
Pythonの「glob.glob()」は、指定したディレクトリ(フォルダ)の中にある、ファイルやサブディレクトリのリストを取得するための関数です。glob.glob()は、Python標準の「globモジュール」に組み込まれており、「パターンルール」を活用した抽出条件の指定も可能です。
しかし、glob.glob()のパターンルールの機能には制限があります。より複雑な抽出が必要な場合は、「正規表現」を使用するための「reモジュール」も欠かせません。正規表現の構文は難しい部分があるため、事前に理解しておく必要があります。
そこで本記事では、Pythonのglob.glob()の基本的な使い方やパターンルールによる抽出方法、さらに正規表現を活用した複雑な条件指定について解説します。glob.glob()はファイル処理で多用する関数なので、ぜひ参考にしてみてください。
目次
Pythonの「glob.glob」とは
Pythonの「glob」とは、指定した条件に該当するファイルやディレクトリのリストを取得する機能を備えた、ファイル関連のモジュールです。代表的な関数として「glob.glob()」がありますが、そのほかにも便利な関数を利用できます。
そもそもglobという英単語には、「かたまり」という意味があります。つまりglobモジュールは、特定の条件に該当するファイルやディレクトリの一覧を取得するためのものだということです。例えば、glob.glob()関数にファイル名/ディレクトリ名のマッチング条件を引数として指摘すると、それに該当するリストを返します。
Pythonの「glob.glob」の使い方

「globモジュール」および「glob.glob()」の使い方について、まずは以下の6つのポイントから解説します。
- テストファイルを用意する
- ひとつのファイルを検出する
- ワイルドカードで複数のファイルを検出する
- 深い階層の別のディレクトリのファイルを検出する
- すべてのファイル名とディレクトリ名を個別に取得する
- ディレクトリ名を除いてファイル名のみ取得する
テストファイルを用意する
「globモジュール」および「glob.glob()」は、条件に合致するファイルやディレクトリ内を検出するためのものです。そのため、globモジュールやglob.glob()の使い方について学ぶためには、「テスト用のディレクトリ構造」を用意する必要があります。今回は以下のようなファイル・ディレクトリを構成しましょう。
- Directory01~Directory03
- 01.csv~10.csv
- 01.txt~10.txt
具体的には、以下の画像のような構成で「Dataフォルダ」を作成し、Pythonの実行モジュールがある場所に設置しましょう。同じ名称の「.txt」と「.csv」ファイル、さらにディレクトリを用意しておくことが重要です。
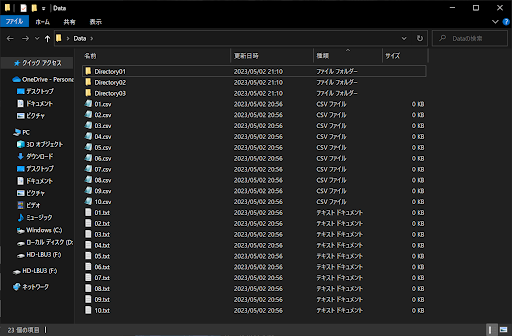
作成した「Dataフォルダ」を、Pythonのメインモジュールがある場所に設置します。Windows PCでVisual Studioを利用している場合は、以下のようになります。フォルダの設置場所が異なると、サンプルプログラムが正しく動作しないので注意してください。
なお、フォルダ内の各ファイル/ディレクトリの中身は空でも構いません。ファイルとディレクトリさえ存在すれば、globモジュールおよびglob.glob()は機能します。
ひとつのファイルを検出する
globモジュールの使い方として、まずはglob.glob()関数でひとつのファイル/ディレクトリを検出する方法を解説します。glob.glob()を以下の構文で使用することで、条件に合致するファイルやディレクトリを検出できます。
ファイルリスト = glob.glob("検出条件")
「検出条件」は、ファイル名/ディレクトリ名や、後述するパターンルール/正規表現などを使用して、検索したい条件を指定するための引数です。ここにファイルパスをダイレクトに指定すると、ひとつのファイルやディレクトリを検出できます。詳細は以下のとおりです。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「glob.glob()」を使用して、「"Data\\01.txt"」ファイルを検出する
file_list = glob.glob("Data\\01.txt")
# 取得したファイルリストを表示する
print(file_list)
# 「glob.glob()」を使用して、「"Data\\Directory01"」ディレクトリを検出する
directory_list = glob.glob("Data\\Directory01")
# 取得したファイルリストを表示する
print(directory_list)
// 実行結果
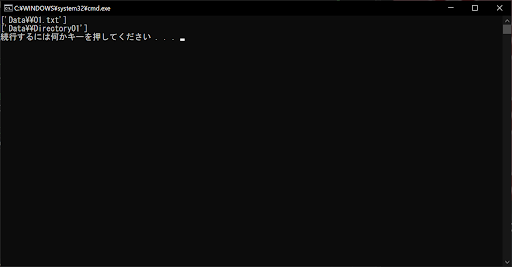
上記のサンプルプログラムは、glob.glob()関数を使用して、「Data\\01.txt」ファイルと「Data\\Directory01」ディレクトリを検出するというものです。ディレクトリの検出は、拡張子を指定しないようにすることで行えます。
なお、ディレクトリの区切り文字を「\\」というふうに「\」を2つ並べていますが、これは「\」が後述するメタ文字として扱われることが理由です。通常の意味の「\」を使用する場合は、エスケープ文字としての意味がある「\」と並べて、「\\」と記載しないといけません。いずれにせよ、ディレクトリの区切り文字は「\\」と覚えておくといいでしょう。
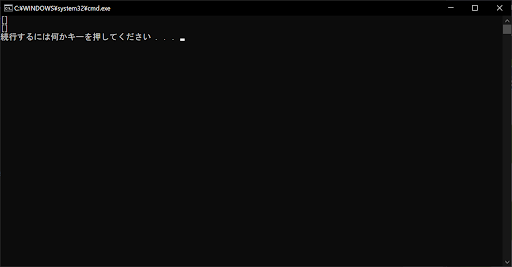
「/」でも構いません。ちなみに、該当するものがない条件を指定した場合はリストが空欄となり、以下のようにエラーなどが出ることはありません。
ワイルドカードで複数のファイルを検出する
glob.glob()関数で複数のファイルを検出するためには、「ワイルドカード」と呼ばれる特殊文字を使用する必要があります。ワイルドカードはアスタリスク「*」で表記し、「0文字以上の任意の文字列」を意味します。
例えば、Dataディレクトリに存在するすべての「.txt」を取得したい場合は、以下のように記載すればOKです。
file_list = glob.glob("Data\\*.txt")
検出条件にワイルドカードが含まれているため、条件は「Dataフォルダ内」「.txtファイル」ということになります。
これを「”Data\\ファイル*.txt”」のようにすると、Dataフォルダ内にある「ファイル」という文字列を含む.txtファイルを検出可能です。glob.glob()でワイルドカードを使用する方法について、以下のサンプルコードで確認しましょう。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「glob.glob()」を使用して、Dataフォルダ内の「.txt」ファイルを検出する
file_list = glob.glob("Data\\*.txt")
# 取得したファイルリストを表示する
print(file_list)
# 「glob.glob()」を使用して、Dataフォルダ内で「Directory」を含むディレクトリを検出する
directory_list = glob.glob("Data\\Directory*")
# 取得したファイルリストを表示する
print(directory_list)
// 実行結果
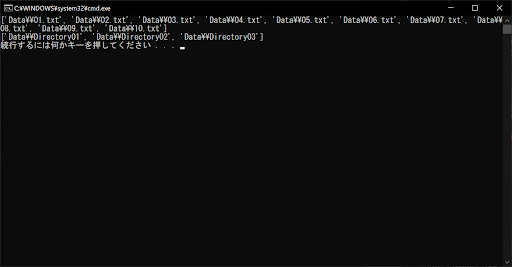
上記のサンプルプログラムでは、Dataフォルダ内のすべての.txtファイルと、「Directory」という文字列を含むディレクトリについて、glob.glob()関数で検出しています。ワイルドカードを使用しているため、条件に該当する複数のファイルやディレクトリが、リストに格納されていることがポイントです。
なお、特定のフォルダ内のすべてのファイルとディレクトリを抽出したい場合は、以下のサンプルコードのようにフォルダ名のあとにワイルドカードを置きましょう。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「glob.glob()」を使用して、Dataフォルダ内のすべてのファイルとディレクトリを検出する
list = glob.glob("Data\\*")
# 取得したファイルリストを表示する
print(list)
// 実行結果
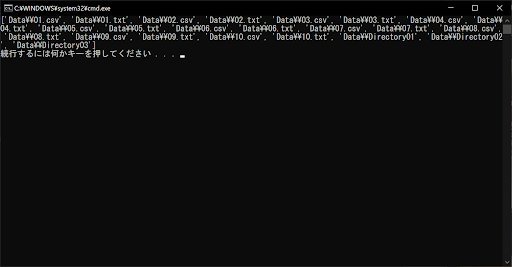
glob.glob()関数の引数を「”Data\\*”」としているため、Dataフォルダ内のあらゆるファイルとフォルダが検出されます。
深い階層の別のディレクトリのファイルを検出する
前述した手順で、glob.glob()関数で特定のフォルダ内のファイルとディレクトリをすべて検出できます。しかし、ディレクトリ内にサブディレクトリがある場合は、それ以降の階層にあるものを検出することはできません。
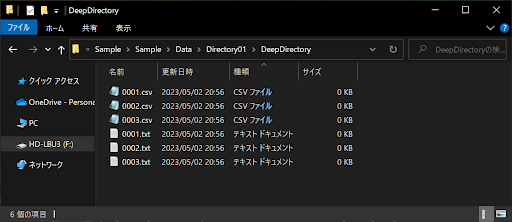
実際に先ほどの「Directory01フォルダ」に適当なファイルを追加し、さらに「DeepDirectory」フォルダも以下のような構造で作成しましょう。
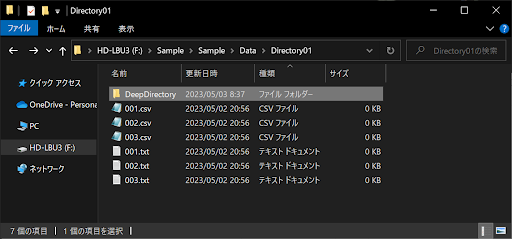
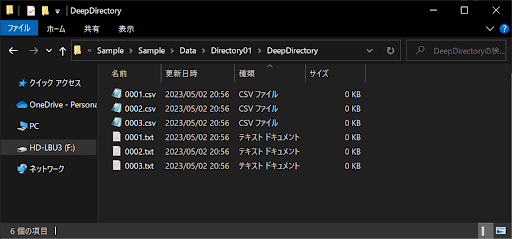
上記のようにディレクトリを多層構造にしたうえで、次のサンプルコードを実行してみてください。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「glob.glob()」を使用して、Dataフォルダ内のすべてのファイルとディレクトリを検出する
list = glob.glob("Data\\*")
# 取得したファイルリストを表示する
print(list)
// 実行結果
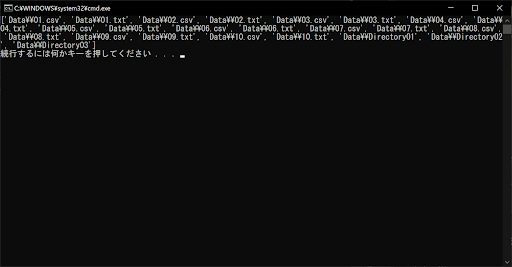
このように、サブディレクトリ「Directory01」の中にあるファイルやフォルダは、リストに含まれていません。これは、glob.glob()関数のデフォルト設定では、サブディレクトリの検出に必要な「再帰的(recursive)」な走査が行われないからです。
再帰的とは、同じ処理を何度も繰り返すことを指します。つまり、条件に合うファイル・ディレクトリの抽出処理を、再帰的に行う必要があるということです。glob.glob()関数では、以下のように「recursive引数」をTrueにすることで、一番深い階層のサブディレクトリまで検出することができます。
ファイルリスト = glob.glob("検出条件", recursive = True)
また検出条件でファイルパスを指定する際は、「**」を使う必要があることを覚えておきましょう。例えば、Dataディレクトリ内を再帰的に走査する場合は、「”Data\\**”」とします。こうすることで、Dataディレクトリを起点として、条件に該当するファイルのリストを最深部まで抽出することが可能です。詳細は以下のサンプルコードのとおりです。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「glob.glob()」を使用して、Dataフォルダ内のすべてのファイルとディレクトリを検出する
# 「recursive引数」をTrueにしているため、サブディレクトリもすべて再帰的に検出される
list = glob.glob("Data\\**", recursive = True)
# 取得したファイルリストを表示する
print(list)
// 実行結果
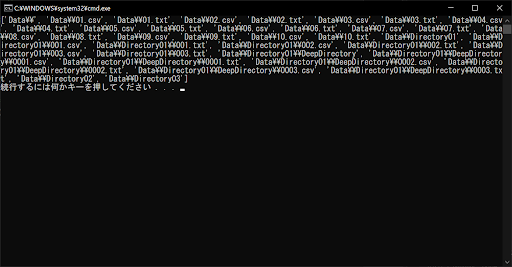
上記のサンプルプログラムでは、recursive引数をTrueにしたうえで、検出条件に「**」を付加しているため、サブディレクトリも含めたすべてのファイル・ディレクトリを抽出できています。
なお、Dataフォルダ内のすべての「.txt」ファイルを再帰的に抽出したい場合は、「”Data\\**\\*.txt”」とします。詳細は以下のサンプルコードのとおりです。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「glob.glob()」を使用して、Dataフォルダ内のすべての「.txtファイル」を抽出する
# 「recursive引数」をTrueにしているため、サブディレクトリもすべて再帰的に走査される
list = glob.glob("Data\\**\\*.txt", recursive = True)
# 取得したファイルリストを表示する
print(list)
// 実行結果
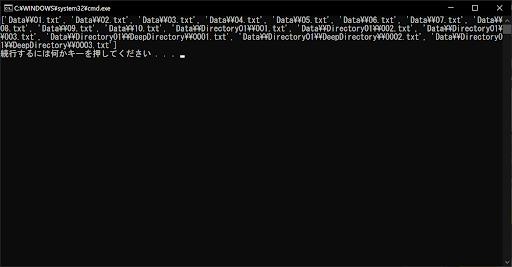
上記のサンプルプログラムは、すべての.txtファイルを最深部まで抽出したものです。ちなみに、「**」の部分は再帰処理の起点を示す記号なので、Dataディレクトリ直下のファイルも検出できます。
すべてのファイル名とディレクトリ名を個別に取得する
先ほど解説した再帰処理の手順で、すべてのファイル名とディレクトリ名を取得できます。しかし、それぞれを個別のリストに格納したいこともあるでしょう。その場合は以下のように、「os」ライブラリにある「os.path.isfile()」と「os.path.isdir()」を活用することで、個別のリストを作成することが可能です。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「os」ライブラリをインポートする
import os
# 「glob.glob()」を使用して、Dataフォルダ内のすべての「.txtファイル」を抽出する
# 「recursive引数」をTrueにしているため、サブディレクトリもすべて再帰的に走査される
list = glob.glob("Data\\**", recursive = True)
# ファイルとディレクトリのリストを用意する
file_list = []
directory_list = []
# 取得したリストをファイルとディレクトリに分割する
for x in list:
# ファイルの場合はファイルリストに追加する
if os.path.isfile(x):
file_list.append(x)
# ディレクトリの場合はディレクトリリストに追加する
if os.path.isdir(x):
directory_list.append(x)
# 取得したすべてのリストを表示する
print(f"すべてのリスト:{list}\n")
# 抽出したファイルリストを表示する
print(f"ファイルリスト:{file_list}\n")
# 抽出したディレクトリリストを表示する
print(f"ディレクトリリスト:{directory_list}\n")
// 実行結果
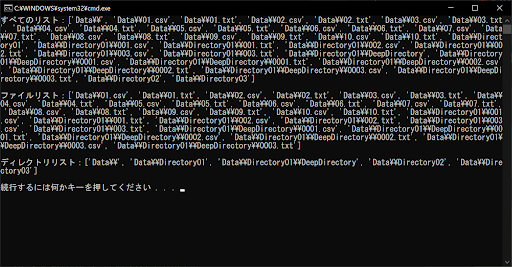
「os.path.isfile()」と「os.path.isdir()」は、いずれもファイルパスを判定する関数であり、前者はファイル名・後者はディレクトリ名であるかを判定します。
上記のサンプルプログラムでは、glob.glob()で取得したリストをforループで走査し、「os.path.isfile()」がTrueならファイルリスト、「os.path.isdir()」がTrueならディレクトリリストへ格納するものです。
ディレクトリ名を除いてファイル名のみ取得する
glob.glob()関数は、指定したディレクトリを起点としたファイルパスを格納します。つまり、ディレクトリ名まで含まれているのですが、純粋な「ファイル名」だけにしたいこともあるでしょう。その場合は、「os.path.split()」関数を以下のように使用することで、ファイル名だけのリストに加工できます。
# ディレクトリ名を取り除いたファイル名を格納するリスト ファイル名のリスト = [] # 抽出したファイルパスからディレクトリ名を取り除く # ちなみに、リストのインデックスを[0]にすると、ディレクトリ名になる for x in 抽出したファイルパスリスト: ファイル名のリスト.append(os.path.split(x)[1])
まずは、ファイル名のみを格納するためのリストを用意します。そのうえで、glob.glob()関数で抽出したファイルパスリストをforループで走査して、os.path.split()関数の引数に各要素を引き渡します。
その戻り値の1番目のインデックスをリストに格納すると、ファイル名のリストを作成可能です。ちなみに、インデックスを0番目にすると、ディレクトリ名の一覧となります。詳細は以下のサンプルコードのとおりです。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「os」ライブラリをインポートする
import os
# 「glob.glob()」を使用して、Dataフォルダ内のすべての「.txtファイル」を抽出する
# 「recursive引数」をTrueにしているため、サブディレクトリもすべて再帰的に走査される
filepath_list = glob.glob("Data\\**\\*.txt", recursive = True)
# 取得したファイルパスのリストを表示する
print(filepath_list)
# ディレクトリ名を取り除いたファイル名を格納するリスト
filename_list = []
# 抽出したファイルパスからディレクトリ名を取り除く
# ちなみに、リストのインデックスを[0]にすると、ディレクトリ名になる
for x in filepath_list:
filename_list.append(os.path.split(x)[1])
# 加工したファイル名のリストを表示する
print(filename_list)
// 実行結果
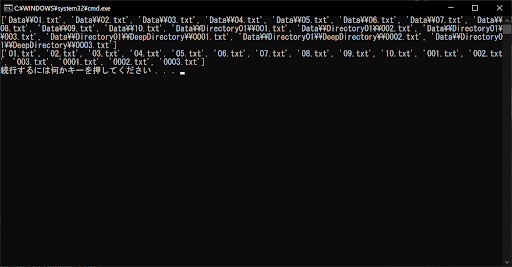
上記のサンプルプログラムは、glob.glob()のrecursive引数をTrueにして、Dataディレクトリを再帰的に走査して取得したリストから、ファイル名のみ抽出したものです。なお、ディレクトリ名はすべて削除されるため、サブディレクトリ内のファイルは階層関係が分かりづらくなってしまいます。
ちなみに、サンプルコードの「os.path.split(x)[1]」の部分は、「os.path.basename(x)」に書き換えることも可能です。os.path.basename()は、ファイルパスからファイル名のみ抽出する関数ですが、内部でos.path.split()を呼び出しているため結果的には同じ動作となります。
Pythonのglob.glob()関数で「パターンルール」を使う方法

Pythonのglob.glob()関数では、先ほど解説したようにワイルドカード「*」を使うことで、複数のファイルやフォルダをまとめて取得できます。実は、このワイルドカードは「メタ文字(特殊文字)」の一種であり、文字列のパターンを表現するためのものです。glob.glob()関数で使用できるパターンルールは以下の7種類です。
| メタ文字 | 意味 | 記述例 | 合致例 |
|---|---|---|---|
| * | 0文字以上の任意の文字を含む | a*.txt | a.txt aaa.txt abcde.txt |
| ? | 任意の1文字を含む | ?.txt | a.txt b.txt c.txt |
| [] | 括弧の中のいずれかの文字を含む | [xyz].txt | x.txt y.txt z.txt |
| [ – ] | 指定した範囲内の文字を含む | [0-9].txt | 1.txt 2.txt 3.txt |
| [!] | 括弧の中のいずれの文字も含まない | [!abc].txt | 1.txt 9.txt x.txt |
| [! – ] | 指定した範囲内の文字を含まない | [!1-3].txt | 0.txt 7.txt z.txt |
| ** | 再帰処理の起点となるディレクトリを指定する | 前述したとおりの挙動 | |
なお上記のメタ文字には、後述する「正規表現」で使用されるものもありますが、意味合いがまったく異なるので注意してください。また、glob.glob()関数のパターンルールの機能は限られているため、より複雑な抽出条件の設定が必要な場合は、正規表現を使用しましょう。簡易的な条件指定を行いたい場合は、glob.glob()関数のパターンルールが便利です。
ここからは、「*」「?」「[]」「[ – ]」「[!]」「[! – ]」の6種類のメタ文字・特殊文字の使い方について、サンプルコードを交えて解説します。なお、「**」については前述したとおりなので、そちらをご参照ください。まずは、「Dataフォルダ」に「Testディレクトリ」を追加して、以下のように多数の「.txtファイル」を作成しましょう。
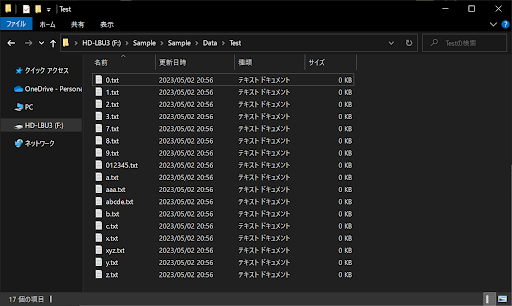
なお、ファイル名は1桁の数字・1文字のアルファベットを基本として、複数文字のものもいくつか挿入しましょう。
*|0文字以上の任意の文字を含む
「*」は、「0文字以上の任意の文字を含むかどうか」を調べるためのメタ文字です。glob.glob()の条件式に指定することで、どのような文字列であってもマッチするようになります。前述したように、この「*」はワイルドカードと呼ばれます。メタ文字「*」の使い方について、以下のサンプルコードで確認しましょう。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「glob.glob()」でパターンルールを使用して、該当するファイルのリストを作成する
list = glob.glob("Data\\Test\\a*.txt")
# 抽出したファイルリストを表示する
print(list)
// 実行結果
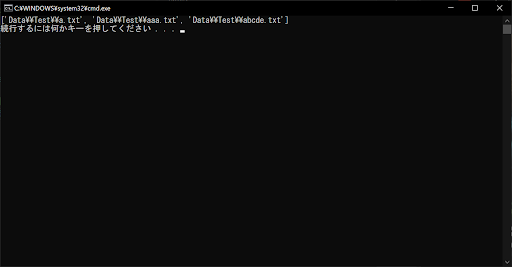
上記のサンプルプログラムでは、条件が「a*.txt」となっているため、aのあとに任意の文字が0個以上あるものが該当します。最初にaがあれば、そのあとがどのような文字列でもマッチします。
?|任意の1文字を含む
「?」は、「任意の1文字を含むかどうか」を調べるためのメタ文字です。glob.glob()の条件式に指定することで、どのような文字であっても1つあればマッチするようになります。
前述のワイルドカード「*」が0文字あるいは何文字でもOKなのに対し「?」は1文字のみ含まないといけないことがポイントです。「?」の使い方について、以下のサンプルコードで確認しましょう。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「glob.glob()」でパターンルールを使用して、該当するファイルのリストを作成する
list = glob.glob("Data\\Test\\?.txt")
# 抽出したファイルリストを表示する
print(list)
// 実行結果
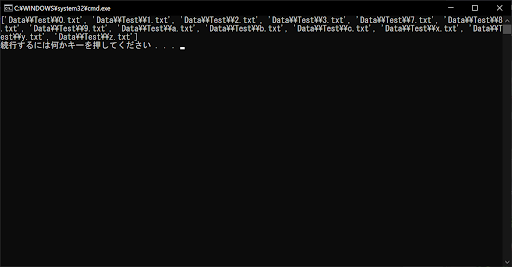
上記のサンプルプログラムでは、条件式が「?.txt」となっているため、実行結果のように任意の文字を1つだけ含むものがマッチします。
[]|括弧の中のいずれかの文字を含む
「[]」は、「括弧の中のいずれかの文字を含むかどうか」を調べるためのメタ文字です。>glob.glob()の条件式に指定することで、それらの文字を含むファイル名・ディレクト名を抽出できます。「[]」の使い方について、以下のサンプルコードで確認しましょう。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「glob.glob()」でパターンルールを使用して、該当するファイルのリストを作成する
list = glob.glob("Data\\Test\\[xyz].txt")
# 抽出したファイルリストを表示する
print(list)
// 実行結果
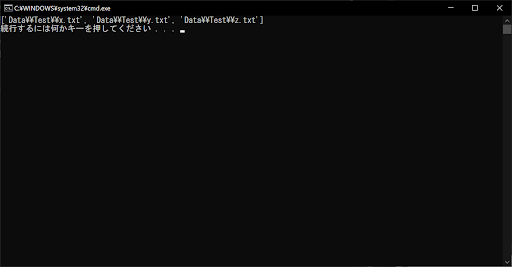
上記のサンプルプログラムでは、条件式が「[xyz].txt」となっているため、x・y・zのいずれかの文字を含むものがマッチします。条件式を「[123].txt」にすると、1・2・3のいずれかを含むファイル名・ディレクトリ名が抽出されます。
[ – ]|指定した範囲内の文字を含む
「[ – ]」は、「指定した範囲内の文字を含むかどうか」を調べるためのメタ文字です。glob.glob()の条件式に指定することで、その範囲内の文字を含むファイル名・ディレクト名を抽出できます。「[ – ]」の使い方について、以下のサンプルコードで確認しましょう。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「glob.glob()」でパターンルールを使用して、該当するファイルのリストを作成する
list = glob.glob("Data\\Test\\[0-9].txt")
# 抽出したファイルリストを表示する
print(list)
// 実行結果
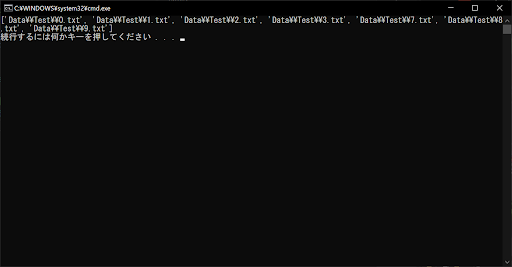
上記のサンプルプログラムでは、条件式が「[0-9].txt」となっているため、実行結果のように数字を1文字だけ含むものがマッチします。また条件式を「[a-z].txt」にすると、aからzのいずれかの文字を含むものがマッチするようになります。なお、glob.glob()の条件式では、大文字と小文字は区別されません。
[!]|括弧の中のいずれの文字も含まない
「[!]」は、「括弧の中のいずれの文字も含まないこと」を調べるためのメタ文字です。glob.glob()の条件式に指定することで、それらの文字を含まないファイル名・ディレクト名を抽出できます。「[!]」の使い方について、以下のサンプルコードで確認しましょう。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「glob.glob()」でパターンルールを使用して、該当するファイルのリストを作成する
list = glob.glob("Data\\Test\\[!abc].txt")
# 抽出したファイルリストを表示する
print(list)
// 実行結果
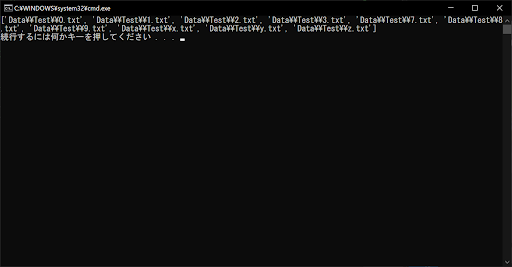
上記のサンプルプログラムでは、条件式が「[!abc].txt」となっているため、a・b・cいずれの文字も含まないものがマッチします。ちなみに、条件式を「[!123].txt」にすると、1・2・3以外の文字を1つ含むファイル名やディレクトリ名が抽出されます。
[! – ]|指定した範囲内の文字を含まない
「[! – ]」は、「指定した範囲内の文字を含まないこと」を調べるためのメタ文字です。glob.glob()の条件式に指定することで、その範囲内の文字を含まないファイル名・ディレクト名を抽出できます。「[! – ]」の使い方について、以下のサンプルコードで確認しましょう。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「glob.glob()」でパターンルールを使用して、該当するファイルのリストを作成する
list = glob.glob("Data\\Test\\[!1-3].txt")
# 抽出したファイルリストを表示する
print(list)
// 実行結果
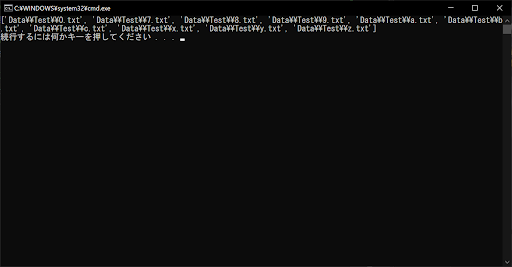
上記のサンプルプログラムでは、条件式が「[!1-3].txt」となっているため、実行結果のように1・2・3以外の文字を含むものがマッチします。ちなみに、条件式を「[x-z].txt」にすると、x・y・z以外の文字を含むファイル名やディレクトリ名が抽出されます。
Pythonの正規表現を使用したglob.glob()関数の応用法

前述したように、Pythonのglob.glob()関数では、「*」や「?」などのメタ文字によるパターンルールを使うことで、ある程度の条件指定ができます。しかし、より複雑な抽出条件を指定したい場合は、「正規表現」の利用が欠かせません。正規表現とは、文字列のパターンを示す表記法を指し、Pythonでは「reモジュール」で実装できます。
ただし、reモジュールで行う正式な正規表現は、前述したglob.glob()関数のパターンルールとはまったく異なるため、別物として学んでおく必要があります。そこで、reモジュールを使ったglob.glob()関数の応用テクニックについて、以下の7つのポイントからサンプルコード付きで解説します。
- re.match()関数の基本的な使い方
- 繰り返し回数を指定するための正規表現
- グループ単位で繰り返し回数を指定するための正規表現
- 文字の範囲を指定するための正規表現
- 文字の候補を指定するための正規表現
- 特殊シーケンスを用いた便利な正規表現
- 半角ASCII文字のファイル名・ディレクトリ名に限定する方法
re.match()関数の基本的な使い方
reライブラリは、正規表現を使用して、条件に当てはまる要素を抽出する機能を備えています。さまざまな関数がありますが、glob.glob()と組み合わせるときは、正確なマッチングができる「re.match()」関数を使うのが基本です。
具体的には、まずglob.glob()関数で引数に「**」と「recursive = True」を適用し、すべてのファイルとディレクトリを最深部まで抽出します。そのうえで、リストの全要素を「re.match()」関数で正規表現を使用した判定を行います。このようにすることで、glob.glob()単体では実現できない高度な処理が可能です。
# glob.glob()ですべてのファイルとサブディレクトリを抽出する
初期のリスト = glob.glob("起点ディレクトリ\\**", recursive = True)
# 最終的なリストを用意する
最終的なリスト = []
# 初期のリストに正規表現を適用する
for x in 初期のリスト:
# os.path.basename()でディレクトリ名を取り除く
base_name = os.path.basename(x)
# ファイル名に正規表現を適用し、結果が空でなければ最終的なリストに追加する
if re.match("正規表現", base_name):
最終的なリスト.append(base_name)
以上の流れでre.match()を使用すると、条件に合致する要素を正規表現で抽出できます。第1引数には正規表現、第2引数には対象文字列を指定します。戻り値には「マッチオブジェクト」が返りますが、その戻り値が空でない場合は「条件に合致する」ということなので、if文で判定してTrueである場合に新リストに追加すればOKです。
ちなみに、ファイル名やディレクトリ名を正確に抽出するためには、ディレクトリの階層情報を取り除いておく必要があります。そのため、正規表現の判定時にos.path.basename()を使用し、ファイル名やディレクトリ名の前のディレクトリ情報を削除することが大切です。最終的なリストにディレクトリ情報を残したい場合は、「append(base_name)」の部分を「append(x)」に置き換えてください。
なお、これから紹介するサンプルコードを実行するためには、先ほどの「Data\Test」ディレクトリにより多くのファイルを追加する必要があります。ファイル名については、アルファベットの「a」や「abc」を複数並べたもの、「@」や「[]」などの記号を並べたもの、日本語のみのものなどを用意してください。
繰り返し回数を指定するための正規表現
直前の文字の繰り返し回数を指定する正規表現には、以下の6種類があります。前述したglob.glob()関数にないものや、意味合いがまったく異なるものが多いので注意してください。
| 正規表現 | 意味 | 記述例 | 合致例 |
|---|---|---|---|
| * | 直前の文字が0回以上繰り返される | aa*.txt | a.txt aaa.txt abcba.txt |
| + | 直前の文字が1回以上繰り返される | aa+.txt | aa.txt aaa.txt aaaa.txt |
| ? | 直前の文字が0回もしくは1回繰り返される | aa?.txt | a.txt aa.txt |
| {m} | 直前の文字がm回繰り返される | a{1}.txt | a.txt |
| {m,} | 直前の文字がm回以上繰り返される | a{3}.txt | aaa.txt aaaa.txt aaaaa.txt |
| {m,n} | 直前の文字がm回以上・n回以下繰り返される | a{2,4}.txt | aa.txt aaa.txt aaaa.txt |
重要なポイントは、「*」と「+」の効果が「直前の文字に適用される」ことです。
glob.glob()関数では、直前の文字に関係なく、任意の文字という意味合いだったので注意してください。これらの記号がどのように機能するか、以下のサンプルコードで確認してみましょう。
//サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「os」ライブラリをインポートする
import os
# 「re」ライブラリをインポートする
import re
# get_file_list()|条件に該当する要素を正規表現で抽出する
def get_file_list(original_list, regex):
# 正規表現を適用したリストを用意する
final_list = []
# オリジナルのリストに正規表現を適用して抽出する
for x in original_list:
# os.path.basename()でディレクトリ名を取り除き、ファイル名のみで正規表現を適用する
base_name = os.path.basename(x)
# ファイル名に正規表現を適用し、結果が空でなければ最終的なリストに追加する
if re.match(regex, base_name):
# ディレクトリ名も含めたい場合は、「base_name」を「x」に置き換えればOK
# 今回のサンプルコードでは、実行結果が長くなりすぎないようにするため、ファイル名のみ表示しています
final_list.append(base_name)
# 抽出したリストを戻り値として返す
return final_list
# main()|プログラムのエントリーポイント
if __name__ == "__main__":
# 「glob.glob()」を使用して、Dataフォルダ内のすべてのファイルとディレクトリを抽出する
# 「recursive引数」をTrueにしているため、サブディレクトリもすべて再帰的に走査される
original_list = glob.glob("Data\\**", recursive = True)
# 取得したファイルリストを表示する
print(f"{original_list}\n")
# 正規表現「"aa*.txt"」で抽出したリストを取得する
# aのあとにaが0回以上あればOK
final_list = get_file_list(original_list, "aa*.txt")
print("「aa*.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"aa+.txt"」で抽出したリストを取得する
# aのあとにaが1回以上あればOK
final_list = get_file_list(original_list, "aa+.txt")
print("「aa+.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"aa?.txt"」で抽出したリストを取得する
# aのあとにaが0回もしくは1回あればOK
final_list = get_file_list(original_list, "aa?.txt")
print("「aa?.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"a{1}.txt"」で抽出したリストを取得する
# aが1回だけあればOK
final_list = get_file_list(original_list, "a{1}.txt")
print("「a{1}.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"a{3,}.txt"」で抽出したリストを取得する
# aが3回以上あればOK
final_list = get_file_list(original_list, "a{3,}.txt")
print("「a{3,}.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"a{2,4}.txt"」で抽出したリストを取得する
# aが2回以上4回以下あればOK
final_list = get_file_list(original_list, "a{2,4}.txt")
print("「a{2,4}.txt」の抽出結果:" + str(final_list) + "\n")
//実行結果
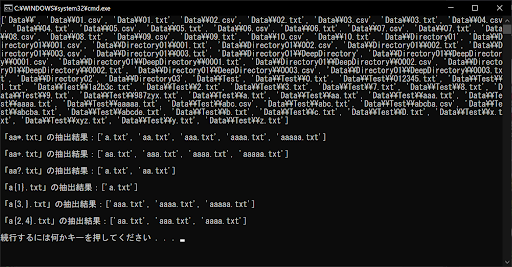
同じ処理を複数回繰り返すため、re.match()の呼び出しやリスト生成など、正規表現による抽出処理はget_file_list()関数でまとめています。glob.glob()とreモジュールを組み合わせる場合は、forループによる新しいリストの作成などでソースコードが長くなるため、基本的にはこうした関数を作成することをおすすめします。
「aa*.txt」「aa+.txt」「aa?.txt」の3つに注意が必要です。いずれも最初のaのあとに、aが何回あるかを判定します。「aa*.txt」と「aa?.txt」は0回も許容されるため、「a.txt」もマッチします。一方、「aa+.txt」はaのあとにaが1回以上ないといけないため、「a.txt」はマッチしません。
「a{1}.txt」「a{3,}.txt」「a{2,4}.txt」の3つについては、構文によって意味合いが変わります。コンマのあとに何も書かなければ直前の数値以上の回数、数値を書くと最低回数・最高回数を設定することが可能です。これらの繰り返し構文は、ファイル名やディレクトリ名の抽出で多用するので、ぜひ覚えておきましょう。
グループ単位で繰り返し回数を指定するための正規表現
前述した「繰り返し回数を指定する正規表現」は、直前の1文字のみ対象となります。しかし、一連の文字列を対象として、その繰り返しを判定したいこともあるでしょう。その場合は以下の正規表現を使うことで、グループ単位で繰り返し回数を指定できます。
| 正規表現 | 意味 | 記述例 | 合致例 |
|---|---|---|---|
| ( ) | 指定した文字列をグループ化する | (abc){2,4}.txt | abcabc.txt abcabcabc.txt abcabcabcabc.txt |
丸カッコで囲った文字列はグループ化され、そのあとに前述した「*」「+」「?」などの繰り返し表現を使用すると、文字列の繰り返しパターンを判定することが可能です。この正規表現がどのように機能するか、以下のサンプルコードで確認してみましょう。
//サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「os」ライブラリをインポートする
import os
# 「re」ライブラリをインポートする
import re
# get_file_list()|条件に該当する要素を正規表現で抽出する
def get_file_list(original_list, regex):
# 正規表現を適用したリストを用意する
final_list = []
# オリジナルのリストに正規表現を適用して抽出する
for x in original_list:
# os.path.basename()でディレクトリ名を取り除き、ファイル名のみで正規表現を適用する
base_name = os.path.basename(x)
# ファイル名に正規表現を適用し、結果が空でなければ最終的なリストに追加する
if re.match(regex, base_name):
# ディレクトリ名も含めたい場合は、「base_name」を「x」に置き換えればOK
# 今回のサンプルコードでは、実行結果が長くなりすぎないようにするため、ファイル名のみ表示しています
final_list.append(base_name)
# 抽出したリストを戻り値として返す
return final_list
# main()|プログラムのエントリーポイント
if __name__ == "__main__":
# 「glob.glob()」を使用して、Dataフォルダ内のすべてのファイルとディレクトリを抽出する
# 「recursive引数」をTrueにしているため、サブディレクトリもすべて再帰的に走査される
original_list = glob.glob("Data\\**", recursive = True)
# 取得したファイルリストを表示する
print(f"{original_list}\n")
# 正規表現「"abc(abc)*.txt"」で抽出したリストを取得する
# abcのあとにabcが0回以上あればOK
final_list = get_file_list(original_list, "abc(abc)*.txt")
print("「abc(abc)*.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"abc(abc)+.txt"」で抽出したリストを取得する
# abcのあとにabcが1回以上あればOK
final_list = get_file_list(original_list, "abc(abc)+.txt")
print("「abc(abc)+.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"abc(abc)?.txt"」で抽出したリストを取得する
# abcのあとにabcが0回もしくは1回あればOK
final_list = get_file_list(original_list, "abc(abc)?.txt")
print("「abc(abc)?.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"(abc){1}.txt"」で抽出したリストを取得する
# abcが1回だけあればOK
final_list = get_file_list(original_list, "(abc){1}.txt")
print("「(abc){1}.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"(abc){3,}.txt"」で抽出したリストを取得する
# abcが3回以上あればOK
final_list = get_file_list(original_list, "(abc){3,}.txt")
print("「(abc){3,}.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"(abc){2,4}.txt"」で抽出したリストを取得する
# abcが2回以上4回以下あればOK
final_list = get_file_list(original_list, "(abc){2,4}.txt")
print("「(abc){2,4}.txt」の抽出結果:" + str(final_list) + "\n")
//実行結果
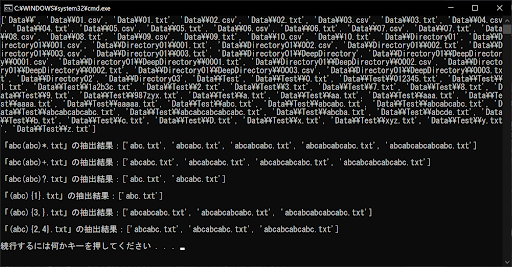
繰り返し回数を指定する正規表現の動作自体は、先ほどのサンプルコードと同じものです。しかし、「abc」という文字列をグループ化して、その繰り返し回数を判定していることがポイントです。自動生成したファイル名やディレクトリ名などを抽出する際に、このグループ化が役立つことがあるでしょう。
文字の候補を指定するための正規表現
文字列をグループ化するのではなく、特定の文字のいずれかを含むファイル名やディレクトリ名を抽出したいケースもあります。その場合は、以下の2つの正規表現を活用することで、文字列の候補を指定できます。
| 正規表現 | 意味 | 記述例 | 合致例 |
|---|---|---|---|
| (|) | 指定した文字のいずれかを含む | (0|a|x).txt | 0.txt a.txt x.txt |
| [ ] | 指定した文字のいずれかを含む | [0123].txt | 0.txt 1.txt 2.txt 3.txt |
「(|)」と「[ ]」は書き方は異なりますが、どちらも同じ結果が得られます。ただし、文字列の候補を指定する場合は、前者の「(|)」でないと動作しないため注意してください。これらの記号がどう機能するかについて、以下のサンプルコードで確認してみましょう。
//サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「os」ライブラリをインポートする
import os
# 「re」ライブラリをインポートする
import re
# get_file_list()|条件に該当する要素を正規表現で抽出する
def get_file_list(original_list, regex):
# 正規表現を適用したリストを用意する
final_list = []
# オリジナルのリストに正規表現を適用して抽出する
for x in original_list:
# os.path.basename()でディレクトリ名を取り除き、ファイル名のみで正規表現を適用する
base_name = os.path.basename(x)
# ファイル名に正規表現を適用し、結果が空でなければ最終的なリストに追加する
if re.match(regex, base_name):
# ディレクトリ名も含めたい場合は、「base_name」を「x」に置き換えればOK
# 今回のサンプルコードでは、実行結果が長くなりすぎないようにするため、ファイル名のみ表示しています
final_list.append(base_name)
# 抽出したリストを戻り値として返す
return final_list
# main()|プログラムのエントリーポイント
if __name__ == "__main__":
# 「glob.glob()」を使用して、Dataフォルダ内のすべてのファイルとディレクトリを抽出する
# 「recursive引数」をTrueにしているため、サブディレクトリもすべて再帰的に走査される
original_list = glob.glob("Data\\**", recursive = True)
# 取得したファイルリストを表示する
print(f"{original_list}\n")
# 正規表現「"(0|a|x).txt"」で抽出したリストを取得する
# 「0」「a」「x」のいずれかを1文字だけ含んでいればOK
final_list = get_file_list(original_list, "(0|a|x).txt")
print("「(0|a|x).txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"[0123].txt"」で抽出したリストを取得する
# 「0」「1」「2」「3」のいずれかを1文字だけ含んでいればOK
final_list = get_file_list(original_list, "[0123].txt")
print("「[0123].txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"[0123]*.(txt|csv)"」で抽出したリストを取得する
# 「0」「1」「2」「3」のいずれかを0回以上含み、なおかつ拡張子が「txt」または「csv」であればOK
final_list = get_file_list(original_list, "[0123]*.(txt|csv)")
print("「[0123]*.(txt|csv)」の抽出結果:" + str(final_list) + "\n")
//実行結果
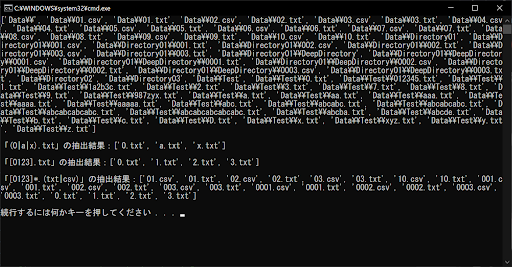
「(0|a|x).txt」は、0・a・xのいずれかを1文字だけ含む.txtファイルがマッチします。これは「[0ax].txt」と書き換えることができます。同様に、「[0123].txt」は0・1・2・3のいずれかを1文字含めばOKですが、「(0|1|2|3).txt」と書き換えることも可能です。
「[0123]*.(txt|csv)」は、両者を組み合わせた応用テクニックとなり、0・1・2・3のいずれかを0回以上含み、なおかつ拡張子が「txt」または「csv」であればマッチします。0・1・2・3以外の文字を含む場合や、拡張子がtxtやcsv以外の場合は該当しません。
このように、reモジュールの正規表現を組み合わせると、ファイル名・ディレクトリ名の高度な抽出が可能となるので、ぜひいろいろなパターンを試してみてください。
文字の範囲を指定するための正規表現
前述した「(|)」や「[ ]」で、抽出対象の文字を絞り込むことが可能です。しかし、まとまった範囲の文字や数字などを指定して、該当するファイル名やディレクトリ名を抽出したいこともあるでしょう。その場合は、以下のような正規表現を活用することで、柔軟な条件を指定できます。
| 正規表現 | 意味 | 記述例 | 合致例 |
|---|---|---|---|
| [0-9] | すべての数字 | [0-9]*.txt | 01.txt 05.txt 09.txt |
| [^0-9] | すべての数字以外 | [^0-9]*.txt | a.txt z.txt Sample File.txt |
| [a-zA-Z] | すべてのアルファベット | [a-zA-Z]*.txt | a.txt b.txt c.txt |
| [^a-zA-Z] | すべてのアルファベット以外 | [^a-zA-Z]*.txt | 01.txt 09.txt サンプルファイル.txt |
| [a-zA-Z0-9] | アルファベットと英数字 | [a-zA-Z0-9]*.txt | 01.txt a.txt abc.txt |
| [^a-zA-Z0-9] | アルファベットと英数字以外 | [^a-zA-Z0-9]*.txt | @[@]@.txt サンプルファイル.txt |
重要なポイントは、指定したい範囲の「最初」と「最後」をハイフンでつなぐことです。複数の範囲を指定する場合は、単に並べるだけでOKです。また、キャレット記号「^」を先頭につけると、集合の全体を否定することができます。これらの正規表現がどう機能するか、以下のサンプルコードで確認しましょう。
//サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「os」ライブラリをインポートする
import os
# 「re」ライブラリをインポートする
import re
# get_file_list()|条件に該当する要素を正規表現で抽出する
def get_file_list(original_list, regex):
# 正規表現を適用したリストを用意する
final_list = []
# オリジナルのリストに正規表現を適用して抽出する
for x in original_list:
# os.path.basename()でディレクトリ名を取り除き、ファイル名のみで正規表現を適用する
base_name = os.path.basename(x)
# ファイル名に正規表現を適用し、結果が空でなければ最終的なリストに追加する
if re.match(regex, base_name):
# ディレクトリ名も含めたい場合は、「base_name」を「x」に置き換えればOK
# 今回のサンプルコードでは、実行結果が長くなりすぎないようにするため、ファイル名のみ表示しています
final_list.append(base_name)
# 抽出したリストを戻り値として返す
return final_list
# main()|プログラムのエントリーポイント
if __name__ == "__main__":
# 「glob.glob()」を使用して、Dataフォルダ内のすべてのファイルとディレクトリを抽出する
# 「recursive引数」をTrueにしているため、サブディレクトリもすべて再帰的に走査される
original_list = glob.glob("Data\\**", recursive = True)
# 取得したファイルリストを表示する
print(f"{original_list}\n")
# 正規表現「"[0-9]*.txt"」で抽出したリストを取得する
# いずれかの数字を含んでいればOK
final_list = get_file_list(original_list, "[0-9]*.txt")
print("「[0-9]*.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"[^0-9]*.txt"」で抽出したリストを取得する
# すべての数字を含んでいなければOK
final_list = get_file_list(original_list, "[^0-9]*.txt")
print("「[^0-9]*.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"[a-zA-Z]*.txt"」で抽出したリストを取得する
# いずれかのアルファベットを含んでいればOK
final_list = get_file_list(original_list, "[a-zA-Z]*.txt")
print("「[a-zA-Z]*.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"[^a-zA-Z]*.txt"」で抽出したリストを取得する
# すべてのアルファベットを含んでいなければOK
final_list = get_file_list(original_list, "[^a-zA-Z]*.txt")
print("「[^a-zA-Z]*.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"[a-zA-Z0-9]*.txt"」で抽出したリストを取得する
# いずれかの英数字を含んでいればOK
final_list = get_file_list(original_list, "[a-zA-Z0-9]*.txt")
print("「[a-zA-Z0-9]*.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"[^a-zA-Z0-9]*.txt"」で抽出したリストを取得する
# すべての英数字を含んでいなければOK
final_list = get_file_list(original_list, "[^a-zA-Z0-9]*.txt")
print("「[^a-zA-Z0-9]*.txt」の抽出結果:" + str(final_list) + "\n")
//実行結果
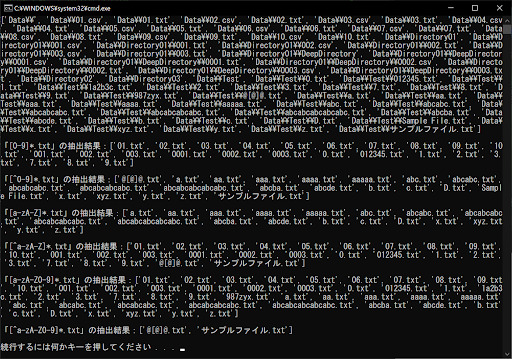
いずれの条件にも「*」を付けているため、直前の条件を満たす文字が0個以上ある場合に該当します。例えば「[0-9]*.txt」の場合は、「01.txt」「003.txt」「012345.txt」など、数字が含まれているものであればOKです。
「[^0-9]*.txt」と「[a-zA-Z]*.txt」は同じ結果になるように思われるかもしれませんが、「[^0-9]*.txt」は数字以外なので、アルファベット以外の空白や日本語なども含まれます。「[0-9]*.txt」と「[^a-zA-Z]*.txt」の違いも同様です。
最後の「[^a-zA-Z0-9]*.txt」は、半角英数字の集合の否定となります。これは、半角英数字以外の記号や日本語などの文字が対象となるため、サンプル用のディレクトリ構造では「@[@]@.txt」と「サンプルファイル.txt」しか該当しません。
特殊シーケンスを用いた便利な正規表現
「[0-9]」や「[a-zA-Z]」などの正規表現で、数字や文字をまとめて指定できます。しかし、こうした記法はソースコードが長くなったり、ミスの原因になったりすることもあります。また「すべての文字や数字」など、さらに広い範囲で指定したいケースもあるでしょう。そのような場合は、以下のような「特殊シーケンス」で簡潔な範囲指定が可能となります。
| 正規表現 | 意味 | 記述例 | 合致例 |
|---|---|---|---|
| \d | すべての数字 | \d*.txt | 1.txt 001.txt 012345.txt |
| \D | すべての数字以外 | \D*.txt | a.txt abc.txt サンプルファイル.txt |
| \w | すべての文字や数字 | \w*.txt | 01.txt abc.txt サンプルファイル.txt |
| \W | すべての文字や数字以外 | \W*.txt | @[@]@.txt |
| \s | 空白 | \w*\s\w*.txt | Sample File.txt |
| \S | 空白以外 | \S*.txt | 001.txt xyz.txt サンプルファイル.txt |
特殊シーケンスを使うと、ソースコードを簡潔化できます。ただし、それぞれの意味を理解していなければ、正常に動作しないので注意が必要です。例えば、大文字と小文字で真逆の意味になることや、「\w」は英数字以外の日本語なども対象になることです。これらの正規表現の使い方について、以下のサンプルコードで実際に確認してみましょう。
//サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「os」ライブラリをインポートする
import os
# 「re」ライブラリをインポートする
import re
# get_file_list()|条件に該当する要素を正規表現で抽出する
def get_file_list(original_list, regex):
# 正規表現を適用したリストを用意する
final_list = []
# オリジナルのリストに正規表現を適用して抽出する
for x in original_list:
# os.path.basename()でディレクトリ名を取り除き、ファイル名のみで正規表現を適用する
base_name = os.path.basename(x)
# ファイル名に正規表現を適用し、結果が空でなければ最終的なリストに追加する
if re.match(regex, base_name):
# ディレクトリ名も含めたい場合は、「base_name」を「x」に置き換えればOK
# 今回のサンプルコードでは、実行結果が長くなりすぎないようにするため、ファイル名のみ表示しています
final_list.append(base_name)
# 抽出したリストを戻り値として返す
return final_list
# main()|プログラムのエントリーポイント
if __name__ == "__main__":
# 「glob.glob()」を使用して、Dataフォルダ内のすべてのファイルとディレクトリを抽出する
# 「recursive引数」をTrueにしているため、サブディレクトリもすべて再帰的に走査される
original_list = glob.glob("Data\\**", recursive = True)
# 取得したファイルリストを表示する
print(f"{original_list}\n")
# 正規表現「"\d*.txt"」で抽出したリストを取得する
# いずれかの数字を含んでいればOK
final_list = get_file_list(original_list, "\d*.txt")
print("「\d*.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"\D*.txt"」で抽出したリストを取得する
# すべての数字を含んでいなければOK
final_list = get_file_list(original_list, "\D*.txt")
print("「\D*.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"\w*.txt"」で抽出したリストを取得する
# いずれかの文字や数字を含んでいればOK
final_list = get_file_list(original_list, "\w*.txt")
print("「\w*.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"\W*.txt"」で抽出したリストを取得する
# すべての文字や数字を含んでいなければOK
final_list = get_file_list(original_list, "\W*.txt")
print("「\W*.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"\w*\s\w*.txt"」で抽出したリストを取得する
# 文字列の間に空白を含んでいればOK
final_list = get_file_list(original_list, "\w*\s\w*.txt")
print("「\w*\s\w*.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"\S*.txt"」で抽出したリストを取得する
# いっさいの空白がなければOK
final_list = get_file_list(original_list, "\S*.txt")
print("「\S*.txt」の抽出結果:" + str(final_list) + "\n")
//実行結果
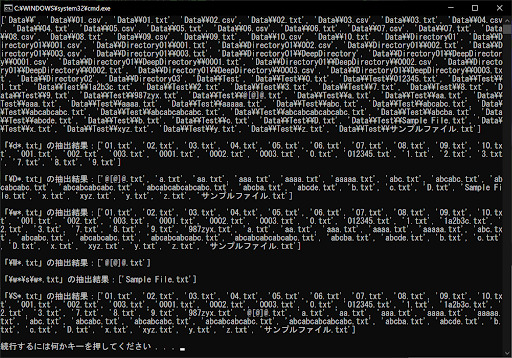
「\d*.txt」は先ほどの「[0-9]」、「\D*.txt」は「[^0-9]」と同じ結果が得られます。一方で、「\w*.txt」や「\W*.txt」は、英数字以外のすべての文字が対象となるため、ほかの表現への置き換えは困難です。
なお、「\W*.txt」はすべての文字以外を対象とするため、基本的には「@」や「[]」のような記号しか該当しないようになります。「\w*\s\w*.txt」は、文字列の間にスペースやタブなどの「空白」を含むものが対象となり、「\S*.txt」は空白を含まないものがマッチします。
重要なポイントは、「\w*.txt」がASCII文字のような「半角文字(シングルバイト文字)」だけではなく、日本語や中国語などのような「全角文字(マルチバイト文字)」も含むことです。半角英数字に限定したい場合は、後述する「フラグ引数」を利用しましょう。
半角ASCII文字のファイル名・ディレクトリ名に限定する方法
特殊シーケンスの「\w」は、日本語などの「全角文字(マルチバイト文字)」も該当するため、ファイル名・ディレクトリ名を正確に抽出できないことがあります。そこで、re.match()の第3引数に「re.ASCIIフラグ」を指定することで、半角ASCII文字のファイル名・ディレクトリ名のみ抽出できるようになります。
//サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「os」ライブラリをインポートする
import os
# 「re」ライブラリをインポートする
import re
# get_file_list()|条件に該当する要素を正規表現で抽出する
def get_file_list(original_list, regex, flag = False):
# 正規表現を適用したリストを用意する
final_list = []
# re.match()関数のフラグを設定する
# flag引数がTrueであればre.ASCIIに変更する
flag = 0 if flag == False else re.ASCII
# オリジナルのリストに正規表現を適用して抽出する
for x in original_list:
# os.path.basename()でディレクトリ名を取り除き、ファイル名のみで正規表現を適用する
base_name = os.path.basename(x)
# ファイル名に正規表現を適用し、結果が空でなければ最終的なリストに追加する
# 第3引数にフラグ(re.ASCII)を引き渡すと、ASCII文字限定でマッチングが行われる
if re.match(regex, base_name, flag):
# ディレクトリ名も含めたい場合は、「base_name」を「x」に置き換えればOK
# 今回のサンプルコードでは、実行結果が長くなりすぎないようにするため、ファイル名のみ表示しています
final_list.append(base_name)
# 抽出したリストを戻り値として返す
return final_list
# main()|プログラムのエントリーポイント
if __name__ == "__main__":
# 「glob.glob()」を使用して、Dataフォルダ内のすべてのファイルとディレクトリを抽出する
# 「recursive引数」をTrueにしているため、サブディレクトリもすべて再帰的に走査される
original_list = glob.glob("Data\\**", recursive = True)
# 取得したファイルリストを表示する
print(f"{original_list}\n")
# 正規表現「"\w{6,}.txt"」で抽出したリストを取得する
# いずれかの文字や数字を6文字以上含んでいればOK
final_list = get_file_list(original_list, "\w{6,}.txt")
print("「\w{6,}.txt」の抽出結果:" + str(final_list) + "\n")
# 正規表現「"\w{6,}.txt"」で抽出したリストを取得する
# いずれかの文字や数字を6文字以上含んでいればOK
# ただし「re.ASCIIフラグ」を指定しているため、半角英数字しかマッチしない
final_list = get_file_list(original_list, "\w{6,}.txt", re.ASCII)
print("「\w{6,}.txt」の抽出結果:" + str(final_list) + "\n")
//実行結果
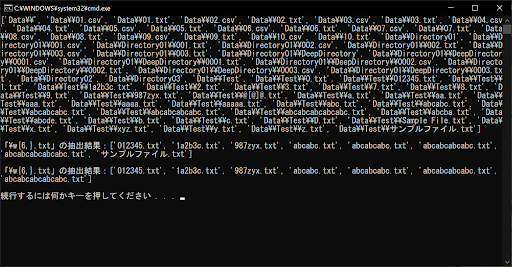
今回のサンプルプログラムでは、get_file_list()に「flag引数」を追加しています。ここをTrueにすることで、re.match()関数に「re.ASCII」が引き渡されるようになります。正規表現は「\w{6,}.txt」なので、文字や数字を6つ以上含む.txtファイルが対象です。
ただし、「\w」はASCII文字以外も対象となるため、日本語の「サンプルファイル.txt」も含まれてしまいます。「OpenCV」などの外部ライブラリを使用する際は、ファイルパスに日本語が含まれていると不具合が生じる可能性があるので注意が必要です。そのため、ファイルパスをASCII文字に限定するほうが、都合がいいケースもあります。
上記のサンプルプログラムのように、re.match()関数の第3引数にre.ASCIIを指定することで、日本語などのマルチバイト文字のファイル名・ディレクトリ名を除外可能です。
Pythonのglob.glob()関数の応用法

Pythonのglob.glob()関数の応用法として、以下の4つのポイントを解説します。
- 大文字を小文字を区別しない条件判定を行う
- 任意の文字を示す「.」と終端を示す「$」
- ディレクトリ名も含めて正規表現を適用する
- 適切な形式のファイルのみ読み込んでデータを表示する
大文字を小文字を区別しない条件判定を行う
Pythonのreモジュールは厳格な判定を行う「正規表現」なので、条件式の大文字と小文字は区別されます。そのため、正規表現で「[ABC]*.txt」と記載したら、小文字のa・b・cは対象外となります。
これを区別しない「Case Insensitive」な判定を行いたい場合は、re.match()の第3引数に「re.IGNORECASE」を指定しましょう。詳細は以下のサンプルコードのとおりです。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「os」ライブラリをインポートする
import os
# 「re」ライブラリをインポートする
import re
# 「glob.glob()」を使用して、Dataフォルダ内のすべてのファイルとディレクトリを取得する
# 「recursive引数」をTrueにしているため、サブディレクトリもすべて再帰的に走査される
original_list = glob.glob("Data\\**", recursive = True)
# 正規表現を適用したリストを用意する
final_list = []
# オリジナルのリストに正規表現を適用して抽出する
for x in original_list:
# os.path.basename()でファイル名を取得する
base_name = os.path.basename(x)
# A・B・Cいずれかの文字で構成された.txtファイルを取得する
# 第3引数に「re.IGNORECASE」を指定しているため、大文字と小文字の区別が行われない
# 「re.ASCII | re.IGNORECASE」のように「|」でつなげると両立できる
if re.match("[ABC]*.txt", base_name, re.ASCII | re.IGNORECASE):
# ファイル名やディレクトリ名をリストに格納する
final_list.append(x)
# 正規表現を適用して抽出したリストを表示する
print(final_list)
// 実行結果
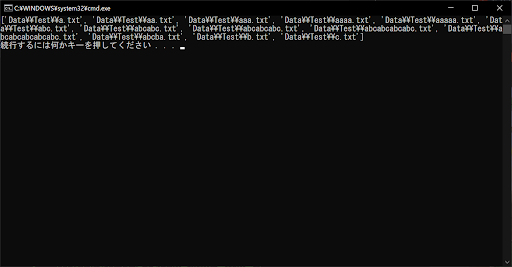
上記のサンプルプログラムは、ファイル名が大文字のABCいずれかのみで構成された、.txtファイルを抽出するものです。
しかし、re.match()の第3引数に「re.IGNORECASE」を指定しているため、小文字のabcもマッチするようになっています。re.ASCIIと両立させたい場合は、「re.ASCII | re.IGNORECASE」としましょう。なお、「re.IGNORECASE」の部分を削除すると、マッチするファイル数はゼロとなります。
任意の文字を示す「.」と終端を示す「$」
先ほどは「ファイル名」に正規表現を適用して、該当するファイルを抽出する方法を紹介しました。しかし、ファイルパスを全体的に判定して、ファイルを抽出しないといけないケースもあります。その場合は、任意の文字を示す「.」と、終端を示す「$」のメタ文字も必要です。
「.」は「*」と組み合わせて「.*」にすると、「任意の文字列」を表現できます。re.match()関数は文字列の先端から判定するため、最初の部分を曖昧にしたいときに便利です。また、「どの文字で終わるか」を厳格にしたい場合は、最後のメタ文字のあとに「$」をつけましょう。
ちなみに、文字列の先端は「^」で指定できますが、文字列の先端から判定するre.match()関数では使用する必要はありません。詳細を以下のサンプルコードで確認しましょう。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「os」ライブラリをインポートする
import os
# 「re」ライブラリをインポートする
import re
# 「glob.glob()」を使用して、Dataフォルダ内のすべてのファイルとディレクトリを取得する
# 「recursive引数」をTrueにしているため、サブディレクトリもすべて再帰的に走査される
original_list = glob.glob("Data\\**", recursive = True)
# 正規表現を適用したリストを用意する
final_list = []
# オリジナルのリストに正規表現を適用して抽出する
for x in original_list:
# os.path.basename()でファイル名を取得する
base_name = os.path.basename(x)
# 任意の文字列が0個以上続いたあと、1つ以上の数字で終わるファイル・ディレクトリを抽出する
# 最初の「.*」がなければ何もマッチせず、最後の「$」がなければ数字で終わらないものもマッチする
if re.match(".*\d+$", x, re.ASCII):
# ファイル名やディレクトリ名をリストに格納する
final_list.append(base_name)
# 正規表現を適用して抽出したリストを表示する
print(final_list)
// 実行結果
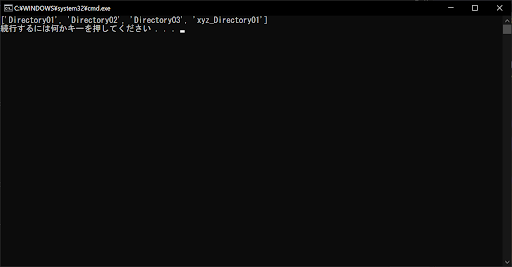
正規表現の「.*\d+$」は、「任意の文字列が0個以上続いたあと、1つ以上の数字で終わる」という意味です。しかし、最初の「.*」がなければ、任意の文字列ではなく数字で始まるものに限定されるため、マッチするものが何もありません。
最後の「$」を省略すると、ファイル名やディレクトリ名の「終わり方」を指定しない形になるため、以下のように大量のファイルが該当します。
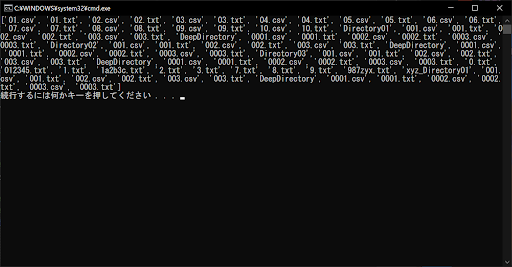
これまでのサンプルコードでは、os.path.basename()関数でファイル名のみ取得していたので、始まり方や終わり方について厳密に指定する必要はありませんでした。しかし、ファイルパス全体を正規表現で解析したい場合は、このように詳細な記載が必要となります。
ディレクトリ名も含めて正規表現を適用する
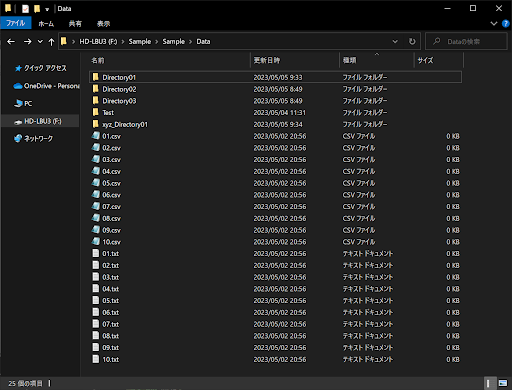
さまざまなファイルを管理する場合は、「特定ディレクトリのファイルのみの抽出」が必要なことがあります。その際は、ディレクトリ名とファイル名を個別に判定するとOKです。まずは、以下のような「Directory01フォルダ」の中身を、「Directory02」と「Directory03」にもコピーしてください。
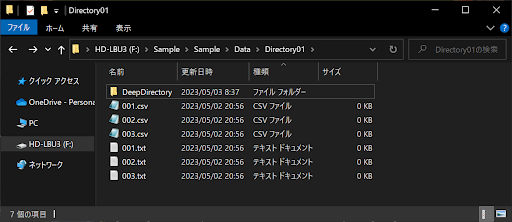
さらに、「Directory01フォルダ」をコピーして「xyz_Directory01」というディレクトリ名に変更し、以下のような構造にしたうえでサンプルコードを実行してみましょう。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「os」ライブラリをインポートする
import os
# 「re」ライブラリをインポートする
import re
# 「glob.glob()」を使用して、Dataフォルダ内のすべてのファイルとディレクトリを取得する
# 「recursive引数」をTrueにしているため、サブディレクトリもすべて再帰的に走査される
original_list = glob.glob("Data\\**", recursive = True)
# 正規表現を適用したリストを用意する
final_list = []
# オリジナルのリストに正規表現を適用して抽出する
for x in original_list:
# os.path.dirname()でディレクトリ名を取得する
directory_name = os.path.dirname(x)
# os.path.basename()でファイル名を取得する
base_name = os.path.basename(x)
# ディレクトリ名を判定する
# 「.*\\\\Directory\d+$」で、Directory + 数字1つ以上のディレクトリを取得する
# 最初の「.*」がなければ、ディレクトリが「Directory」で始まらない限りマッチしない
# 「.*\\\\Directory\d*$」にしたり、最後の「$」がなかったりすると、「DeepDirectory」も含まれてしまう
# また、「\\\\」がなかったり「\\」にしたりすると、余分な「xyz_Directory01」が含まれてしまう
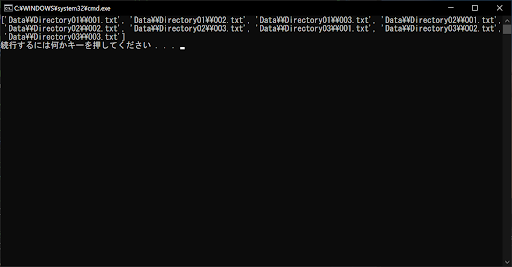
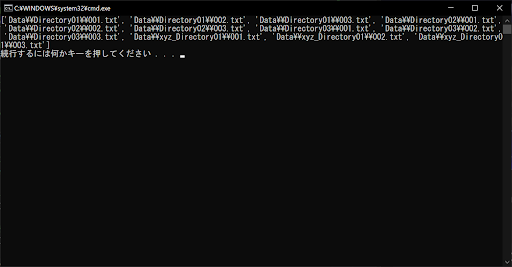
if re.match(".*\\\\Directory\d+$", directory_name, re.ASCII):
# 数字のみで構成されたファイルを抽出する
if re.match("\d+.txt", base_name, re.ASCII):
# ディレクトリ構造を含めたファイル名やディレクトリ名をリストに格納する
final_list.append(x)
# 正規表現を適用して抽出したリストを表示する
print(final_list)
// 実行結果
適切な形式のファイルのみ読み込んでデータを表示する
これまでPythonのglob.glob()関数の使い方や、reモジュールによる正規表現のテクニックについて解説しました。これらの知識を活かせば、条件に合うファイルの一覧を取得して、一括で処理することができます。
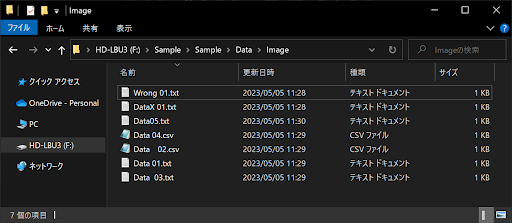
まずは、Dataフォルダに新たに「Image」フォルダを追加して、以下のようなファイルを追加してください。
- Wrong 01.txt
- DataX 01.txt
- Data05.txt
- Data 04.csv
- Data 02.csv
- Data 01.txt
- Data 03.txt
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「os」ライブラリをインポートする
import os
# 「re」ライブラリをインポートする
import re
# 「csv」ライブラリをインポートする
import csv
# compare()関数|適切な形式のファイルを番号でソートする
def compare(filepath):
# re.findall()関数で、ファイル番号を抽出する
result = re.findall(".*\\\\data\s*(\d+).(txt|csv)$", filepath, re.IGNORECASE)
# 戻り値のオブジェクトが空でなければ、最初の要素にファイル番号が格納されている
if result:
return int(result[0][0])
# 適切な形式のファイルでなければ「0」を返す
return 0
# main()|プログラムのエントリーポイント
if __name__ == "__main__":
# 「glob.glob()」を使用して、Imageディレクトリ内のファイルをすべて取得する
# 「recursive引数」をTrueにしているため、サブディレクトリも再帰的に走査される
original_list = glob.glob("Data\\Image\\**", recursive = True)
# ファイルを番号順でソートする
# 「Data 01.txt → Data 02.txt → Data 03.txt」などのイメージで並ぶようにソートする
original_list.sort(key = compare)
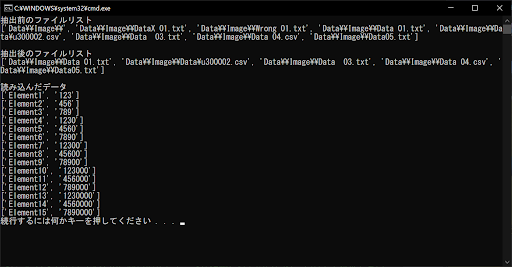
# 抽出前のファイルリストを表示する
print(f"抽出前のファイルリスト\n{original_list}\n")
# 正規表現を適用したリストを用意する
final_list = []
# オリジナルのリストを正規表現で走査する
for x in original_list:
# 適切な名前のファイルのみ抽出する
# 大文字と小文字を区別しないため「re.IGNORECASE」フラグを指定する
if re.match(".*\\\\data\s*\d+.(txt|csv)$", x, re.IGNORECASE):
# ファイルパスを最終的なリストに格納する
final_list.append(x)
# 抽出後のファイルリストを表示する
print(f"抽出後のファイルリスト\n{final_list}\n")
# データを格納するためのリストを用意する
data_list = []
# ファイルリストから1つずつ読み込んで、csvライブラリの関数でデータをリストに格納する
for x in final_list:
# ファイル内のデータをまとめて読み込む
with open(x) as f:
for row in csv.reader(f):
data_list.append(row)
# 読み込んだデータを表示する
print("読み込んだデータ")
# リストにはファイルと同じ形式でデータが格納されているため、そのまま表示できる
for x in data_list:
print(x)
// 実行結果
上記のサンプルプログラムでは、まずglob.glob()でImageフォルダ内のファイル名を取得します。ファイル名の番号が小さい順にデータを取得したいため、ファイルリストをsort()でソートします。ソート方法はcompare()の内部で、re.findall()を使って行うことがポイントです。
re.findall()の引数はre.match()と同じですが、戻り値は「カッコでグループ化した部分に該当する値」となるため、実質的には任意のフォーマットでデータを抽出する関数として使えます。
なお、re.match()と同様にre.findall()でも、第3引数に「re.IGNORECASE」を指定することで、大文字と小文字を同じものとして扱うことが可能です。戻り値は2重タプルなので、インデックスを「[0][0]」にすると、ファイルの番号を取得できます。
ファイルリストのソートが完了したら、forループで正規表現を使用して適切なファイル名を抽出しましょう。正規表現は「.*\\\\data\s*(\d+).(txt|csv)$」で、これは「Data」+「スペース0文字以上」+「番号1文字以上」+「.txtもしくは.csv」のフォーマットです。スペースはあり・なし・半角・全角いずれもOKで、このように冗長性を持たせることでエラーやバグが減ります。
正しいファイルリストが完成したら、あとはPythonのcsvライブラリでデータを取得するだけです。今回は「.txt」と「.csv」の拡張子のファイルを使用しましたが、処理を少し書き換えれば画像ファイルや音声ファイルの一括操作にも使えます。さまざまなパターンを試してみてください。
ファイル名やディレクトリ名を「イテレータ」で取得する方法

これまで解説したglob.glob()関数は、条件に一致するファイル名やディレクトリ名を、「リスト」形式で取得するものでした。しかし、抽出したパスをfor文などで処理する場合は、リストではなく「イテレータ」のほうが、実行速度やメモリ使用量などの点で有利なことがあります。そこで、以下の構文でglob.iglob()関数を使用すると、抽出したデータをイテレータ形式で取得できます。
イテレータ = glob.iglob("検出条件", recursive = True)
基本的な使い方はglob.glob()関数と同じです。しかし、イテレータは基本的にforループなどで使用することが前提なので、リストのようにprint()で一括表示することはできません。イテレータは以下のサンプルコードのように、forループを回してre.match()関数で詳細を抽出するときに便利です。
// サンプルプログラム
# coding: UTF-8
# 「glob」ライブラリをインポートする
import glob
# 「os」ライブラリをインポートする
import os
# 「re」ライブラリをインポートする
import re
# 「glob.iglob()」を使用して、Dataフォルダ内のすべてのファイルとディレクトリを「イテレータ」形式で取得する
# 「recursive引数」をTrueにしているため、サブディレクトリもすべて再帰的に走査される
original_list = glob.iglob("Data\\**", recursive = True)
# 正規表現を適用したリストを用意する
final_list = []
# オリジナルのリストに正規表現を適用して抽出する
for x in original_list:
# os.path.basename()でディレクトリ名を取り除き、ファイル名のみで正規表現を適用する
base_name = os.path.basename(x)
# 正規表現「"\w{6,}.txt"」で抽出したリストを取得する
# いずれかの文字や数字を6文字以上含んでいればOK
# ただし「re.ASCIIフラグ」を指定しているため、半角英数字しかマッチしない
if re.match("\w{6,}.txt", base_name, re.ASCII):
# ディレクトリ構造を含めたファイル名やディレクトリ名をリストに格納する
final_list.append(x)
# オリジナルのリストに正規表現を適用して抽出する
print(final_list)
// 実行結果
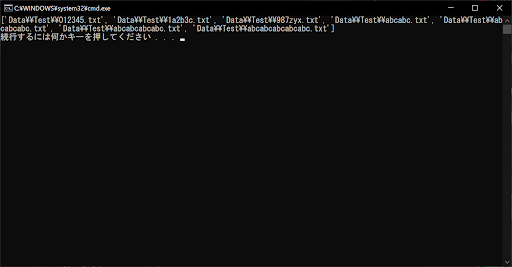
forループにおいても、イテレータの使い方はリストと同じです。しかし、イテレータは実行速度やメモリ使用量などの点でリストより優れているため、検出するファイルやディレクトリが多い場合に有利です。
Pythonのglob.glob()でファイルの一括操作を効率化しよう

Pythonの「globモジュール」や「glob.glob()関数」について、基本的な使い方から応用テクニックまで解説しました。globモジュール単体でも、ある程度のファイル名・ディレクトリ名の抽出はできますが、複雑な条件設定を行うためには「reモジュール」による正規表現が必須です。
今回ご紹介したサンプルコードには、難しい内容のものもありますが、ぜひ参考にしてファイル操作に活用してみてください。











アクセスランキング 人気のある記事をピックアップ!
コードカキタイがオススメする記事!

2024.06.17
子供におすすめのプログラミングスクール10選!学習メリットや教室選びのコツも紹介
#プログラミングスクール

2022.01.06
【完全版】大学生におすすめのプログラミングスクール13選!選ぶコツも詳しく解説
#プログラミングスクール

2024.01.26
【未経験でも転職可】30代におすすめプログラミングスクール8選!
#プログラミングスクール

2024.01.26
初心者必見!独学のJava学習方法とおすすめ本、アプリを詳しく解説
#JAVA

2024.01.26
忙しい社会人におすすめプログラミングスクール15選!失敗しない選び方も詳しく解説
#プログラミングスクール

2022.01.06
【無料あり】大阪のおすすめプログラミングスクール14選!スクール選びのコツも紹介
#プログラミングスクール

2024.01.26
【目的別】東京のおすすめプログラミングスクール20選!スクール選びのコツも徹底解説
#プログラミングスクール

2024.01.26
【無料あり】福岡のおすすめプログラミングスクール13選!選び方も詳しく解説
#プログラミングスクール

2024.01.26
【徹底比較】名古屋のおすすめプログラミングスクール13選!選び方も詳しく解説
#プログラミングスクール

2024.01.26
【徹底比較】おすすめのプログラミングスクール18選!失敗しない選び方も徹底解説
#プログラミングスクール