログラミングスクール

2024.01.26
【未経験でも転職可】30代におすすめプログラミングスクール8選!
#プログラミングスクール

2024.01.26
初心者必見!独学のJava学習方法とおすすめ本、アプリを詳しく解説
#JAVA

2024.01.26
忙しい社会人におすすめプログラミングスクール15選!失敗しない選び方も詳しく解説
#プログラミングスクール

2022.01.06
【無料あり】大阪のおすすめプログラミングスクール14選!スクール選びのコツも紹介
#プログラミングスクール

2024.01.26
【目的別】東京のおすすめプログラミングスクール20選!スクール選びのコツも徹底解説
#プログラミングスクール

2024.01.26
【無料あり】福岡のおすすめプログラミングスクール13選!選び方も詳しく解説
#プログラミングスクール

2024.01.26
【徹底比較】名古屋のおすすめプログラミングスクール13選!選び方も詳しく解説
#プログラミングスクール

2024.01.26
【徹底比較】おすすめのプログラミングスクール18選!失敗しない選び方も徹底解説
#プログラミングスクール