
Pythonの「OpenCV」は、画像加工を行うためのライブラリです。高度な画像編集が行えるため、さまざまな分野で活用されています。さらに、AIやディープラーニングなどの最新技術を駆使した、画像認識や検出もOpenCVで行えます。
しかし、OpenCVを使いこなすためには、基本的な知識とテクニックはもちろん、多数のオブジェクトやメソッドの扱い方を理解しておかないといけません。そのため、本記事ではPythonのOpenCVを使いこなすための必須の知識や、テクニックについてサンプルコードつきで解説します。
目次
Pythonの「OpenCV」とは

「OpenCV(Open Source Computer Vision Library)」とは、Intel社が2000年代にリリースした画像処理ライブラリです。高度な画像処理や加工に加えて、汎用的な数学や機械学習(ディープラーニング)に関する機能が搭載されていることが特徴です。そのため、画像編集に加えて画像認識や検出など、最先端の用途にも幅広く活用されています。
「画像編集」というと、難しく高度なスキルが要求されるイメージがあるかもしれません。しかし、OpenCVを活用することで、高度な処理も簡潔なソースコードで行えるようになります。そのため、これまで画像関連の処理を行ったことがない場合でも、OpenCVなら気軽にチャレンジできるでしょう。
また、OpenCVはC++・Java・Pythonなどさまざまなプログラミング言語に対応しているため、Pythonでの使い方に慣れておけば、ほかの言語に移行したときも画像加工がスムーズにできます。そのため、OpenCVの学習価値は極めて高いといえるでしょう。
OpenCVを使うメリット

OpenCVを使うことで、以下4つのメリットが得られます。
- 高度な画像処理がスムーズに行える
- 初心者でも導入や活用が行いやすい
- Numpyなどのライブラリと相性が良い
- ARやVRなどのコンテンツも開発できる
高度な画像処理がスムーズに行える
PythonでOpenCVを使うと、高度な画像処理がスムーズに行えるようになります。さまざまな場面で、画像加工を行いたいことがあるでしょう。その際に、画像処理における一連のプロセスをプログラム化できれば、全体的な作業効率が向上します。しかし、画像処理には「高度なスキル」が欠かせないというイメージがあるため、思うように実践できないことも多いです。
OpenCVを活用すれば、ハイレベルな画像処理や加工がスムーズに行えるようになります。画像処理に必要な数学的な処理は、ライブラリが内部で行ってくれるので、オブジェクトやメソッドの使い方さえ理解しておけば、専門知識がなくても必要な処理を実現できます。
また、画像解析や検出の前に行う「事前処理」も、OpenCVなら簡単に行えます。例えば、画像検出を行うときは、画像を事前に「グレースケール」や「2値化」しておく必要があるケースが多いです。これは、検出すべき特徴をAIが認識しやすいようにするための処理で、これを行っておくことで検出精度が高まります。OpenCVでは、わずか数行のソースコードで、グレースケールや2値化を行うことができるので、効率的な画像処理が可能です。
初心者でも導入や活用がしやすい
PythonでOpenCVを利用する場合は、ごく簡単な手順でインストールできます。詳細は後述しますが、Windows PCの場合はコマンドプロンプトを開き、「PIPコマンド」を使用するだけでOpenCVをインストールできます。
ライブラリを使いたくても、その導入手順でつまづいてしまうケースは珍しくありません。しかし、OpenCVは初心者でも簡単に導入できるうえに、スムーズに使えることが魅力です。これらの理由から、OpenCVは高度なライブラリでありながら、初心者にも優しいといえるでしょう。
Numpyなどのライブラリと相性が良い
Pythonは科学技術や数値計算など、最先端の分野で活用されることが多いプログラミング言語です。その中でも「Numpy」は、ベクトルや行列の演算に長けているため、科学技術計算や機械学習などで重宝されています。そのNumpyとOpenCVを組み合わせて、高精度の画像処理を行うことも可能です。NumpyもOpenCVと同様に、洗練された構造のライブラリであるため、初心者でも気軽に扱えます。
ARやVRなどのコンテンツも開発できる
OpenCVは、AR(拡張現実)やVR(仮想現実)などのような、最新の映像コンテンツの開発にも活用できます。OpenCVは、物体の位置や動きの解析・追跡などを行うことができるため、ARやVR開発の効率化にも最適です。例えば、世界的に有名なゲームエンジン「Unity」では、「OpenCV for Unity」という外部プラグインが公開されています。
PythonでOpenCVを使うための手順・インストール方法

OpenCVはPythonにデフォルトで含まれている機能ではないため、そのままではOpenCVを利用できません。そのため、WindowsとmacOSいずれも、所定の手順でインストールする必要があります。Windows PCの場合は、以下の手順でコマンドプロンプトを開き、PIPコマンドを入力しましょう。
py -m pip install opencv-python
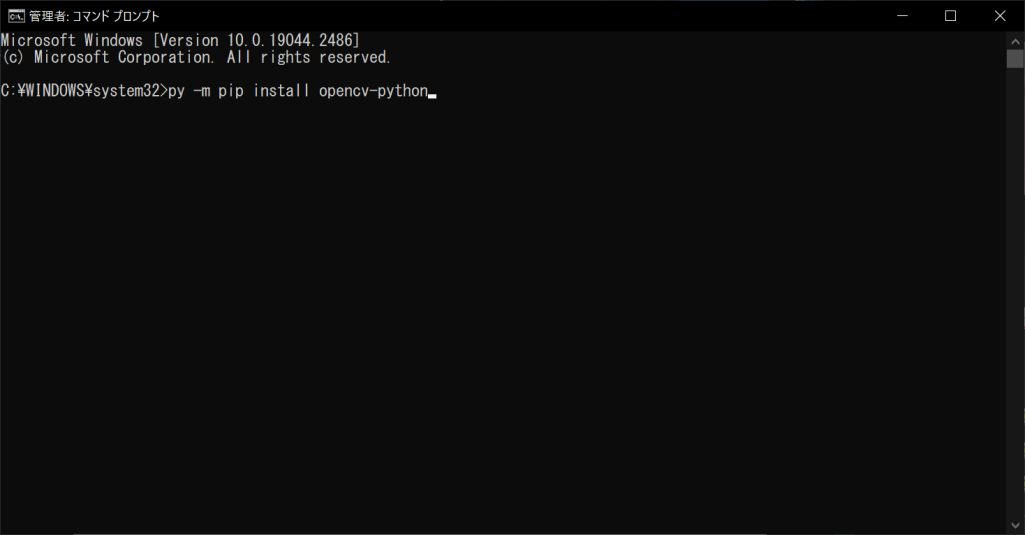
OpenCVは容量が大きいライブラリなので、インストールまでに数分から10分ほど時間がかかることがあります。しばらくコンソール画面に変化がなくても、インストールは進行しているので、次のような画面が表示されるまで待ちましょう。
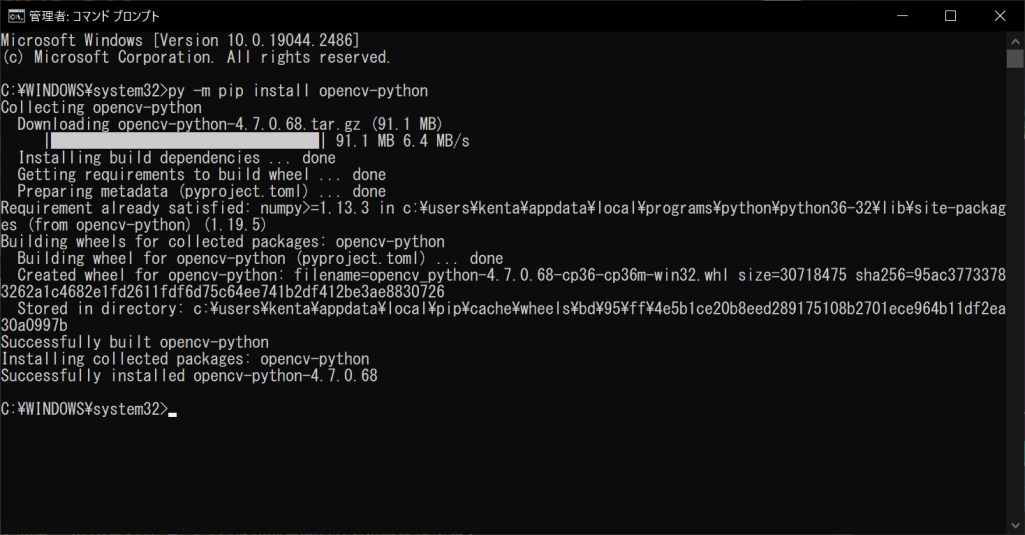
これだけの手順で、OpenCVを使用するための事前準備が整いました。このように、OpenCVは簡単に使えるようになるため、初心者でも気軽に導入できることが魅力です。
【基礎編1】PythonのOpenCVの基本的な使い方

PythonのOpenCVの基本的な使い方として、以下の5つのポイントから解説します。
- ウィンドウに画面を表示する
- 画像をリサイズする
- 画像を保存する
- 画像を回転する
- 画像のトリミングを行う
ウィンドウに画面を表示する
OpenCVの第一歩は、ウィンドウに画像を表示することです。まずは、以下の画像を「Sample.jpg」という名称で、メインモジュールがあるディレクトリに保存して、サンプルコードを実行しましょう。

//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Sample.jpg")
# 画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", image)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

OpenCVを活用すると、わずかこれだけのソースコードで、画像を画面に表示することができます。まず、「cv2.imread()関数」を呼び出し、引数に画像ファイルのパスを指定します。戻り値として、画像データのオブジェクトが返るため、必ず変数として保持しておきましょう。それから「cv2.imshow()関数」を呼び出すと、画像サイズに合うウィンドウが自動的に生成され、読み込んだ画像が画面上に表示されます。
cv2.imshow()の引数には、ウィンドウタイトルと画像データを指定することがポイントです。cv2.waitKey()でユーザー入力を待ち、cv2.destroyAllWindows()でプログラムを終了します。なお、cv2.waitKey()とcv2.destroyAllWindows()は、プログラムを終了させるために必要な部分です。なので、OpenCVでプログラミングを行うときは、基本的に常に書くようにしましょう。
ちなみに、CV2は「マルチバイト文字」非対応なので注意が必要です。マルチバイト文字とは、簡単にいうと「日本語や中国語などの複雑な文字」のことです。これらの文字は、アルファベットのような1バイトのデータで表すことができません。CV2はASCIIのシングルバイト文字にしか対応していないため、ファイルパスやウィンドウ名などに日本語を含めるとエラーや文字化けが生じます。
画像をリサイズする
画像データのサイズを変更したい場合は、以下の構文で「cv2.resize()関数」を使用しましょう。
変換後の画像データ = cv2.resize(変換前の画像データ, 変換後の画像サイズ, fx = X軸方向の各縮率, fy = Y軸方向の各縮率)
デフォルトのサイズが1.0であり、これより小さくすると縮小、大きくすると拡大となります。X軸とY軸のスケールを変更できるので、自由な拡大・縮小が可能です。resize()の使い方について、以下のサンプルコードで確認しましょう。
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Sample.jpg")
# 元のサイズの25%(4分の1)のサイズに変更する
# 第1引数は元の画像データ
# 第2引数は変換後の画像サイズ(fxとfyを指定する場合は「0」でOK)
# 第3引数「fx」はX軸方向の各縮率
# 第4引数「fy」はY軸方向の各縮率
image = cv2.resize(image, (0, 0), fx = 0.25, fy = 0.25)
# 画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", image)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果
なお、画像のリサイズ時に「補間方法」を指定することも可能です。以下のように、「interpolation引数」を指定します。
変換後の画像データ = cv2.resize(変換前の画像データ, 変換後の画像サイズ, fx = X軸方向の各縮率, fy = Y軸方向の各縮率, interpolation = 補間方法)
interpolation引数には、以下のいずれかの値を指定できます。
| interpolationの値 | 補間方法 |
|---|---|
| cv2.INTER_NEAREST | 最近傍補間 |
| cv2.INTER_LINEAR | バイリニア補間 |
| cv2.INTER_CUBIC | バイキュービック補間 |
| cv2.INTER_AREA | 平均画素法 |
| cv2.INTER_LANCZOS4 | Lanczos(ランチョス)法 |
interpolation引数を指定しない場合は、cv2.INTER_LINEAR(バイリニア補間)となります。補間方法によって、画像の品質や繊細さが大きく異なりますが、詳細は次の項目で解説します。
画像を保存する
OpenCVでは、「cv2.imwrite()関数」を使用することで、画像を保存できます。
cv2.imwrite("出力先ファイル名", 画像データ)
先ほど紹介したinterpolation引数の設定内容によって、拡大・縮小の品質がどのように変わるか確認してみましょう。まずは、縮小する場合のサンプルコードです。
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Sample.jpg")
# 元のサイズの25%(4分の1)のサイズに変更する
# 第1引数は元の画像データ
# 第2引数は変換後の画像サイズ(fxとfyを指定する場合は「0」でOK)
# 第3引数「fx」はX軸方向の各縮率
# 第4引数「fy」はY軸方向の各縮率
# 第5引数「interpolation」は補間方法
# 最近傍補間
small_image_nearest = cv2.resize(image, (0, 0), fx = 0.25, fy = 0.25, interpolation = cv2.INTER_NEAREST)
# バイリニア補間
small_image_linear = cv2.resize(image, (0, 0), fx = 0.25, fy = 0.25, interpolation = cv2.INTER_LINEAR)
# バイキュービック補間
small_image_cubic = cv2.resize(image, (0, 0), fx = 0.25, fy = 0.25, interpolation = cv2.INTER_CUBIC)
# 平均画素法
small_image_area = cv2.resize(image, (0, 0), fx = 0.25, fy = 0.25, interpolation = cv2.INTER_AREA)
# Lanczos(ランチョス)法
small_image_lanczos = cv2.resize(image, (0, 0), fx = 0.25, fy = 0.25, interpolation = cv2.INTER_LANCZOS4)
# リサイズした各画像を保存する
cv2.imwrite("small_image_nearest.jpg", small_image_nearest)
cv2.imwrite("small_image_linear.jpg", small_image_linear)
cv2.imwrite("small_image_cubic.jpg", small_image_cubic)
cv2.imwrite("small_image_area.jpg", small_image_area)
cv2.imwrite("small_image_lanczos.jpg", small_image_lanczos)
//実行結果
small_image_nearest.jpg(最近傍補間)

small_image_linear.jpg(バイリニア補間)

small_image_cubic.jpg(バイキュービック補間)

small_image_area.jpg(平均画素法)

small_image_lanczos.jpg(Lanczos法)

それぞれの画像を比較してみると、補間方法によって画像品質に大きな違いがあることが理解できるでしょう。画像を縮小する場合は、「cv2.INTER_AREA」が最も高品質になる傾向があります。一方で、画像を拡大する場合は状況が異なります。
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Sample.jpg")
# 元のサイズの150%(1.5倍)のサイズに変更する
# 第1引数は元の画像データ
# 第2引数は変換後の画像サイズ(fxとfyを指定する場合は「0」でOK)
# 第3引数「fx」はX軸方向の各縮率
# 第4引数「fy」はY軸方向の各縮率
# 第5引数「interpolation」は補間方法
# 最近傍補間
large_image_nearest = cv2.resize(image, (0, 0), fx = 1.5, fy = 1.5, interpolation = cv2.INTER_NEAREST)
# バイリニア補間
large_image_linear = cv2.resize(image, (0, 0), fx = 1.5, fy = 1.5, interpolation = cv2.INTER_LINEAR)
# バイキュービック補間
large_image_cubic = cv2.resize(image, (0, 0), fx = 1.5, fy = 1.5, interpolation = cv2.INTER_CUBIC)
# 平均画素法
large_image_area = cv2.resize(image, (0, 0), fx = 1.5, fy = 1.5, interpolation = cv2.INTER_AREA)
# Lanczos(ランチョス)法
large_image_lanczos = cv2.resize(image, (0, 0), fx = 1.5, fy = 1.5, interpolation = cv2.INTER_LANCZOS4)
# リサイズした各画像を保存する
cv2.imwrite("large_image_nearest.jpg", large_image_nearest)
cv2.imwrite("large_image_linear.jpg", large_image_linear)
cv2.imwrite("large_image_cubic.jpg", large_image_cubic)
cv2.imwrite("large_image_area.jpg", large_image_area)
cv2.imwrite("large_image_lanczos.jpg", large_image_lanczos)
//実行結果
large_image_nearest.jpg(最近傍補間)

large_image_linear.jpg(バイリニア補間)

large_image_cubic.jpg(バイキュービック補間)

large_image_area.jpg(平均画素法)

large_image_lanczos.jpg(Lanczos法)

画像を拡大する場合は、「cv2.INTER_CUBIC」が最も高品質になることが分かります。このように、interpolation引数の設定内容によってリサイズのクオリティが大きく変わるため、用途に合うものを選ぶことが重要です。
画像を回転する
画像を回転させるときは、「cv2.rotate()関数」を以下の構文で使用しましょう。
回転後の画像データ = cv2.rotate(image, 回転方法)
回転方法には、以下の3種類のいずれかを指定できます。
| ROTATE_90_CLOCKWISE | 時計回りに90度回転 |
| ROTATE_90_COUNTERCLOCKWISE | 反時計回りに90度回転 |
| ROTATE_180 | 180度回転 |
実際に、rotated_clockwise()関数で画像を回転させる方法を、以下のサンプルコードで確認しましょう。
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Sample.jpg")
# 画像を時計回りで90度回転させる
rotated_clockwise = cv2.rotate(image, cv2.ROTATE_90_CLOCKWISE)
# 画像を半時計回りで90度回転させる
rotated_counter_clockwise = cv2.rotate(image, cv2.ROTATE_90_COUNTERCLOCKWISE)
# 画像を180度回転させる
rotated_180 = cv2.rotate(image, cv2.ROTATE_180)
# 変換した各画像を保存する
cv2.imwrite("rotated_clockwise.jpg", rotated_clockwise)
cv2.imwrite("rotated_counter_clockwise.jpg", rotated_counter_clockwise)
cv2.imwrite("rotated_180.jpg", rotated_180)
//実行結果
rotated_clockwise.jpg

rotated_counter_clockwise.jpg

rotated_180.jpg

上記のように、3種類の回転が行えます。ただし、これでは30度や45度など自由な角度での回転ができません。より自由な画像加工を行うテクニックについては、「応用編1」で詳しく解説する。
画像のトリミングを行う
画像のトリミングは、Pythonの標準機能であるリストの「スライス」機能を使用するだけで、簡単に行えます。
トリミング後の画像データ = トリミング前の画像データ[Y開始座標:Y終了座標, X開始座標:X終了座標]
「[]」演算子の内部で、トリミングの開始・終了座標を指定することがポイントです。このとき、左側が縦座標(Y座標)・右側が横座標(X座標)となっているので、間違えないように注意しましょう。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Sample.jpg")
# X方向に400ピクセルから800ピクセル、Y方向に200ピクセルから600ピクセルの範囲をトリミングする
trimmed = image[200:600, 400:800]
# トリミングした画像を保存する
cv2.imwrite("Trimmed.jpg", trimmed)
# トリミングした画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", trimmed)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

このように、大きな画像から花弁の部分だけを切り取ることができました。スライス座標を変えると、トリミングできる部分も変わるので、いろいろなパターンを試してみましょう。
【基礎編2】画像の拡張子を変換する方法

OpenCVでは、画像ファイルを「PNGからJPG」「JPGからPNG」へ簡単に変換できます。以下の画像を「Sample.png」という名称で、メインモジュールのディレクトリに保存し、サンプルコードを実行しましょう。

PNGからJPGに変換する
以下の構文で、PNG画像からJPG画像に変換できます。
cv2.imwrite("出力先ファイル名", PNG画像データ, [int(cv2.IMWRITE_JPEG_QUALITY), 変換品質])
重要なポイントは、第3引数に「変換品質」を指定することです。PNG画像をJPG画像に変換する方法は、以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# PNG画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Sample.png")
# 画像をJPG形式で保存する
cv2.imwrite("Sample.jpg", image, [int(cv2.IMWRITE_JPEG_QUALITY), 100])
# 読み込んだ画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", image)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

cv2.imwrite()メソッドの第3引数には、リスト形式で「cv2.IMWRITE_JPEG_QUALITY」を指定したうえで、JPG画像の品質を0~100の間で指定します。上記のように、最高値の100にするとハイクオリティになります。一方で最低値の0にすると、以下のように荒い画像となることが注意点です。

ただし、変換品質を高くすると画像サイズが大きくなるため、省スペース化を意識したい場合は、画像劣化が気にならない範囲で変換品質を下げるといいでしょう。
JPGからPNGに変換する
先ほど作成したJPG画像を、今度はPNG形式に変換してみましょう。PNG画像への変換もcv2.imwrite()関数を使いますが、以下のように第3引数が異なるので注意が必要です。
cv2.imwrite("出力先ファイル名", JPG画像データ, [int(cv2.IMWRITE_PNG_COMPRESSION), 圧縮強度])
PNGをJPGに変換する場合と異なり、今回は「cv2.IMWRITE_PNG_COMPRESSION」を指定し、圧縮強度を0~9の間で決めます。圧縮強度を0にすると、解凍がスムーズになるため高速に読み込めますが、データサイズが大きくなります。9に近づけるとデータサイズは節約できますが、複雑な解凍が必要になるので読み込み時間が長くなる。なお、PNGは「可逆圧縮」の画像形式なので、圧縮強度を高めても画質が劣化することはありません。
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# JPG画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Sample.jpg")
# 画像をPNG形式で保存する
cv2.imwrite("Sample2.png", image, [int(cv2.IMWRITE_PNG_COMPRESSION), 0])
# 読み込んだ画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", image)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

ちなみに、上記の画像の例では圧縮強度を「0」にした場合、ファイルサイズは2,922KBとなります。一方、圧縮強度を最大の「9」にすると、1,817KBと約6割程度のサイズとなりました。
【基礎編3】画像編集・加工を行うための関数・メソッド

OpenCVのメイン機能である、画像編集や加工を行うための関数・メソッドについて、以下の8つのポイントから解説します。
- 画像にテキストを描画する
- 画像に円を描画する
- 画像に矩形を描画する
- 画像に直線を描画する
- 画像に矢印を描画する
- 画像にポインターを描画する
- 画像のぼかし処理を行う
- 色情報を変換する
画像にテキストを描画する
「cv2.putText()関数」を使用すると、画像にテキストを描画できます。なお、OpenCVでは色情報の並びが「BGR(青・緑・赤)」となっているので、RGBの順番で記載しないよう注意が必要です。cv2.putText()の構文は以下のとおりです。
cv2.putText(対象の画像データ,
text = "描画テキスト",
org = (描画開始X座標, 描画開始Y座標),
fontFace = フォントの種類,
fontScale = フォントの縮尺,
color = (青, 緑, 赤),
thickness = 線の太さ,
lineType = 描画アルゴリズム)
「fontFace引数」には、以下の値を指定できます。「cv2.FONT_ITALIC」を選ぶと、通常のイタリック体になります。
- cv2.FONT_HERSHEY_PLAIN
- cv2.FONT_HERSHEY_DUPLEX
- cv2.FONT_HERSHEY_COMPLEX
- cv2.FONT_HERSHEY_TRIPLEX
- cv2.FONT_HERSHEY_COMPLEX_SMALL
- cv2.FONT_HERSHEY_SCRIPT_SIMPLEX
- cv2.FONT_HERSHEY_SCRIPT_COMPLEX
- cv2.FONT_ITALIC
「lineType引数」で指定できる値は、以下のとおりです。
- cv2.LINE_4
- cv2.LINE_8
- cv2.LINE_AA
デフォルト設定は「cv2.LINE_8」となっています。「cv2.LINE_AA」にすると、アンチエイリアスがかかるので、滑らかなテキストを描画可能です。cv2.putText()の使い方について、以下のサンプルコードで確認しましょう。
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Sample.jpg")
# 画像にテキストを描画する
# 第1引数は描画対象の画像データ
# 「text引数」は描画するテキスト
# 「org引数」は描画開始位置(てぉしtpの左上の部分)の座標
# 「fontFace引数」は描画するフォントの種類
# 「fontScale引数」はフォントの縮尺
# 「color引数」は描画テキストの色
# 「thickness引数」は描画する文字の太さ
# 「lineType引数」は描画アルゴリズム
cv2.putText(image,
text = "Sample Text",
org = (30, 180),
fontFace = cv2.FONT_HERSHEY_TRIPLEX,
fontScale = 5.0,
color = (255, 128, 0),
thickness = 10,
lineType = cv2.LINE_AA)
# テキストを挿入した画像を保存する
cv2.imwrite("text.jpg", image)
# テキストを挿入した画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", image)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

画像に円を描画する
円を描画するときは、以下の構文で「cv2.circle()関数」を使用します。
cv2.circle(対象の画像データ,
center = (円の中心X座標, 円の中心Y座標),
radius = 円の半径,
color = (青, 緑, 赤),
thickness = 線の太さ,
lineType = 描画アルゴリズム)
「radius引数」は、円の直径ではなく半径を指定するので、間違えないように注意が必要です。詳細は以下のサンプルコードのとおりです。lineType引数については、先ほどのcv2.putText()関数と同じです。
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Sample.jpg")
# 画像に円を描画する
# 第1引数は描画対象の画像データ
# 「center引数」は描画する円の中心座標
# 「radius引数」は描画する円の半径
# 「color引数」は描画する円の色
# 「thickness引数」は描画する円の線の太さ
# 「lineType引数」は描画アルゴリズム
cv2.circle(image,
center = (600, 400),
radius = 250,
color = (255, 128, 0),
thickness = 10,
lineType = cv2.LINE_AA)
# 円を描画した画像を保存する
cv2.imwrite("circle.jpg", image)
# 円を描画した画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", image)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

画像に矩形を描画する
画像に正方形や長方形を描画するときは、以下の構文で「cv2.rectangle()関数」を使用しましょう。
cv2.rectangle(対象の画像データ,
pt1 = (左上X座標, 左上Y座標),
pt2 = (右下X座標, 右下Y座標),
color = (青, 緑, 赤),
thickness = 線の太さ,
lineType = 描画アルゴリズム)
「pt1引数」は左上、「pt2引数」は右下の座標を指定します。矩形の中心を指定するものではないので、間違えないように注意が必要です。lineType引数については前述したとおりです。詳細を以下のサンプルコードで確認しましょう。
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Sample.jpg")
# 画像に矩形を描画する
# 第1引数は描画対象の画像データ
# 「pt1」は描画する矩形の左上部分の座標
# 「pt2」は描画する矩形の右下部分の座標
# 「color引数」は描画する矩形の色
# 「thickness引数」は描画する矩形の線の太さ
# 「lineType引数」は描画アルゴリズム
cv2.rectangle(image,
pt1 = (300, 200),
pt2 = (900, 600),
color = (255, 128, 0),
thickness = 10,
lineType = cv2.LINE_AA)
# 矩形を描画した画像を保存する
cv2.imwrite("rectangle.jpg", image)
# 矩形を描画した画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", image)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

画像に直線を描画する
「cv2.line()関数」を以下の構文で使用すると、画像に直線を描画できます。
cv2.line(image,
pt1 = (始点X座標, 始点Y座標),
pt2 = (終点X座標, 終点Y座標),
color = (青, 緑, 赤),
thickness = 線の太さ,
lineType = 描画アルゴリズム)
「pt1引数」に始点、「pt2引数」に終点の座標を指定することがポイントです。これまでの関数と同じく、「color引数」には「BGR」の順番で色を指定するため、間違えないように注意が必要です。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Sample.jpg")
# 画像に直線を描画する
# 第1引数は描画対象の画像データ
# 「pt1」は描画する直線の始点座標
# 「pt2」は描画する直線の終点座標
# 「color引数」は描画する直線の色
# 「thickness引数」は描画する直線の線の太さ
# 「lineType引数」は描画アルゴリズム
cv2.line(image,
pt1 = (300, 200),
pt2 = (900, 100),
color = (255, 128, 0),
thickness = 10,
lineType = cv2.LINE_AA)
# 直線を描画した画像を保存する
cv2.imwrite("line.jpg", image)
# 直線を描画した画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", image)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

画像に矢印を描画する
矢印の描画は、以下の構文で「cv2.arrowedLine()関数」で行います。
cv2.arrowedLine(対象の画像データ,
pt1 = (始点X座標, 始点Y座標),
pt2 = (終点X座標, 終点Y座標),
color = (青, 緑, 赤),
thickness = 線の太さ,
lineType = 描画アルゴリズム,
tipLength = 0.2)
これまでの関数とは異なり、描画アルゴリズムの引数名がlineTypeではなく「line_type」となっているため、間違えないように注意が必要です。
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Sample.jpg")
# 画像に矢印を描画する
# 第1引数は描画対象の画像データ
# 「pt1」は描画する矢印の始点座標
# 「pt2」は描画する矢印の終点座標
# 「color引数」は描画する矢印の色
# 「thickness引数」は描画する矢印の線の太さ
# 「line_type引数」は描画アルゴリズム
# 「tipLength引数」は矢印部分の長さ
cv2.arrowedLine(image,
pt1 = (300, 200),
pt2 = (900, 100),
color = (255, 128, 0),
thickness = 10,
line_type = cv2.LINE_AA,
tipLength = 0.2)
# 矢印を描画した画像を保存する
cv2.imwrite("arrow.jpg", image)
# 矢印を描画した画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", image)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

画像にポインターを描画する
画像にポインターを描画するときは、以下の構文で「cv2.drawMarker()関数」を使用しましょう。
cv2.drawMarker(image,
position = (中心X座標, 中心Y座標),
color = (青, 緑, 赤),
markerType = ポインターの種類,
markerSize = ポインターのサイズ,
thickness = 線の太さ,
line_type = 描画アルゴリズム)
「markerType引数」には以下の値を指定でき、それぞれ四角形や星形など視覚的に分かりやすいポインターを描画できます。
- cv2.MARKER_CROSS
- cv2.MARKER_TILTED_CROSS
- cv2.MARKER_STAR
- cv2.MARKER_DIAMOND
- cv2.MARKER_SQUARE
- cv2.MARKER_TRIANGLE_UP
- cv2.MARKER_TRIANGLE_DOWN
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Sample.jpg")
# 画像に矢印を描画する
# 第1引数は描画対象の画像データ
# 「position」は描画する矢印の中心座標
# 「color引数」は描画する矢印の色
# 「markerType引数」は描画する矢印の種類
# 「markerSize引数」は描画する矢印の大きさ
# 「thickness引数」は描画する矢印の線の太さ
# 「line_type引数」は描画アルゴリズム
cv2.drawMarker(image,
position = (630, 400),
color = (255, 128, 0),
markerType = cv2.MARKER_DIAMOND,
markerSize = 100,
thickness = 5,
line_type = cv2.LINE_AA)
# 矢印を描画した画像を保存する
cv2.imwrite("marker.jpg", image)
# 矢印を描画した画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", image)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

markerType引数を変えると、ポインターの画像も変わるため、サイズや色と合わせてさまざまなパターンを試してみましょう。
画像のぼかし処理を行う
画像のぼかし処理は、「cv2.blur()関数」で簡単に行うことができます。
ぼかし後の画像データ = cv2.blur(元の画像データ, (横方向のぼかし強度, 縦方向のぼかし強度))
第2引数には「ぼかし強度」を設定でき、値が大きくなるほど画像のブレ具合が強くなります。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: UTF-8
# 「cv2」ライブラリをimportする
import cv2
# 画像を読み込む
image = cv2.imread("Sample.jpg")
# 画像をぼかす
blurred = cv2.blur(image, (5, 5))
# ぼかし処理後の画像をPNG形式で保存する
cv2.imwrite("Blurred.png", blurred)
# ぼかし処理後の画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", blurred)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

フィルターの縦横の強度を意図的に変えることで、画像のブレ感を表現できます。横方向30・縦方向1にすると、以下のように横に大きくブレたような画像になるので、さまざまなパターンを試してみましょう。

色情報を変換する
画像の色情報を変換する場合は、以下のように「cv2.cvtColor()関数」を使用します。
変換後の画像データ = cv2.cvtColor(変換前の画像データ, 変換方法)
「変換方法」には次のような値を設定できます。いずれも既存の「BGR形式」の画像を、ほかの形式に変換するものです。前述したように、OpenCVの内部では画像のピクセルデータは青・緑・赤の順番で並んでいるため、これを変換すると画像の雰囲気が大きく変わります。
- cv2.COLOR_BGR2GRAY
- cv2.COLOR_BGR2RGB
- cv2.COLOR_BGR2HSV
- cv2.COLOR_BGR2YCrCb
- cv2.COLOR_BGR2XYZ
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Sample.jpg")
# 画像をGRAYに変換する
GRAY_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 画像をRGBに変換する
RGB_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 画像をHSVに変換する
HSV_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 画像をYCrCbに変換する
YCrCb_image = cv2.cvtColor(image, cv2.COLOR_BGR2YCrCb)
# 画像をXYZに変換する
XYZ_image = cv2.cvtColor(image, cv2.COLOR_BGR2XYZ)
# 変換した各画像を保存する
cv2.imwrite("GRAY_image.jpg", GRAY_image)
cv2.imwrite("RGB_image.jpg", RGB_image)
cv2.imwrite("HSV_image.jpg", HSV_image)
cv2.imwrite("YCrCb_image.jpg", YCrCb_image)
cv2.imwrite("XYZ_image.jpg", XYZ_image)
//実行結果
GRAY_image.jpg

RGB_image.jpg

HSV_image.jpg

YCrCb_image.jpg

XYZ_image.jpg

【応用編1】OpenCVとNumpyの組み合わせ

OpenCVとNumpyを組み合わせると、より高度な画像の編集・変形ができるようになります。ちなみに、Numpyは前述したように、数値計算を効率的に行うためのライブラリです。
Numpyの行列演算とOpenCVの「cv2.warpAffine()関数」を組み合わせることで、画像の「アフィン変換」が簡単に実行できるでしょう。ちなみに、アフィン変換とは、画像の拡大縮小・回転・平行移動などを行列演算で行うためのものです。アフィン変換を行うためには、変換行列を作成する必要があります。
なお、NumpyもPythonに標準的に備わっている機能ではないため、PIPコマンドを使ってインストールする必要があります。コマンドプロンプトを開き、以下のコマンドを入力しましょう。
py -m pip install numpy
本章では、OpenCVとNumpyを組み合わせた、高度な画像変形テクニックについて解説します。
- 画像の平行移動を行う
- 画像の拡大縮小を行う
- 画像の自由な回転と拡大縮小を行う
- 画像のせん断を行う
画像の平行移動を行う
画像の平行移動は、以下の構文で「cv2.warpAffine」を活用して行います。
平行移動後の画像データ = cv2.warpAffine(元の画像データ, 変換行列, (変換後の画像サイズX, 変換後の画像サイズY))
なお、変換行列は以下のように「numpy.float32()メソッド」で作成します。
変換行列 = numpy.float32([[1, 0, 移動X値],[0, 1, 移動Y値]])
「1」と「0」の部分はいかなる場合も固定し、「移動X値」と「移動Y値」の部分に画像の移動量を指定するだけでOKです。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: UTF-8
# 「cv2」ライブラリをimportする
import cv2
# 「numpy」ライブラリをimportする
import numpy
# 画像を読み込む
image = cv2.imread("Sample.jpg")
# 画像の移動量を決定して変数に格納
# X方向に200・Y方向に100移動させる
matrix = numpy.float32([[1, 0, 200],[0, 1, 100]])
# 画像のサイズを取得する
height, width = image.shape[:2]
# 画像を平行移動させる
# 全体のサイズは、元の画像全体が収まるように拡張
moved = cv2.warpAffine(image, matrix, (width + 210, height + 110))
# 平行移動後の画像をPNG形式で保存する
cv2.imwrite("Moved.png", moved)
# 平行移動後の画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", moved)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

X軸方向に200・Y軸方向に100移動する変換行列を作成したため、上記のように画像が右下方法に移動しました。
画像の拡大縮小を行う
冒頭に解説した「cv2.resize()メソッド」でも、読み込んだ画像のリサイズは可能です。しかし、以下のように変換行列を作成することで、より自由な拡大縮小ができるようになります。
変換行列 = numpy.float32([[X方向のスケール, 0, 0], [0, Y方向のスケール, 0]])
先ほどと同じように「0」の部分は常に固定し、X・Yのスケール値だけを変更しましょう。1より小さくすると縮小、1より大きくすると拡大になります。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: UTF-8
# 「cv2」ライブラリをimportする
import cv2
# 「numpy」ライブラリをimportする
import numpy
# 画像を読み込む
image = cv2.imread("Sample.jpg")
# 画像のサイズを取得する
height, width = image.shape[:2]
# スケーリング行列を算出する
scaling = numpy.float32([[0.5, 0, 0], [0, 0.5, 0]])
# 画像を縮小する
sheared = cv2.warpAffine(image, scaling, (width, height))
# 縮小後の画像をPNG形式で保存する
cv2.imwrite("Scaled.png", sheared)
# 縮小後の画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", sheared)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

上記のサンプルプログラムでは、X・Yともにスケールを「0.5」にしたので、ちょうど半分の画像サイズとなりました。
画像の自由な回転と拡大縮小を行う
冒頭で解説したように、「cv2.rotate()関数」を使用すると画像の回転ができます。しかし、回転方向が90度および180度しか選べないことが難点でした。そこで、以下の方法でアフィン変換を行うと、画像を自由に回転できるうえに拡大・縮小も同時に行えます。
変形後の画像データ = cv2.warpAffine(元の画像データ, 変換行列, (変換後の画像サイズX, 変換後の画像サイズY))
なお、変換行列は以下のように「cv2.getRotationMatrix2D()メソッド」で作成します。
matrix = cv2.getRotationMatrix2D((画像の横幅 / 2, 画像の高さ / 2), 回転量, 拡縮のスケール)
第1引数で画像のサイズを半分にしているのは、回転の中心座標を決めるためです。画像の中央を中心にしないと、回転が正常に行えないので注意が必要。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: UTF-8
# 「cv2」ライブラリをimportする
import cv2
# 「numpy」ライブラリをimportする
import numpy
# 画像を読み込む
image = cv2.imread("Sample.jpg")
# 画像のサイズを取得する
height, width = image.shape[:2]
# 画像を回転させる際に必要な中心座標・回転量・拡縮度を指定する
# 時計回りに回転させる場合は、負の数を指定する
matrix = cv2.getRotationMatrix2D((width / 2, height / 2), -30, 0.5)
# 算出した変換行列で画像を拡大縮小・回転させる
rotated = cv2.warpAffine(image, matrix, (width, height))
# 拡大縮小・回転後の画像をPNG形式で保存する
cv2.imwrite("Rotated.png", rotated)
# 変形後の画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", rotated)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

上記のサンプルプログラムは、画像を時計回りに30度回転させたうえで、スケールを半分にします。なお、cv2.getRotationMatrix2Dの回転量は、正の値は反時計回り・負の値は時計回りとなるので注意が必要です。
画像のせん断を行う
長方形・正方形の画像を平行四辺形に変形させる「せん断」も、numpy.float32()関数でOpenCVで行えます。
せん断後の画像データ = numpy.float32([[1, numpy.tan(X方向のせん断角度), 0], [numpy.tan(Y方向のせん断角度), 1, 0]])
「0」と「1」の部分はそのまま固定し、XとYの「せん断角度」を指定しましょう。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: UTF-8
# 「cv2」ライブラリをimportする
import cv2
# 「numpy」ライブラリをimportする
import numpy
# composite()メソッド|2つの変換行列を合成する
def composite(matrix_1, matrix_2):
# 3×3行列に変換する
m1 = numpy.array([matrix_1[0], matrix_1[1], [0, 0, 1]])
m2 = numpy.array([matrix_2[0], matrix_2[1], [0, 0, 1]])
# 行列を合成し、2×2行列に戻す
matrix = numpy.dot(m1, m2)
return numpy.array([matrix[0], matrix[1]])
# 画像を読み込む
image = cv2.imread("Sample.jpg")
# 画像のサイズを取得する
height, width = image.shape[:2]
# X軸・Y軸それぞれのせん断角度を設定する
angle_x = numpy.deg2rad(30)
angle_y = numpy.deg2rad(10)
# せん断用の行列を作成する
sheared = numpy.float32([[1, numpy.tan(angle_x), 0], [numpy.tan(angle_y), 1, 0]])
# スケーリング行列を算出する
scaling = numpy.float32([[0.5, 0, 0], [0, 0.5, 0]])
# 画像のせん断および縮小を行う
# ただし、変換行列は「せん断 * スケーリング」の順番で行う
sheared = cv2.warpAffine(image, composite(scaling, sheared), (width, height))
# せん断後の画像をPNG形式で保存する
cv2.imwrite("Sheared.png", sheared)
# せん断後の画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", sheared)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

今回のサンプルプログラムでは、通常どおりせん断するだけでは、画像がウィンドウをはみ出すため、縮小用のスケーリング行列を作成しました。ただし、2つの行列を合成する必要があるため、別途「composite()関数」を作成し、内部で2つの行列の積を求めています。せん断行列とスケーリング行列を合成すると、せん断した画像がウィンドウ内に表示されます。
【応用編2】図形を検出するための関数・メソッド

OpenCVでは、画像内に特定の形状が含まれているかを検出することも可能です。ここでは、以下の3つのポイントに分けて、図形検出のための関数・メソッドを解説します。
- 画像内の円を検出する
- 画像内の直線を検出する
- 画像内の輪郭を検出する
画像内の円を検出する
「cv2.HoughCircles()関数」を以下の構文で使用すると、画像内に含まれる円を検出できます。
circles = cv2.HoughCircles(クレースケールの画像データ,
検出アルゴリズム,
dp = 検出の解像度,
minDist = 円同士の最低距離,
param1 = エッジ検出の閾値,
param2 = 円の中心を検出する閾値,
minRadius = 円の半径の下限値,
maxRadius = 円の半径の上限値)
検出アルゴリズムは、基本的に「cv2.HOUGH_GRADIENT」を指定すればOKです。まずは、以下の画像を「Graph.jpg」という名称で保存しサンプルコードを実行しましょう。

//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 「numpy」ライブラリをimportする
import numpy
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Graph.jpg")
# 読み込んだ画像をグレースケールに変換する
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# グレースケール画像から円を検出する
# 第1引数はグレースケール画像
# 第2引数は検出アルゴリズム(基本的にcv2.HOUGH_GRADIENTを指定)
# 「dp引数」は円の検出の解像度
# 「minDist引数」は円同士の最低距離
# 「param1引数」はエッジ検出の閾値
# 「param2引数」は円の中心を検出する閾値
# 「minRadius引数」は円の半径の下限値
# 「maxRadius引数」は円の半径の上限値
circles = cv2.HoughCircles(gray,
cv2.HOUGH_GRADIENT,
dp = 2,
minDist = 30,
param1 = 100,
param2 = 80,
minRadius = 0,
maxRadius = 0)
# 浮動小数点値から整数値に数値を丸めて、16ビット値にキャストする
circles = numpy.uint16(numpy.around(circles))
# 検出した円の輪郭線を元の画像に描画する
for circle in circles[0, :]:
# 円周を描画する
cv2.circle(image, (circle[0], circle[1]), circle[2], (0, 0, 0), 5)
# 中心点を描画する
cv2.circle(image, (circle[0], circle[1]), 2, (255, 255, 255), 10)
# 検出した円を描画した画像を保存する
cv2.imwrite("Detect Circles.jpg", image)
# 検出した円を描画した画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", image)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果
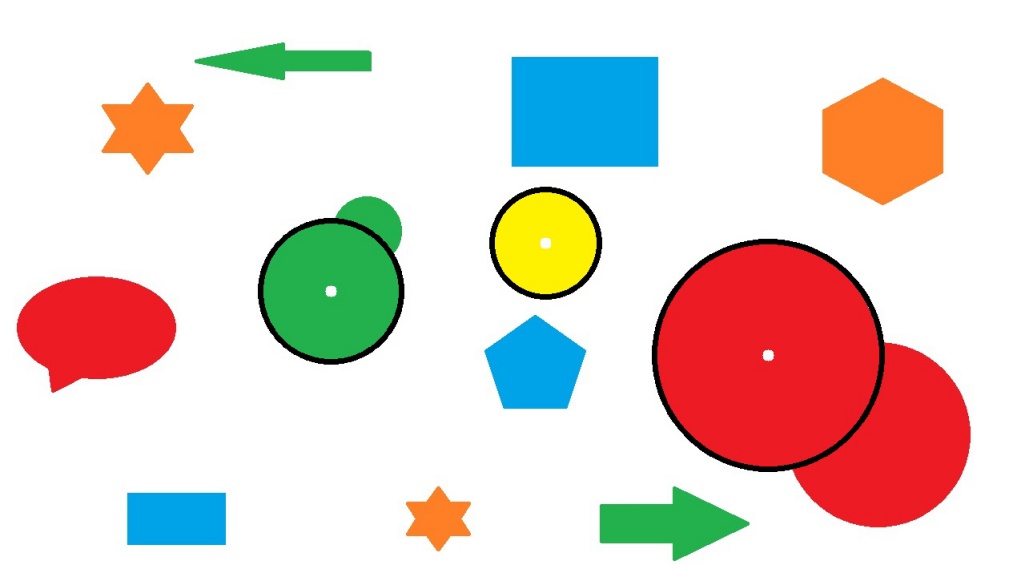
「dp」「minDist」「param1」「param2」の4つの引数は、画像の種類や解像度などに応じて、適切な検出が行われるように調整する必要があります。「dp」は基本的に1~2の範囲、「param1」は100前後に設定すればOKです。「minDist」の値が小さすぎると、同じ円が複数回検出されてしまうため、適宜値を大きくして調整しましょう。「param2」は、円検出の精度に最も大きな影響を与える要素です。例えば、上記の例でparam2を70に下げると、このように誤検出が多くなるので注意が必要です。
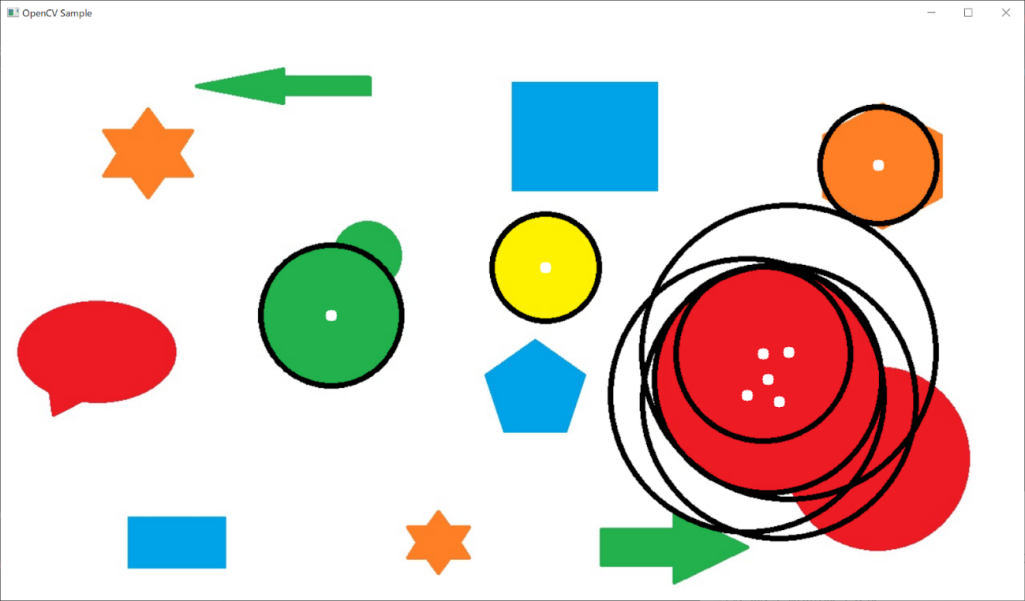
画像内の直線を検出する
「cv2.HoughLinesP()関数」を以下の構文で使用すると、画像内の直線を検出できるようになります。
lines = cv2.HoughLinesP(白黒を反転させたグレースケール画像,
rho = 直角座標点と直線の距離,
theta = 直角座標点と直線の角度,
threshold = 直線判定の閾値,
minLineLength = 直線の最小の長さ,
maxLineGap = 異なる直線とみなす最大距離)
「rho」「theta」引数についてはデフォルト値、「threshold引数」は100前後の数値でOKです。「minLineLength引数」が検出精度のカギを握っているため、適切な検出が行われるよう調整する必要があります。minLineLengthが小さすぎると検出誤差が増え、大きすぎると必要な直線が検出されません。maxLineGapは、値を大きくすると同一直線と判定される部分が増えるので、適切な値を設定するように注意が必要です。
以下の画像を「Lines.jpg」という名称で保存してから、サンプルコードを実行しましょう。

//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 「numpy」ライブラリをimportする
import numpy
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Lines.jpg")
# 読み込んだ画像をグレースケールに変換する
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# グレースケール画像の白と黒を反転させる
reversed_gray = cv2.bitwise_not(gray)
# グレースケール画像から円を検出する
# 第1引数は白黒を反転させたグレースケール画像
# 「rho引数」は直角座標点と直線の距離
# 「theta引数」は直角座標点と直線の角度
# 「threshold引数」は直線判定の閾値
# 「minLineLength引数」は直線の最小の長さ
# 「maxLineGap引数」は異なる直線とみなす最大距離
lines = cv2.HoughLinesP(reversed_gray,
rho = 1,
theta = numpy.pi / 360,
threshold = 80,
minLineLength = 250,
maxLineGap = 10)
for line in lines:
# 円周を描画する
x1, y1, x2, y2 = line[0]
# 円周を描画する
line_img = cv2.line(image, (x1, y1), (x2, y2), (0, 0, 0), 3)
# 検出した円を描画した画像を保存する
cv2.imwrite("Detect Lines.jpg", image)
# 検出した円を描画した画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", image)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

画像内の輪郭を検出する
画像内の「輪郭」を検出することもできます。ただし、そのためにはまず前処理を行う必要があります。それは、グレースケール化した画像を、以下のように「cv2.threshold()関数」で2値化、つまり白と黒の2色だけの画像にすることです。
結果, 2値化した画像データ = cv2.threshold(グレースケール画像, 白黒の閾値, 255, cv2.THRESH_BINARY)
このcv2.threshold()関数の第2引数が、輪郭検出の精度を左右します。これは、閾値以下の色を「黒」・閾値以上の色を「白」に2値化するためのものです。この時点で適切な処理を行っておくと、その後の輪郭検出が行いやすくなります。第3引数と第4引数は、基本的にデフォルトで固定でOKです。
グレースケール画像を2値化したあとは、以下の構文でcv2.findContours()関数を使用しましょう。
輪郭データ, 階層構造 = cv2.findContours(2値化した画像データ, 輪郭抽出モード, 輪郭の近似手法)
「輪郭抽出モード」として、以下の値を設定できます。
| cv2.RETR_EXTERNAL | 最も外側の輪郭のみを検出する |
| cv2.RETR_LIST | すべての輪郭を検出するが、階層構造を持たない |
| cv2.RETR_CCOMP | すべての輪郭を検出し、2階層構造を持つデータとする |
| cv2.RETR_TREE | すべての輪郭を検出したうえで、入れ子構造になった階層構造を有し、完全な輪郭を表現できる |
「輪郭の近似手法」には、以下のいずれかの値を設定できます。
| cv2.CHAIN_APPROX_NONE | すべての輪郭点を格納する |
| cv2.CHAIN_APPROX_SIMPLE | 垂直・水平・斜めの成分を圧縮して、それらの端点を保持する |
| cv2.CHAIN_APPROX_TC89_L1 | Teh-Chinチェーンの近似アルゴリズムを使用する |
| cv2.CHAIN_APPROX_TC89_KCOS | Teh-Chinチェーンの近似アルゴリズムを使用する |
基本的には、輪郭抽出モードは「cv2.RETR_EXTERNAL」、輪郭の近似手法は「cv2.CHAIN_APPROX_SIMPLE」でOKです。詳細は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 「numpy」ライブラリをimportする
import numpy
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Sample.jpg")
# 読み込んだ画像をグレースケールに変換する
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 画像を白と黒に「2値化」する
# 第2引数の閾値の調整がポイント
# この数値次第で輪郭検出の精度が決まる
result, threshold = cv2.threshold(gray, 128, 255, cv2.THRESH_BINARY)
# 画像の輪郭を検出する
# 引数は基本的に固定でOK
contours, hierarchy = cv2.findContours(threshold, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 検出した輪郭線を画像に表示する
# 第3引数は輪郭線の閾値で、基本的に「-1」で固定
# 第4引数は描画する輪郭線の色
# 第5引数は輪郭線の太さ
output = cv2.drawContours(image, contours, -1, (255, 255, 255), 3)
# 検出した輪郭線を描画した画像を保存する
cv2.imwrite("Detect Edges.jpg", output)
# 検出した輪郭線を描画した画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", output)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

ちなみに、cv2.threshold()関数で「2値化」した画像は、以下のように完全な白黒画像になっています。

【実践編1】AI・ディープラーニングを活用した「特徴量の抽出」

画像内の顔や目などの検出は、AI・ディープラーニングの活用で実現できます。AIやディープラーニングというと「難しそう」に思えるかもしれません。しかし、OpenCVでは既存の「カスケード分類器」を使えば簡単に顔や目の検出ができます。
カスケード分類器とは、検出対象の特徴を膨大な画像データからまとめたものです。つまり、「どんな特徴のある部分が顔や目なのか」をAIに学習させることで、どんな画像でもある程度の精度で検出できるようになります。このように、画像から一定の要素を抽出することを「特徴量の抽出」と呼びます。
続いて実践編として、AI・ディープラーニングおよびカスケード分類器を活用した、顔と目の検出テクニックについて解説しましょう。
画像内の顔を検出する
顔検出を行うためには、ディープラーニング技術を活用する必要があります。そのための「カスケード分類器」として、以下のサイトから「haarcascade_frontalface_default.xml」をダウンロードし、Pythonのメインモジュールと同じディレクトリに「Face Cascade.xml」という名称で保存しましょう。
https://github.com/opencv/opencv/tree/master/data/haarcascades
そのうえで、以下の構文で「cv2.CascadeClassifier()関数」の引数に、XMLファイルのパスを指定してカスケードオブジェクトを生成します。それから、そのカスケードオブジェクトの「detectMultiScale()関数」を以下の構文で利用すると、顔検出を行うことが可能です。
検出した顔部分の矩形データ = カスケード分類器.detectMultiScale(グレースケール画像)
以下の画像を「Face.png」という名称で、Pythonのメインモジュールと同じディレクトリに保存したうえで、サンプルコードを実行しましょう。

引用元:Photo AC
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# OpenCVで顔検出を行うためには、ディープラーニング技術の活用が必須
# そのために「カスケード分類器」が必要なので、既存ファイルからカスケードオブジェクトを生成する
face_cascade = cv2.CascadeClassifier("Face Cascade.xml")
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Face.png")
# 読み込んだ画像をグレースケールに変換する
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 画像内のすべての顔を検出する
faces = face_cascade.detectMultiScale(gray)
# 戻り値に顔部分の矩形データが格納されるので、すべての矩形を描画する
for x, y, w, h in faces:
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 3)
# 検出した顔矩形を描画した画像を保存する
cv2.imwrite("Detect Faces.png", image)
# 検出した顔矩形を描画した画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", image)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

このように、カスケード分類器を利用することで、顔部分がしっかり検出されています。さらに、顔部分を示す矩形の範囲も適切なので、さまざまな場面で活用できるでしょう。
画像内の目を検出する
目を検出する手順も、基本的には先ほどと同じです。以下のサイトから「haarcascade_eye.xml」をダウンロードし、Pythonのメインモジュールと同じディレクトリに「Eye Cascade.xml」という名称で保存しましょう。画像については、先ほどと同じものを使用してください。
https://github.com/opencv/opencv/tree/master/data/haarcascades
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# OpenCVで顔検出を行うためには、ディープラーニング技術の活用が必須
# そのために「カスケード分類器」が必要なので、既存ファイルからカスケードオブジェクトを生成する
eye_cascade = cv2.CascadeClassifier("Eye Cascade.xml")
# 画像ファイルを読み込む
# CV2はASCII文字にしか対応していないため
# ファイルパスに日本語を含めるとエラーが出る
image = cv2.imread("Eye.png")
# 読み込んだ画像をグレースケールに変換する
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 画像内のすべての目を検出する
eyes = eye_cascade.detectMultiScale(gray)
# 戻り値に目の部分の矩形データが格納されるので、すべての矩形を描画する
for x, y, w, h in eyes:
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 3)
# 検出した目の矩形を描画した画像を保存する
cv2.imwrite("Detect Eyes.png", image)
# 検出した目の矩形を描画した画像をウィンドウに表示する
# ウィンドウ名もアスキー文字のみ対応
cv2.imshow("OpenCV Sample", image)
# ユーザーのキー入力を待つ
cv2.waitKey(0)
# すべてのウィンドウを閉じる
cv2.destroyAllWindows()
//実行結果

カスケード分類器のファイルを指定する部分以外は、顔検出のときと同じソースコードになります。しかし、このように誤検出が発生しており、髪や鼻の一部が目として認識されていることが課題です。顔検出と比べて目の検出は、高い精度で実現するのが難しいものと考えられます。
【実践編2】画像のヒストグラムを解析する

画像のヒストグラムを解析するためには、「cv2.calcHist()関数」を使用します。ヒストグラムとは、横軸に画素値・縦軸にその個数を取るグラフのことです。画素値はR・G・Bの3つの要素から構成され、それぞれ0~255の値を取ります。
ただし、そのデータを表示するためには、「Matplotlib」などのグラフ描画ライブラリの活用が必須です。先ほど顔と目の検出で使用したものと同じファイルを「Face.png」という名称で保存して、以下のサンプルコードを実行しましょう。
//サンプルプログラム
# coding: UTF-8
# 「CV2」ライブラリをimportする
import cv2
# 「numpy」ライブラリをimportする
import numpy
# matplotlibライブラリから「pyplot」モジュールをimportする
from matplotlib import pyplot
# 画像ファイルを読み込む
image = cv2.imread("Face.png")
# 画像の色相分布を行列形式に変換し、ヒストグラムをプロットする
for i, c in enumerate(("b", "g", "r")):
histogram = cv2.calcHist(images = [image], channels = [i], mask = None, histSize = [256], ranges = [0, 256])
pyplot.plot(histogram, color = c)
pyplot.xlim([0, 256])
# ヒストグラムを画面上に表示する
pyplot.show()
//実行結果
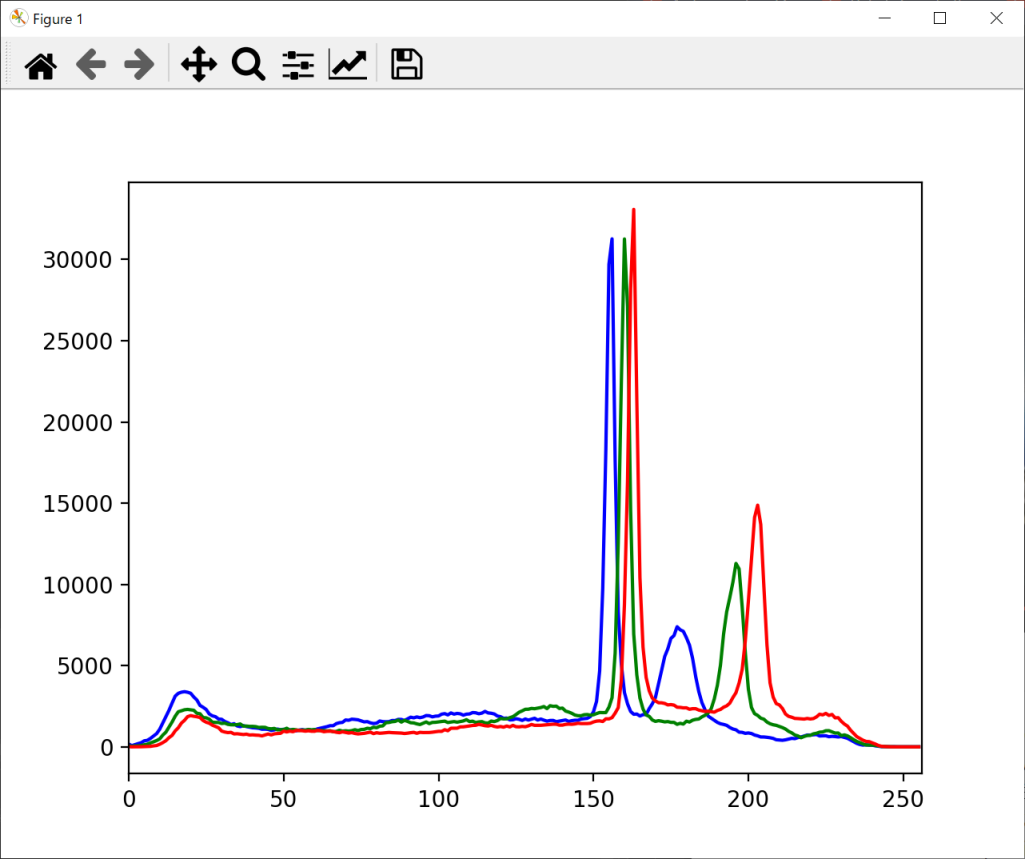
上記のように、この画像では赤・緑・青ともに、150~170前後の値の要素が最も多いことが分かります。このようにヒストグラムを解析することで、画像加工や編集にも役立つでしょう。なお、「Matplotlib」の使い方については、以下の記事を参考にしてみてください。
https://one-div.com/programming/python/how-to-python-matplotlib
PythonのOpenCVで高度な画像編集にチャレンジしよう

PythonのOpenCVを活用すると、高度な画像編集を行うことができます。画像の平行移動・拡大縮小・回転はもちろん、AIやディープラーニングを活用した顔や目の検出も可能です。OpenCVは、単純なソースコードでハイレベルな処理が行えるため、専門知識がなくても気軽に使えます。この機会にぜひ、PythonのOpenCVで画像処理にチャレンジしてみてください。











アクセスランキング 人気のある記事をピックアップ!
コードカキタイがオススメする記事!

2024.06.17
子供におすすめのプログラミングスクール10選!学習メリットや教室選びのコツも紹介
#プログラミングスクール

2022.01.06
【完全版】大学生におすすめのプログラミングスクール13選!選ぶコツも詳しく解説
#プログラミングスクール

2024.01.26
【未経験でも転職可】30代におすすめプログラミングスクール8選!
#プログラミングスクール

2024.01.26
初心者必見!独学のJava学習方法とおすすめ本、アプリを詳しく解説
#JAVA

2024.01.26
忙しい社会人におすすめプログラミングスクール15選!失敗しない選び方も詳しく解説
#プログラミングスクール

2022.01.06
【無料あり】大阪のおすすめプログラミングスクール14選!スクール選びのコツも紹介
#プログラミングスクール

2024.01.26
【目的別】東京のおすすめプログラミングスクール20選!スクール選びのコツも徹底解説
#プログラミングスクール

2024.01.26
【無料あり】福岡のおすすめプログラミングスクール13選!選び方も詳しく解説
#プログラミングスクール

2024.01.26
【徹底比較】名古屋のおすすめプログラミングスクール13選!選び方も詳しく解説
#プログラミングスクール

2024.01.26
【徹底比較】おすすめのプログラミングスクール18選!失敗しない選び方も徹底解説
#プログラミングスクール