
Pythonの「コメントアウト」とは、ソースコードの一部分を記号で囲み、処理が実行されないようにすることです。ソースコードにコメント(注釈)を付けたり、デバッグ用に処理を無効化したりするために使います。
Pythonのコメントアウトをうまく使いこなすと、ソースコードの可読性が高まるうえに、デバッグや保守がスムーズに進みやすくなります。プログラマとしてレベルアップするためにも、コメントアウトはぜひ覚えておきたいテクニックです。
そこで本記事では、Pythonのコメントアウトについて、その種類や書き方を詳しく解説します。
なお、本記事のソースコードの実行時に「SyntaxError」というエラーが出るときは、「# coding: UTF-8」の部分を「# coding: Shift_JIS」に書き換えてください。
目次
Pythonの「コメントアウト」とは?

Pythonの「コメントアウト」とは、ソースコードを特定の記号で囲み、処理が実行されないようにすることを指します。コメントアウトされた部分を「コメント」と呼び、主にソースコードにメモや注釈を書くために記載します。また、なんらかの理由で実行させたくないものの、ソースコードから削除したくない場合も、コメントアウトを利用すると便利です。
Pythonのソースコードは、コメントを記載しなくても動作します。しかし、ソースコードの読みやすさやメンテナンス性などの理由から、必要に応じてコメントを挿入することが推奨されています。まずは、コメントアウトが無いソースコードと、コメント付きのソースコードを比較してみましょう。
//サンプルプログラム
import random
nums = []
for i in range(10):
nums.append(random.randint(0, 255))
for x in nums:
if x % 2 == 0:
print(x)
上記のソースコードは、10個の整数値をランダムに取得し、そのうち偶数値のみ表示するものです。しかし、コメントが記載されていないため、具体的にどの部分がどのような役割を果たしているか、わかりにくいことがあります。そこで、コメントアウトで注釈を記載したのが、以下のソースコードです。
//サンプルプログラム
# coding: UTF-8
# 「randomモジュール」をインポートする
import random
# 整数値を格納するためのリストを宣言する
nums = []
# 10個の整数値をリストに格納する
for i in range(10):
# random.randint()メソッドでランダムな値を取得する
nums.append(random.randint(0, 256)) # 0~255までの乱数値を生成する
# 偶数値のみ表示する
for x in nums:
if x % 2 == 0: # 2で割った余りが0であれば偶数
print(x)
このように、コメントアウトを行うことで、ソースコードの内容がわかりやすくなります。なお、先頭の「# coding: UTF-8」という部分は、コメントではなくソースコードの文字コードを指定するための記述です。詳細は後述しますが、Pythonのソースコードやコメントに日本語を記載すると、エラーが出ることがあります。それを解決するために、ソースコードの先頭で文字コードを指定する必要があります。
コメントアウトの必要性・メリット

Pythonのソースコードには、以下の3つの理由から、コメントアウトを丁寧に行うことが重要です。コメントアウトのメリットについても解説します。
- ソースコードの意図を伝えられる
- ソースコードが読みやすくなる
- デバッグや保守が行いやすくなる
ソースコードの意図を伝えられる
コメントアウトには、ソースコードの中身を理解しやすくする役割があります。
プログラミングを行うときは、とにかく機能を実装するために書き進めたくなるでしょう。わざわざコメントアウトするのが「面倒くさい」と感じることもありますよね。しかし、コメントアウトは「何を意図して書いたか」「どんな処理を行っているか」などを示すために、意識的に行うことが重要です。
これは、プログラムを複数人で開発するときに役立ちます。1つの結果を得るためのソースコードの書き方には、さまざまなパターンがあります。そのため、複雑なソースコードほど他人が理解しづらくなり、思わぬ誤解やミスにつながりかねません。必要に応じてコメントアウトで注釈を挿入しておけば、お互いのソースコードを正しく理解できます。
また、自身が書いたソースコードをあとで振り返るときも、コメントアウトが役立ちます。時間が経過すれば、自分のプログラムでも処理内容が理解できなくなるものです。未来の自分のためにも、コメントアウトは丁寧に行っておきましょう。
ソースコードが読みやすくなる
コメントアウトは、ソースコードの体裁を整えたり、可読性を高めたりするためにも役立ちます。
ソースコードが長く続いていると、読みづらく感じてしまいます。どの部分が区切りであるか、どの範囲がひとつの処理のまとまりか、すぐにわからないからです。そこで、「区切り」としてコメントアウトを挿入すると、処理のまとまりがわかりやすくなり、修正やメンテナンスもスムーズに行いやすくなります。
デバッグや保守が行いやすくなる
コメントアウトを適切に挿入することにより、プログラムのデバッグや保守も行いやすくなります。
前述したように、コメントアウトがないソースコードは、流し読みしただけでは「どの部分がどのような処理をしているか」わかりません。そのため、プログラムのデバッグや保守に余計な時間がかかってしまいます。コメントアウトの挿入により、ソースコードの意図やまとまりが明らかになるため、どこを重点的にチェックすべきかをすぐに把握できます。
また、プログラムが想定どおり動作しないときに、原因を特定するためにコメントアウトしながらデバッグすると便利です。一部を無効化しながら進めることで、問題のある部分が浮き彫りになり、どこを修正・改善すべきかわかります。
プログラム開発全体を効率化するためにも、ソースコードにコメントアウトを挿入することは重要です。
【基本】Pythonのコメントアウトの方法と特徴

Pythonのコメントアウトの方法は、「インラインコメント(1行コメント)」と「ブロックコメント(複数行コメント)」で異なります。それぞれのコメントアウトの方法と特徴について、具体例を交えて見ていきましょう。
- インラインコメント(1行コメント)
- ブロックコメント(複数行コメント)
インラインコメント(1行コメント)
ソースコードに「#」を記載すると、それ以降の部分が行末までコメントになります。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: UTF-8 # 整数値を格納するためのリストを生成する nums = [] # 0~9までの整数値をリストに格納する # forループで順番に値を取得していく for i in range(10): nums.append(i) # リストの中身を表示する print(nums)
//実行結果
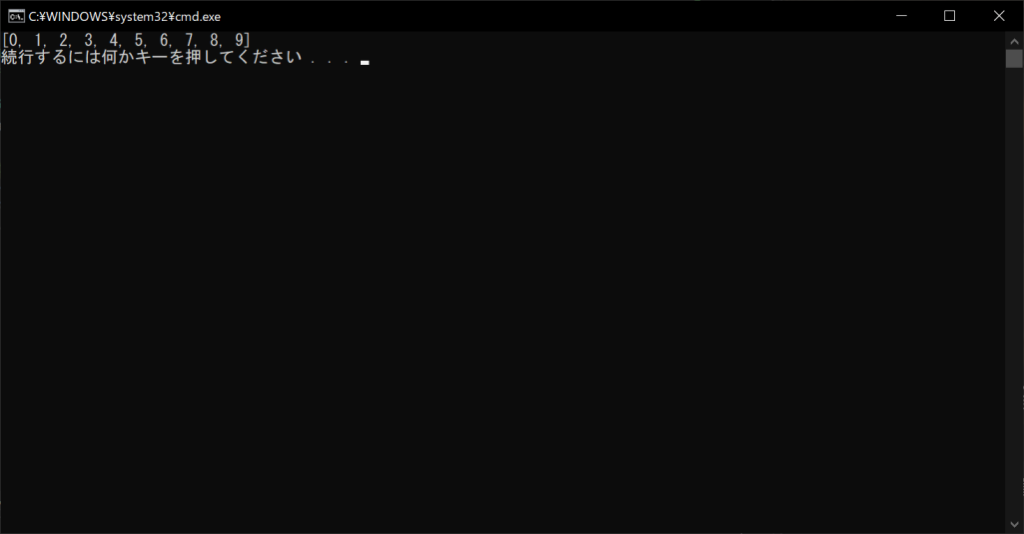
上記のように、「#」でコメントアウトした部分は、ソースコードとして扱われず無視されていることがわかります。試しにforループの部分をコメントアウトすると、その部分も実行されなくなります。
//サンプルプログラム
# coding: UTF-8 # 整数値を格納するためのリストを生成する nums = [] # 0~9までの整数値をリストに格納する # forループで順番に値を取得していく #for i in range(10): # nums.append(i) # リストの中身を表示する print(nums)
//実行結果
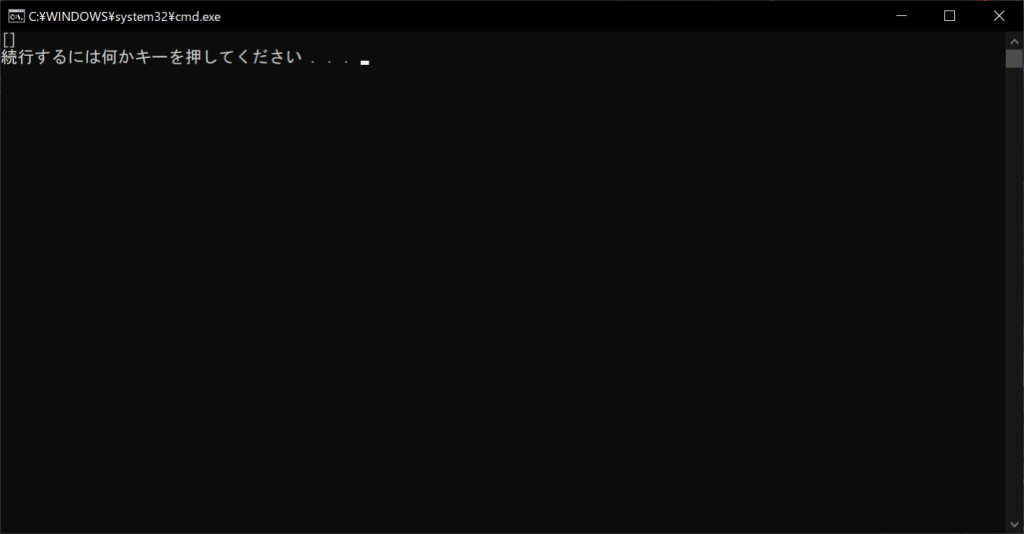
このように、リストの中身が更新されていません。こうしたコメントアウトの特性を活用すると、ソースコードの調整やデバッグなどにも便利です。以上の点を踏まえて、インラインコメントの特徴を見ていきましょう。
- 複数行にわたるコメントアウトはできない
- 行の途中からでもコメントアウトできる
- コメントの範囲を指定することはできない
- インデントを無視して「#」を記載してもOK
- ほかの記号と組み合わせることもできる
- 文字列内の「#」は文字列として扱われる
複数行にわたるコメントアウトはできない
インラインコメントの影響はその行にしか及ばないため、複数行にわたるコメントアウトはできません。次の行に移ると、再び通常のソースコードに戻るため、複数行にわたってコメントアウトする場合は、以下のように行ごとに「#」を挿入しないといけません。
# coding: UTF-8
# 1行目のコメント
# 2行目のコメント
# 3行目のコメント
# 4行目のコメント
# 5行目のコメント
行の途中からでもコメントアウトできる
ソースコード中に「#」を記載すると、それ以降の部分が行末まで無視され、それ以前の部分は通常のコードとして機能します。以下の例で詳細を確認しましょう。
//サンプルプログラム
# coding: UTF-8 # 整数値を格納するためのリスト nums = [] for x in range(10): # 0~9までの2乗値を表示する nums.append(x ** 2) # 「a**b」で「aをb乗」する # 結果を表示する print(nums[x])
//実行結果
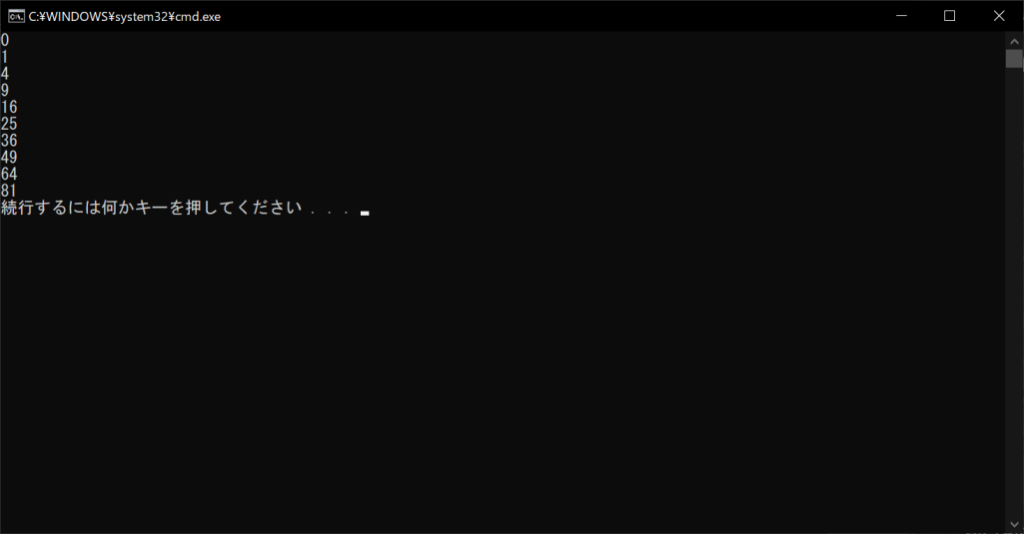
「nums.append(x ** 2)」の部分に注目しましょう。直後にコメントアウトがありますが、この部分はきちんと実行されていることがポイントです。コメントアウトするたびに改行すると、ソースコードが縦に長くなることがあります。そこで、ソースコードの右側にコメントアウトを挿入すると、簡潔なコメントが記載しやすくなるでしょう。
コメントの範囲を指定することはできない
インラインコメントは、行の途中からでも挿入できますが、その範囲を指定することはできません。
//サンプルプログラム
# coding: UTF-8 # 2つの整数値を設定する numA = 1 numB = 2 ###現時点ではnumBを表示するが、最終的にはnumAを表示!### print(#numA#numB)
//実行結果
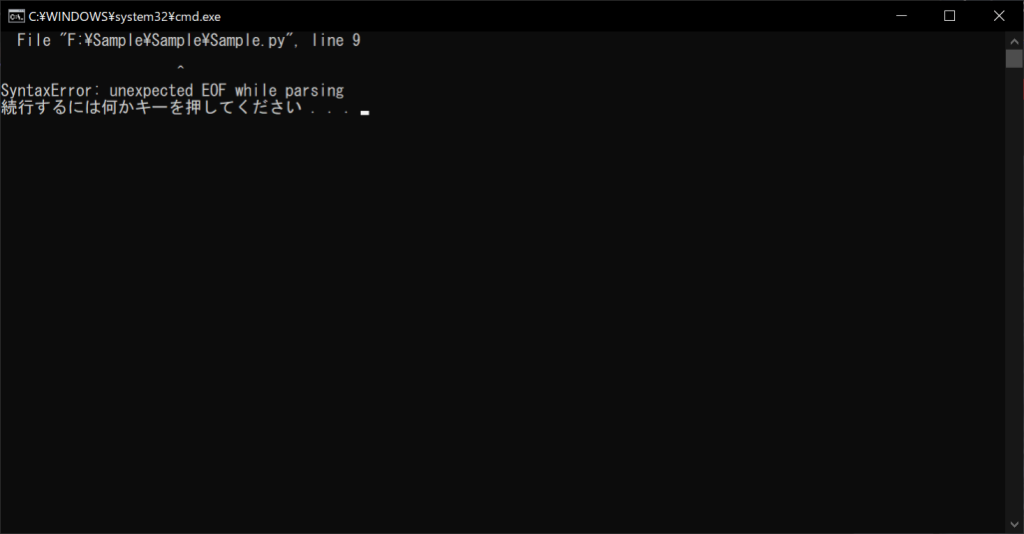
上記の例は、print関数で「numA」を表示していたところを、コメントアウトして「numB」を表示するように変えたものです。プログラマの意図としては、print()の「numA」の部分だけコメントアウトして、「print(numB)」として動作させることです。しかし、「#」で「numA」の部分のみをコメントアウトすることはできないので、結果的に「numB」の部分もコメントアウトされてエラーとなってしまいます。
インデントを無視して「#」を記載してもOK
インラインコメントは「#」以降を無視する仕様となっています。そのため、インラインコメントはインデント位置を気にする必要なく、自由な位置に挿入できます。ただし、以下のように見づらくなるので、基本的にはソースコードのインデントに合わせるほうがいいでしょう。
//サンプルプログラム
# coding: UTF-8
# 整数値を格納するためのリスト
nums = []
for x in range(10):
# 0~9までの2乗値を表示する
nums.append(x ** 2) # 「a**b」で「aをb乗」する
# 結果を表示する
print(nums[x])
なお、コメントアウトのインデントをあえて先頭にすることで、コメントを目立たせられます。後述するように、ほかの記号と組み合わせると、重要なポイントをアピールして、抜け漏れを防ぐことが可能です。
ほかの記号と組み合わせることもできる
デバッグ用の「print()メソッド」などを挿入したときは、あとで削除しておく必要があります。削除し忘れると、リリース版でユーザーが実行したときに、思わぬタイミングでデバッグメッセージなどが表示されてしまうからです。
以下のサンプルコードのように、行頭に「#」を挿入して「@」や「$」などで装飾しておけば、抜け漏れなくデバッグコードを削除しやすくなります。
# coding: UTF-8 # 整数値を格納するためのリスト nums = [] for x in range(10): # 0~9までの2乗値を表示する nums.append(x ** 2) # 「a**b」で「aをb乗」する ###@@@この部分はデバッグ用なので必ず消すこと!@@@### print(nums[x])
文字列内の「#」は文字列として扱われる
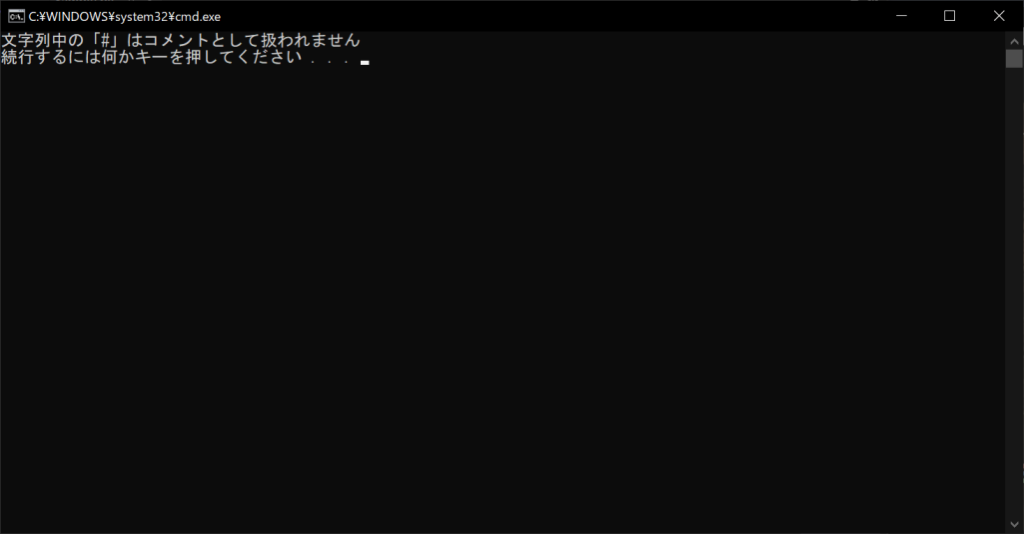
ソースコード中の「#」はコメントアウトの記号として扱われますが、文字列内の「#」は通常の文字列として扱われます。そのため、以下のように文字列に「#」が含まれていたとしても、コメントアウトはされません。
//サンプルプログラム
# coding: UTF-8
# 文字列を表示する
print("文字列中の「#」はコメントとして扱われません")
//実行結果
ブロックコメント(複数行コメント)
ブロックコメントは、複数行をコメントアウトするための構文です。インラインコメントを複数行に渡って挿入したい場合、ひとつの方法が「#」を行ごとに挿入する方法ですが、それでは手間がかかります。
そんなとき、シングルクォーテーションもしくはダブルクォーテーションを3つ並べると、ブロックコメントとなり、それ以降の行がすべてコメントとなるため便利です。再びクォーテーションを3つ並べるとコメントは終了します。詳細は以下のサンプルプログラムのとおりです。
//サンプルプログラム
# coding: UTF-8 """ 0~9までの2乗値を表示するプログラム """ # 整数値を格納するためのリスト nums = [] for x in range(10): """ 0~9までの2乗値を表示する 「a**b」で「aをb乗」する """ nums.append(x ** 2) # 結果を表示する print(nums[x])
ブロックコメントを活用すると、最初と最後だけクォーテーションを3つ並べるだけでコメントになります。なお、ブロックコメントはダブルクォーテーションを使うことが習慣となっているので、シングルクォーテーションは使用しないことをおすすめします。以上の点を踏まえて、ブロックコメントの特徴を見ていきましょう。
- インデントを合わせる必要がある
- 行の途中に挿入することはできない
インデントを合わせる必要がある
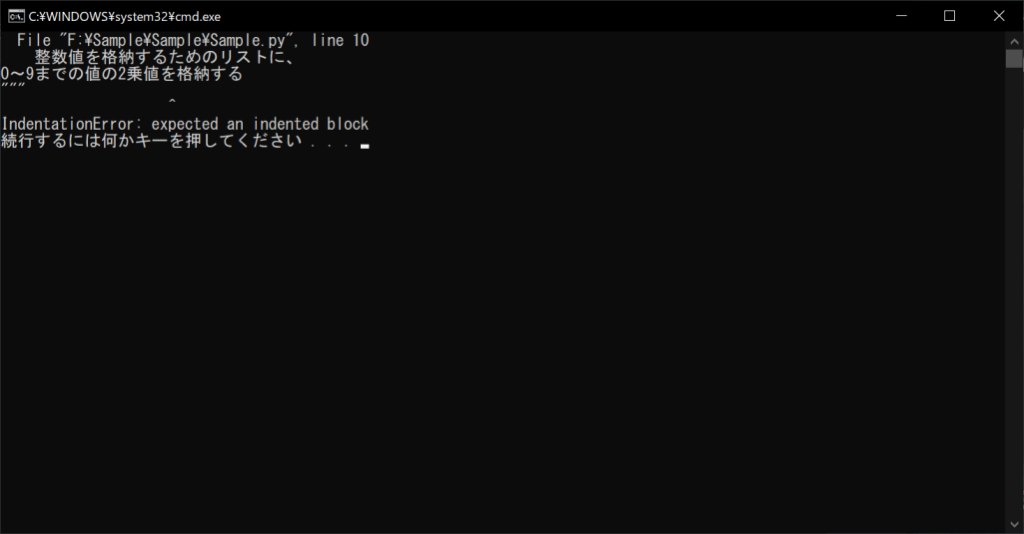
ブロックコメントは、インラインコメントとは異なり「インデント」を合わせる必要があります。以下の例のように、インデントを無視してブロックコメントを挿入すると、エラーが出るので注意しましょう。
//サンプルプログラム
# coding: UTF-8 nums = [] for x in range(10): """ forループを10回繰り返し、 整数値を格納するためのリストに、 0~9までの値の2乗値を格納する """ nums.append(x ** 2) print(nums[x])
//実行結果
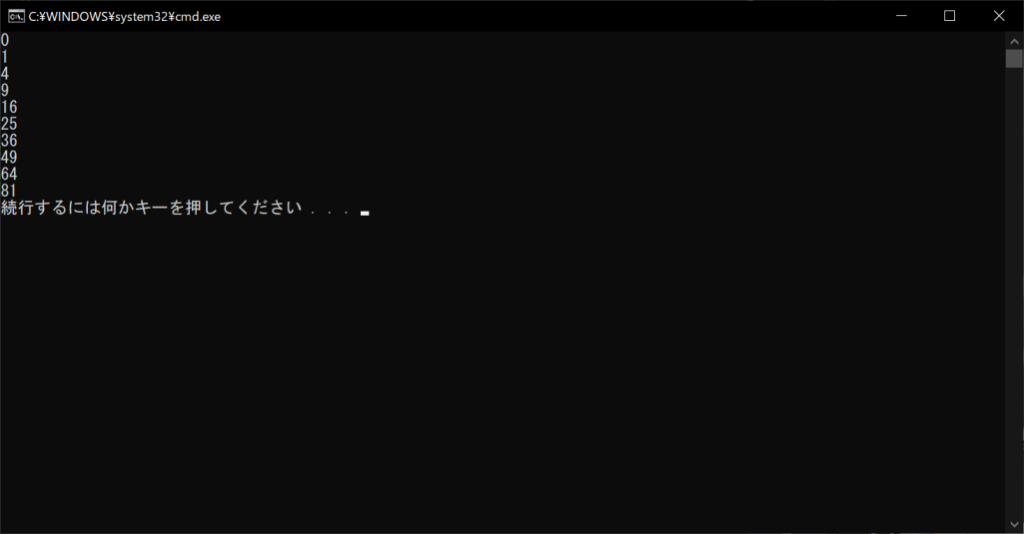
インデントを正しい位置に戻すと、エラーが解消されて動作するようになります。そのため、インデントを無視してコメントを目立たせたい場合は、以下のように「#」を各行に追加してブロックコメントを使う必要があります。
//サンプルプログラム
# coding: UTF-8 nums = [] for x in range(10): ### # forループを10回繰り返し、 # 整数値を格納するためのリストに、 # 0~9までの値の2乗値を格納する ### nums.append(x ** 2) print(nums[x])
//実行結果
行の途中に挿入することはできない
「インデントを守らないといけない」というブロックコメントの特徴上、ブロックコメントは行の途中に挿入できません。
//サンプルプログラム
# coding: UTF-8 """ 整数値を格納するためのリスト """ nums = [] for x in range(10): """ 0~9までの2乗値を表示する """ nums.append(x ** 2) """ 「a**b」で「aをb乗」する """ """ 結果を表示する """ print(nums[x])
//実行結果
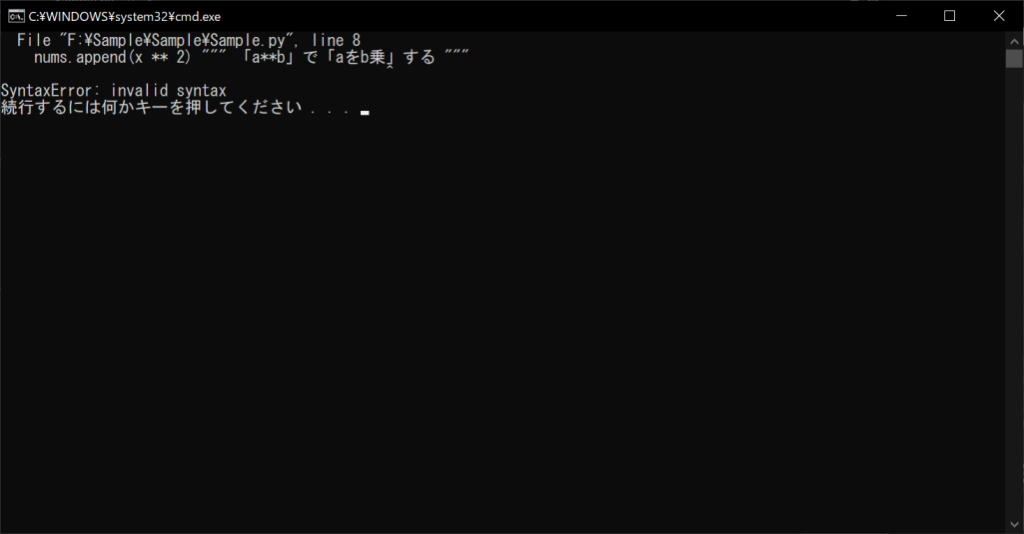
上記のサンプルプログラムでは、「nums.append(x ** 2)」の右側にブロックコメントを挿入しています。しかし、この部分は行頭ではないため、「SyntaxError」のエラーが発生してしまいます。行の途中でコメントを挿入する場合は、前述したインラインコメントを使用しましょう。
「docstring」で自作関数やクラスのドキュメントを作成可能

前述した「ブロックコメント」を活用すると、「docstring」で自作関数やクラスのドキュメントを作成できます。docstringについて、以下の3つのポイントに分けて見ていきましょう。
- docstringとは|自作関数やクラスに付ける注釈
- docstringの使い方|ブロックコメントを活用
- docstringの応用|help()メソッドで表示
docstringとは|自作関数やクラスに付ける注釈
「docstring」とは、自作関数・クラスなどに付ける注釈のことです。通常のコメントアウトと異なる点は、docstringはモジュール・クラス・メソッド(関数)などの仕様を記載した、いわば「説明書」のような機能を果たすことです。以下のようなコメントアウトを挿入すると、docstringとして認識されます。
//サンプルプログラム
# coding: UTF-8
class Normalization:
"""
データを正規化するためのクラス
"""
def normalize(self, data):
""" データを正規化する
引数で渡されたリストを正規化して返す
Args:
data (list): 正規化したいデータ
Returns:
list: 正規化されたデータ
Examples:
>>> n = normalize([7, 13, 1, 5, 2, 11, 3, 17]
>>> print(n)
[0.375, 0.75, 0.0, 0.25, 0.0625, 0.625, 0.125, 1.0]
"""
# データの最大値と最小値を求める
max_value = max(data)
min_value = min(data)
# データを正規化する
return [(x - min_value) / (max_value - min_value) for x in data]
# 実際にデータを平均化する
n = Normalization()
print(n.normalize([7, 13, 1, 5, 2, 11, 3, 17]))
docstringの使い方|ブロックコメントを活用
クラスやメソッドなどを定義するときに、クォーテーションを3つ並べるブロックコメントを追加すると、自動的にdocstringとして扱われます。docstringで重要なポイントは、メソッドのコメントの書き方です。基本的には以下のように、メソッドの概要や引数・戻り値の仕様を簡潔に記載します。
def normalize(self, data):
""" データを正規化する
引数で渡されたリストを正規化して返す
Args:
data (list): 正規化したいデータ
Returns:
list: 正規化されたデータ
Examples:
>>> n = normalize([7, 13, 1, 5, 2, 11, 3, 17]
>>> print(n)
[0.375, 0.75, 0.0, 0.25, 0.0625, 0.625, 0.125, 1.0]
"""
「Args」には、メソッドの引数について「名称 (型名): 概要」の順で書きます。概要が長くなるとわかりづらくなるため、簡潔に記載することが重要です。「Returns」には、戻り値について「型名: 概要」の順で示します。「Examples」には、メソッドを利用する際の書き方や、実行結果の例を記載しておきましょう。
なお、docstringはダブルクォーテーションで記載するという習慣があるため、基本的にはダブルクォーテーションを使いましょう。
docstringの応用|help()メソッドで表示
docstringの使い方について解説しましたが、これではdocstringのメリットがわかりにくいかもしれません。docstringの魅力は、ドキュメントとしてクラスやメソッドの仕様を確認できることです。
docstringの中身は、「help()メソッド」の引数にモジュール名を指定すると表示できます。まずは、PythonのIDEで新たなpyファイルを「Normalization.py」という名称で作成し、以下のソースコードを保存しましょう。
# coding: UTF-8
class Normalization:
"""
データを正規化するためのクラス
"""
def normalize(self, data):
""" データを正規化する
引数で渡されたリストを正規化して返す
Args:
data (list): 正規化したいデータ
Returns:
list: 正規化されたデータ
Examples:
>>> n = normalize([7, 13, 1, 5, 2, 11, 3, 17]
>>> print(n)
[0.375, 0.75, 0.0, 0.25, 0.0625, 0.625, 0.125, 1.0]
"""
# データの最大値と最小値を求める
max_value = max(data)
min_value = min(data)
# データを正規化する
return [(x - min_value) / (max_value - min_value) for x in data]
# 実際にデータを平均化する
n = Normalization()
print(n.normalize([7, 13, 1, 5, 2, 11, 3, 17]))
次に、作成したモジュール(pyファイル)を、別のpyファイルで以下のようにimportしましょう。そのうえでhelp()メソッドを使用すると、docstringを表示させられます。
//サンプルプログラム
# coding: UTF-8 # 「Normalization.py」をインポートする import Normalization # 「help()メソッド」で「Normalization.py」のdocstringを表示する help(Normalization)
//実行結果
[0.375, 0.75, 0.0, 0.25, 0.0625, 0.625, 0.125, 1.0]
Help on module Normalization:
NAME
Normalization - # coding: UTF-8
CLASSES
builtins.object
Normalization
class Normalization(builtins.object)
| データを正規化するためのクラス
|
| Methods defined here:
|
| normalize(self, data)
| データを正規化する
| 引数で渡されたリストを正規化して返す
|
| Args:
| data (list): 正規化したいデータ
|
| Returns:
| list: 正規化されたデータ
|
| Examples:
| >>> n = normalize([7, 13, 1, 5, 2, 11, 3, 17]
| >>> print(n)
| [0.375, 0.75, 0.0, 0.25, 0.0625, 0.625, 0.125, 1.0]
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
DATA
n = <Normalization.Normalization object>
FILE
f:\python\sample\sample\normalization.py
以上のように、クラスやメソッドに記載したコメントが、クラスの階層構造と合わせて表示されます。また、実行画面の下部に「– More –」と記載された部分がありますが、Enterキーを入力すると省略された部分を表示できます。このように、クラスやメソッドの詳細をドキュメントで示したい場合は、docstringを利用すると便利です。
Pythonのコメントアウト・コメントの注意点

Pythonのコメントアウトを使用するときは、以下の2つの注意点を意識しましょう。
- コメントは正確に記載する
- マルチバイト文字に要注意
コメントは正確に記載する
Pythonのコメントは、適切に記載する必要があります。誤ったコメントを書くと、ソースコードを理解するどころか、かえって誤解やミスを招きかねません。
//サンプルプログラム
# coding: UTF-8
# 「randomモジュール」をインポートする
import random
# 浮動小数点値を格納するためのリストを宣言する
nums = []
# 10個の整数値をリストに格納する
for i in range(20):
# random.uniform()メソッドでランダムな値を取得する
nums.append(random.randint(0, 256)) # 0~100までの乱数値を生成する
# 奇数値のみ表示する
for x in nums:
if x % 2 == 0: # 2で割った余りが0であれば偶数
print(x)
//実行結果
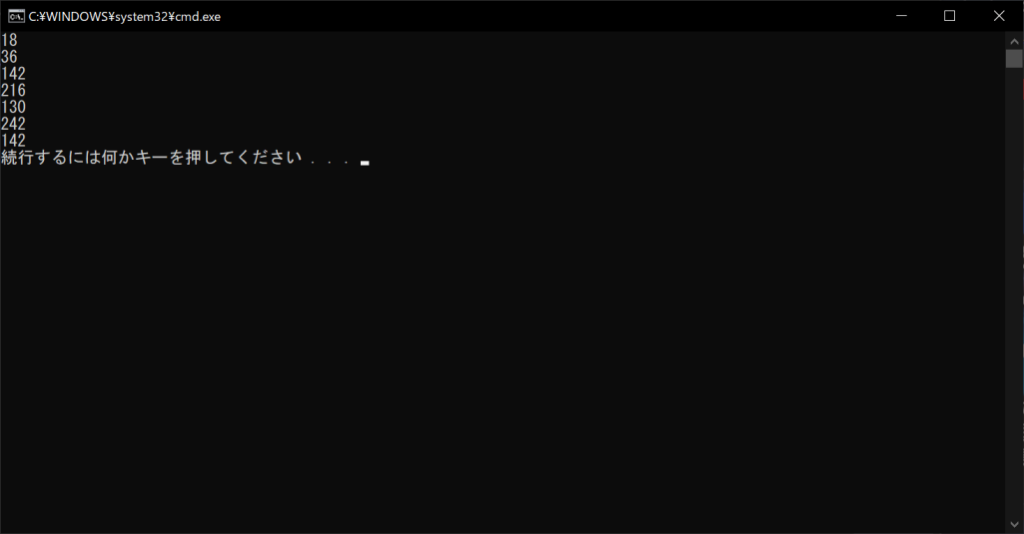
上記のソースコードは、ソースコードの内容とコメントがあまりに違いすぎるため、プログラマが何を意図したのか理解できません。ソースコードとコメントのどちらが本来の意図であるかもわからないため、デバッグや修正も困難です。このように、誤ったコメントは混乱の原因になるので、コメントアウト時は必ず正しいコメントを記載しましょう。
マルチバイト文字に要注意
日本語や中国語のような「マルチバイト文字」を、Pythonのソースコードやコメントに記載する際は、あらかじめ文字コードを指定する必要があります。
マルチバイト文字とは、1文字が2バイト以上で表現される文字のことで、1文字1バイトの半角英数字とは大きく異なります。これらの文字をコメントで使用すると、以下のようなエラーが出るので注意が必要です。
//サンプルプログラム
# 日本語のコメント
//実行結果
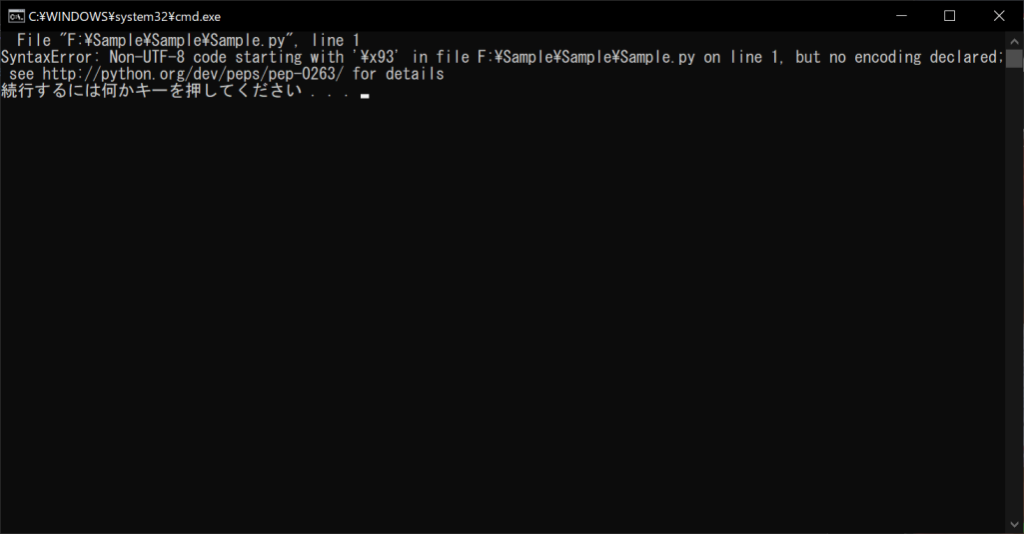
エラーの内容は、「UTF-8ではない文字コードが使用されている」というものです。これは、ソースコードのエンコード形式(文字コード)が指定されていないことが原因です。そこで以下のように、「# coding: UTF-8」をファイル冒頭で指定すると解決できます。
//サンプルプログラム
# coding: UTF-8 # 日本語のコメント
//実行結果
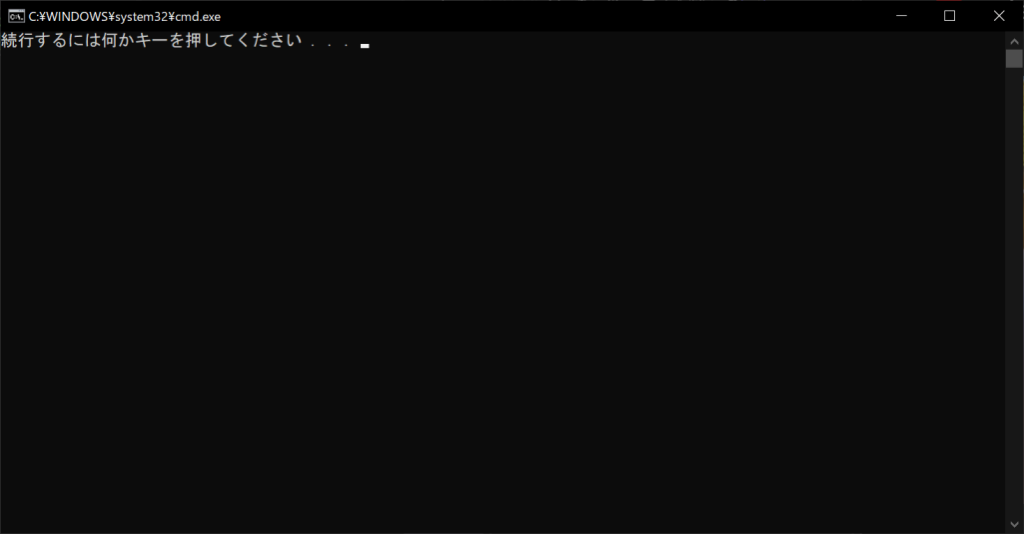
なお、「# coding: UTF-8」とすると、「’utf-8′ codec can’t decode byte」のような別のエラーが生じる可能性もあります。これは、ソースコードを記載するための「pyファイル」が、「Shift-JIS」もしくは「cp932」形式で作成されていることが理由です。「# coding: Shift-JIS」と記載することで、エラーを解消できるでしょう。なお、cp932はShift-JISの一種で、Windowsで標準的に使用されている文字コードです。
コメントアウトを活用してわかりやすいソースコードを書こう

Pythonのコメントアウトを活用すると、ソースコードの注釈やプログラマの意図を示せるうえに、デバッグや保守も効率的に行いやすくなります。
コメントアウトには、「#」から始まるインラインコメントと、「”””」もしくは「”’」から始まるブロックコメントの2種類があります。コメントアウトを行うときは、必ず正しい内容のコメントを記載するように注意することが重要です。Pythonのコメントアウトを活用して、よりわかりやすいソースコードを作成しましょう。










アクセスランキング 人気のある記事をピックアップ!
コードカキタイがオススメする記事!

2024.06.17
子供におすすめのプログラミングスクール10選!学習メリットや教室選びのコツも紹介
#プログラミングスクール

2022.01.06
【完全版】大学生におすすめのプログラミングスクール13選!選ぶコツも詳しく解説
#プログラミングスクール

2024.01.26
【未経験でも転職可】30代におすすめプログラミングスクール8選!
#プログラミングスクール

2024.01.26
初心者必見!独学のJava学習方法とおすすめ本、アプリを詳しく解説
#JAVA

2024.01.26
忙しい社会人におすすめプログラミングスクール15選!失敗しない選び方も詳しく解説
#プログラミングスクール

2022.01.06
【無料あり】大阪のおすすめプログラミングスクール14選!スクール選びのコツも紹介
#プログラミングスクール

2024.01.26
【目的別】東京のおすすめプログラミングスクール20選!スクール選びのコツも徹底解説
#プログラミングスクール

2024.01.26
【無料あり】福岡のおすすめプログラミングスクール13選!選び方も詳しく解説
#プログラミングスクール

2024.01.26
【徹底比較】名古屋のおすすめプログラミングスクール13選!選び方も詳しく解説
#プログラミングスクール

2024.01.26
【徹底比較】おすすめのプログラミングスクール18選!失敗しない選び方も徹底解説
#プログラミングスクール