
プログラミング言語「Python」は、数学・統計学・画像処理などさまざまな分野で活用しています。こうしたデータを扱う分野では、「ヒストグラム」を使う場面が多々あることでしょう。ヒストグラムとは、データを複数区間に分割し、区間ごとの値を棒グラフ形式で示したものです。ヒストグラムを見ることで分布状況を把握でき、データの分析や活用に役立ちます。
このヒストグラムをPythonで表示するためには、「Matplotlib」というグラフ描画ライブラリが必要です。Matplotlibを活用すると、簡単な操作でデータのヒストグラム化ができます。本記事では、PythonでMatplotlibライブラリを活用して、ヒストグラムを表示する方法をサンプルコード付きで解説します。
目次
「ヒストグラム」とは?

「ヒストグラム」とは、横軸に階級・縦軸に度数を示す統計グラフとなります。対象となるデータを一定数に分割し、その区間ごとの値を棒グラフ形式で描画したグラフです。
ヒストグラムは、データの分布状況を可視化するために、数学・統計学・画像処理など幅広い分野で活用されています。たとえば、以下のヒストグラムは、50人の生徒を対象に行ったテストの結果を示すものです。
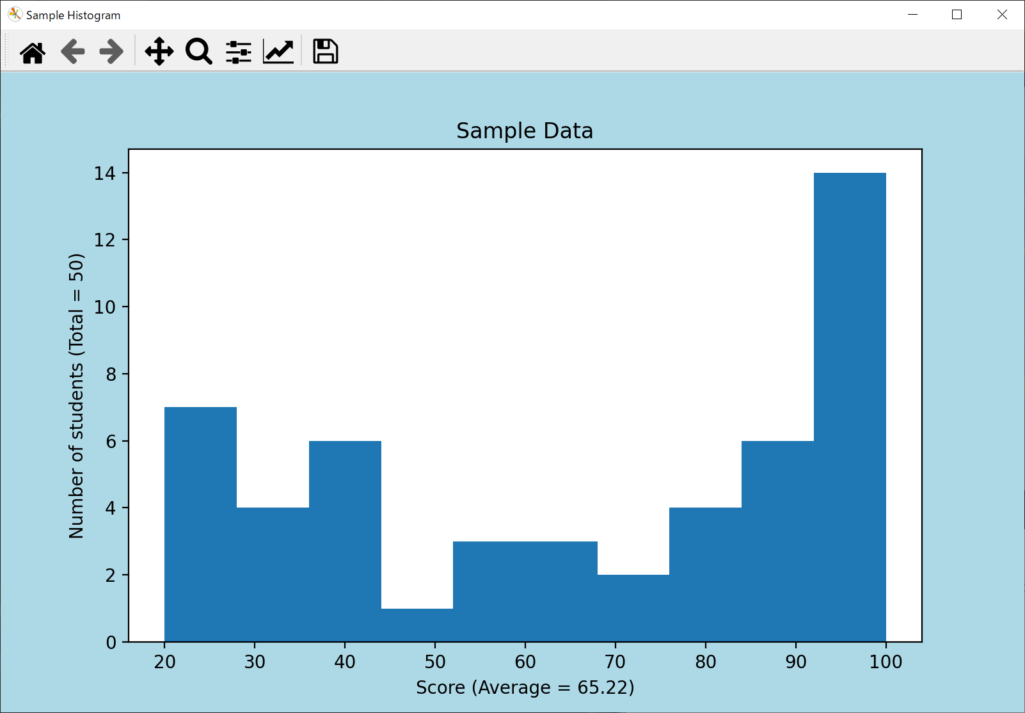
ヒストグラムを作成することで、単なる平均点や偏差値では把握しきれない、点数ごとの人数分布を可視化できます。これにより、生徒の全体的な理解度を把握することが可能です。
平均点が比較的高い状態であっても、上記のグラフのように低い階級の度数が大きければ、理解が追い付いていない生徒が一定数いることがわかります。
ヒストグラムのこうした特性を踏まえたうえで、ここからはPython言語でヒストグラムを作成・表示する方法を解説していきましょう。
Pythonでのヒストグラム作成には「Matplotlib」が必要

Pythonは機能性が高い便利なプログラミング言語ですが、単体ではヒストグラムを表示できません。Pythonでヒストグラムを作成・表示するためには、「Matplotlib」というグラフ描画ライブラリが必要です。Matplotlibは、科学計算用ライブラリの「NumPy」と組み合わせて使うことが多く、データを可視化・分析する用途で広く活用されています。
Pythonでヒストグラムを作成・表示するために必要なMatplotlibとPythonについて、以下の3つのポイントから見ていきましょう。
- MatplotlibはPythonのグラフ描画ライブラリ
- NumPyは科学技術計算を行うためのライブラリ
- MatplotlibとNumPyのインストール方法・手順
MatplotlibはPythonのグラフ描画ライブラリ
「Matplotlib」は、Pythonでグラフを描画するためのライブラリです。あらゆる種類・形状のグラフをシンプルなソースコードでの描画が可能なため、専門知識がなくても複雑なデータをわかりやすく可視化できます。そのため、幅広い分野でデータ利活用の手段として活用されているのです。後述する「NumPy」と組み合わせて、演算とデータ分析を行ったり、高度な画像編集・解析を行ったりすることも可能となります。
NumPyは科学技術計算を行うためのライブラリ
「NumPy」は、数値計算を効率的に行うための科学計算ライブラリです。行列やベクトルの演算に長けていることから、高度な演算や画像処理の分野で活用されています。NumPy本体はC言語で実装されており、実行速度の速さが大きな魅力です。こうした性質から、MatplotlibとNumPyは、非常に相性のよいライブラリだといえます。
MatplotlibとNumPyのインストール方法・手順
MatplotlibとNumPyは、いずれもPythonの標準機能ではないため、あらかじめインストールしておく必要があります。まずは、Matplotlibとセットで使用する「NumPy」をインストールするために、Pythonのアップデートが必要です。コマンドプロンプトで以下のPIPコマンドを入力しましょう。
py -m pip install --upgrade pip
上記のコマンドは、Pythonのパッケージを最新バージョンにアップデートするためのもので、完了すると次のように「Successfully installed pip」と表示されます。
そのうえで、以下のコマンドを入力してNumPyライブラリをインストールしましょう。
py -m pip install numpy
Matplotlibのインストールは、次のPIPコマンドで行います。以上の手順で、便利なグラフ描画ライブラリMatplotlibが使用可能です。
py -m pip install matplotlib
【基礎編】ヒストグラムを作成する方法・手順

まずは、ヒストグラム作成の全体像を把握するために、冒頭で紹介したものと同じグラフを作成してみましょう。以下のサンプルコードを実行するだけで、わかりやすいヒストグラムを簡単に表示できます。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# ヒストグラムを作成するためのデータを用意する
data = [20, 21, 22, 22, 24, 26, 27, 29, 30, 31,
33, 36, 36, 38, 41, 43, 43, 48, 52, 55,
58, 61, 63, 66, 73, 74, 76, 78, 81, 83,
84, 84, 86, 87, 88, 90, 92, 93, 93, 94,
95, 95, 97, 98, 98, 98, 99, 100, 100, 100]
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "Sample Histogram", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
axes.hist(data, bins = 10)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
axes.set_title("Sample Data")
axes.set_xlabel(f"Score (Average = {np.average(data)})")
axes.set_ylabel(f"Number of students (Total = {len(data)})")
# プロットを表示する
plt.show()
// 実行結果
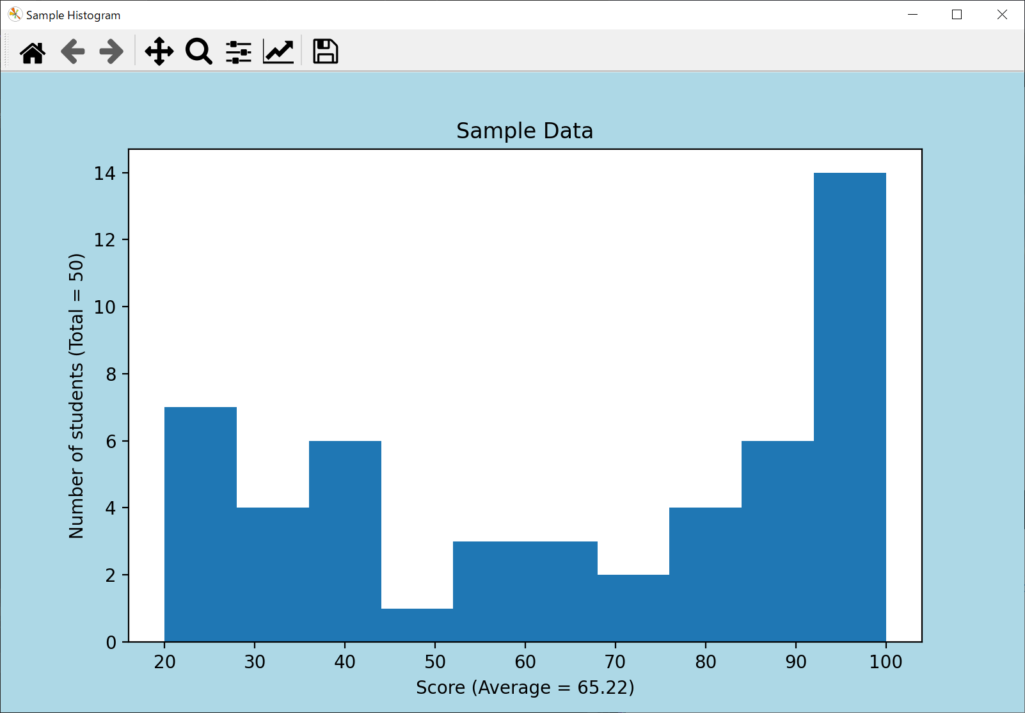
上記のサンプルコードを踏まえて、PythonとMatplotlibでヒストグラムを作成する手順を詳しく見ていきましょう。
- ヒストグラムの基になるデータを用意する
- 描画領域となるFigureオブジェクトを作成する
- グラフを描画するためのAxesオブジェクトを追加する
- データを基にしてヒストグラムを作成する
- プロットをウィンドウに表示する
ステップ1:ヒストグラムの基になるデータを用意する
ヒストグラムは、データ内の値の分布状況を表示するためのグラフです。そのため、ヒストグラムの基になるデータがなければ、ヒストグラムは作成できません。先ほどのサンプルコードのように、リスト形式でデータを用意して、「hist()」関数に引き渡すことでヒストグラムを作成できます。
なお、ヒストグラムの用途によっては、「ランダムなデータ」を生成したいこともあるでしょう。その場合は、NumPyの「randomクラス」などに搭載されている以下のような関数を利用することで、便利なデータを用意できます。
| 関数・メソッド | 特徴 | 引数 |
|---|---|---|
| np.random.randn() | 平均値0・標準偏差1の「標準正規分布」の乱数を生成する | 生成する乱数の数 |
| np.random.normal() | 正規分布(ガウス分布)の乱数を生成する | 第1引数:平均値 第2引数:標準偏差 第3引数:乱数の数 |
| np.random.randint() | 整数値の乱数を生成する | 第1引数:最小値 第2引数:最大値 第3引数:乱数の数 |
| np.random.uniform() | 任意の範囲の連続一様分布の乱数を生成する | 第1引数:最小値 第2引数:最大値 第3引数:乱数の数 |
目的に応じて以上のような関数を利用すると、手作業で値を指定することなくヒストグラム作成に必要なデータを生成できます。実際にこれらの関数を利用して、データを自動生成してみましょう。
// サンプルプログラム # coding: UTF-8 # 「matplotlib」ライブラリをimportする import matplotlib # 「matplotlib.pyplot」ライブラリをimportする # ソースコードを簡潔にするため、「plt」というエイリアスを付ける import matplotlib.pyplot as plt # 「numpy」ライブラリをimportする # ソースコードを簡潔にするため、「np」というエイリアスを付ける import numpy as np # 標準正規分布の乱数を10個生成する # 生成するリストは平均値0・標準偏差1の正規分布となる print(np.random.randn(10)) # 正規分布(ガウス分布)の乱数を生成する # 第1引数は平均値・第2引数は標準偏差・第3引数は数値の数 print(np.random.normal(0, 10, 10)) # 0~99の整数値で10個の乱数を生成する # 第1引数は最小値・第2引数は最大値・第3引数は数値の数 print(np.random.randint(0, 100, 10)) # 0~99の整数値で(3×3)の行列を生成する print(np.random.randint(0, 100, (3, 3))) # 任意の範囲の連続一様分布のリストを生成する # 第1引数は最小値・第2引数は最大値・第3引数は数値の数 print(np.random.uniform(-100, 100, 10)) // 実行結果
上記のサンプルプログラムでは、NumPyのさまざまな乱数生成の関数を活用して、乱数のデータを生成しています。ただし、これらの関数は実行速度の観点から、現在では非推奨とされているのです。パフォーマンスを重視する場合は、より高速な乱数生成ができる以下の関数を利用しましょう。
| 関数・メソッド | 特徴 | 引数 |
|---|---|---|
| Generator.standard_normal() | 平均値0・標準偏差1の「標準正規分布」の乱数を生成する | 生成する乱数の数 |
| Generator.normal() | 正規分布(ガウス分布)の乱数を生成する | 第1引数:平均値 第2引数:標準偏差 第3引数:乱数の数 |
| Generator.integers() | 整数値の乱数を生成する | 第1引数:最小値 第2引数:最大値 第3引数:乱数の数 |
| Generator.uniform() | 任意の範囲の連続一様分布の乱数を生成する | 第1引数:最小値 第2引数:最大値 第3引数:乱数の数 |
いずれのメソッドも、引数の種類は通常の関数と同じです。しかし、これらの関数を呼び出す前に、「np.random.default_rng()」で「乱数発生器」を作成しておく必要があります。詳細は以下のサンプルコードのとおりです。
// サンプルプログラム # coding: UTF-8 # 「matplotlib」ライブラリをimportする import matplotlib # 「matplotlib.pyplot」ライブラリをimportする # ソースコードを簡潔にするため、「plt」というエイリアスを付ける import matplotlib.pyplot as plt # 「numpy」ライブラリをimportする # ソースコードを簡潔にするため、「np」というエイリアスを付ける import numpy as np # 乱数を取得するための「乱数発生器」を生成する # この乱数発生器から各メソッドを呼び出すことで、高速な乱数生成ができる rng = np.random.default_rng() # 標準正規分布の乱数を10個生成する # 生成するリストは平均値0・標準偏差1の正規分布となる print(rng.standard_normal(10)) # 正規分布(ガウス分布)の乱数を生成する # 第1引数は平均値・第2引数は標準偏差・第3引数は数値の数 print(rng.normal(0, 10, 10)) # 0~99の整数値で10個の乱数を生成する # 第1引数は最小値・第2引数は最大値・第3引数は数値の数 print(rng.integers(0, 100, 10)) # 0~99の整数値で(3×3)の行列を生成する print(rng.uniform(0, 100, (3, 3))) # 任意の範囲の連続一様分布のリストを生成する # 第1引数は最小値・第2引数は最大値・第3引数は数値の数 print(rng.uniform(-100, 100, 10)) // 実行結果
これらの関数を利用することで、ヒストグラムの表示に必要なサンプルデータを、簡単に生成できるようになります。後ほど紹介するサンプルコードでも、同様のメソッドを使用するため、ぜひ参考にしてみてください。
ステップ2:描画領域となるFigureオブジェクトを作成する
ヒストグラムを作成するためのデータが用意できたら、グラフの描画領域となる「Figureオブジェクト」を生成しましょう。Figureオブジェクトは、後述するプロットの描画に欠かせないので、プログラムの冒頭で以下のように「plt.figure()」関数で作成しておくことが重要です。
figure = plt.figure(num = "ウィンドウタイトル", figsize = (ウィンドウXサイズ, ウィンドウYサイズ), facecolor = "ウィンドウ背景色")
plt.figure()の代表的な引数は、「num」「figsize」「facecolor」の3つです。とくに重要な引数はfigsizeで、これはウィンドウのサイズを決めるためのものです。サイズの指定は「(X, Y)」のタプル形式で行いますが、その値は実際のウィンドウサイズの100分の1とします。たとえば、800×500のウィンドウを作りたい場合は、「figsize = (8, 5)」と記載すれば実行可能になります。
ステップ3:グラフを描画するためのAxesオブジェクトを追加する
Figureオブジェクトの作成後は、実際にグラフを描画するための「Axesオブジェクト」を追加します。Axesオブジェクトは、グラフの作成・設定・描画を行うためのものであるため、以下の構文で「figure.add_subplot()」関数を呼び出す必要があります。
figure.add_subplot(「Y軸方向のプロット数」「X軸方向のプロット数」「当該プロットの番号」)
figure.add_subplot()は、引数の指定方法によって、複数のグラフを並べて同時に描画できるようになります。ただし、上記のように引数の並び方が独特なことや、グラフの数だけ繰り返し呼び出す必要があるので注意が必要です。
たとえば、横方向に3つ・縦方向に2つのグラフを並べる場合は、figure.add_subplot()を6回呼び出す必要があり、引数はそれぞれ「231」「232」「233」「234」「235」「236」となります。
グラフを1つだけ描画する場合は、「figure.add_subplot(111)」と記載すればOKです。なお、桁ごとにコンマで区切って「(1, 1, 1)」としても問題ありませんが、3つ並べることが一般的でしょう。
ステップ4:データを基にしてヒストグラムを作成する
先ほどのAxesオブジェクトを使うことで、データを基にしたヒストグラムを作成できます。ヒストグラムの作成は、以下のように「axes.hist()」関数を呼び出し、必要な引数の指定で行います。
axes.hist(データリスト, bins = 階級数)
ヒストグラムの作成に欠かせない引数が「データリスト」で、ステップ1で作成したリストを指定すればOKです。「bin引数」にはヒストグラムの「階級数」、つまりグラフの分割数を指定します。bin引数のデフォルト値は「10」となっているため、指定しない場合は自動的に10階級のヒストグラムとなります。
なお、axes.hist()の引数の詳細については、このあとの「発展編」で詳しく解説するので、ぜひ参考にしてみてください。
ステップ5:プロットをウィンドウに表示する
先ほど作成したヒストグラムを表示するために、「plt.show()」関数を呼び出しましょう。ウィンドウは自動的に作成されるため、ほかのGUIライブラリなどを別途使う必要はありません。なお、グラフのタイトルやX軸・Y軸のラベルなどを指定したい場合は、以下のような関数をplt.show()の前に呼び出しましょう。
axes.set_title("グラフのタイトル")
axes.set_xlabel("X軸のラベル")
axes.set_ylabel("Y軸のラベル")
グラフにタイトルやラベルを付けることで、「どんなデータをどのように表示しているか」がわかり、データの検証や分析が行いやすくなります。ただし、Matplotlibはデフォルト状態では日本語などのマルチバイト文字を扱えないため、英数字で記載することが一般的です。
日本語で表示する必要がある場合は、以下のように「plt.rcParams[“font.family”]」プロパティで日本語フォントを指定しましょう。
plt.rcParams["font.family"] = "日本語フォント名"
先ほどのサンプルコードを日本語対応にする場合は、以下のようなサンプルコードとなります。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# ヒストグラムを作成するためのデータを用意する
data = [20, 21, 22, 22, 24, 26, 27, 29, 30, 31,
33, 36, 36, 38, 41, 43, 43, 48, 52, 55,
58, 61, 63, 66, 73, 74, 76, 78, 81, 83,
84, 84, 86, 87, 88, 90, 92, 93, 93, 94,
95, 95, 97, 98, 98, 98, 99, 100, 100, 100]
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
axes.hist(data, bins = 10)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"得点 (平均点 = {np.average(data)})")
axes.set_ylabel(f"生徒数 (合計 = {len(data)})")
# プロットを表示する
plt.show()
// 実行結果
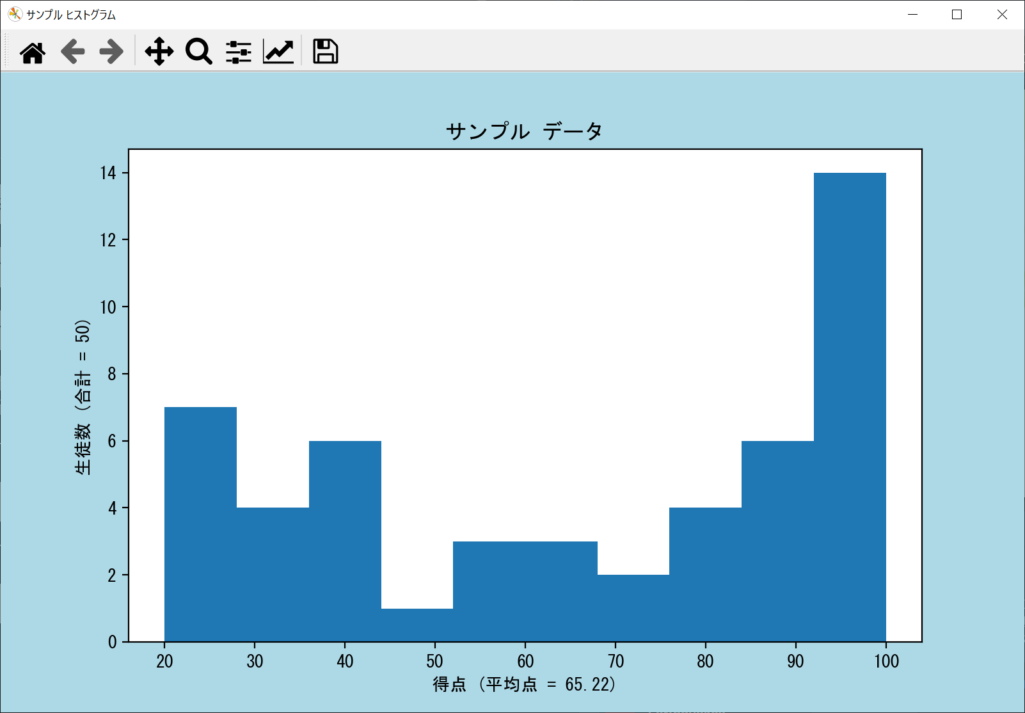
【発展編】hist()関数の引数の種類と使い方

hist()関数でとくに重要な引数については前述したとおりですが、実はそのほかにもさまざまな引数でカスタマイズができます。hist()で利用できる引数は、全15種類です。
axes.hist(x = data, bins = 10, range = None, density = False, weights = None, cumulative = False, bottom = None, histtype = "bar", align = "mid", orientation = "vertical", rwidth = None, log = False, color = None, label = None, stacked = False)
各引数の概要や初期値については、以下のとおりです。ヒストグラムの作成時に利用することが多い引数については、サンプルコードを交えてあらためて解説します。
| 引数 | 概要 | 初期値 |
|---|---|---|
| x | データリスト | data |
| bins | ヒストグラムの階級数 「”auto”」にすると自動設定 |
10 |
| range | 階級の最大値を最小値 設定しない場合は「x引数」の最大値・最小値が自動適用 |
None |
| density | 縦軸が確率密度になるように正規化するかどうか 各階級の度数がデータ総数と階級数で割ったものになる |
False |
| weights | 各要素の重みを設定するためのリスト 「x引数」と同じ要素数のリストが必要となる xに重み値を乗算した値でヒストグラムが作成される |
None |
| cumulative | 累積値を表示するかどうか 「True」にすると累積値を表示し、「-1」は逆順になる 最後または最初の度数がデータ総数となる |
False |
| bottom | 各階級の度数の基準値 スカラー値の場合は全階級が同じ値だけシフトされる リスト値の場合は各階級が独立してシフトされる |
0 |
| histtype | 描画するヒストグラムの種類 「bar」「barstacked」「step」「stepfilled」から選ぶ |
“bar” |
| align | ヒストグラムのビン(バー)の水平位置 「left」「mid」「right」から選ぶ |
“mid” |
| orientation | ヒストグラムのビン(バー)の描画方向 horizontalにするとX軸とY軸が反対になる 「vertical」「horizontal」から選ぶ |
“vertical” |
| rwidth | ヒストグラムのビン(バー)の幅を設定する 指定しない場合は自動調整となる |
None |
| log | 縦軸の度数をログスケールに設定するかどうか | False |
| color | ヒストグラムのビン(バー)の色 スカラー値や「x引数」と同じ要素数の配列で指定する |
None |
| label | ヒストグラムの凡例を指定するための文字列 | None |
| stacked | 複数のデータを重ねて配置するかどうか | False |
ここからは、以下のサンプルデータやヒストグラムを基準として、axes.hist()関数の使い方を詳しく解説します。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 50
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data = rng.standard_normal(num_data)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
axes.hist(data, bins = num_bins)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# プロットを表示する
plt.show()
// 実行結果
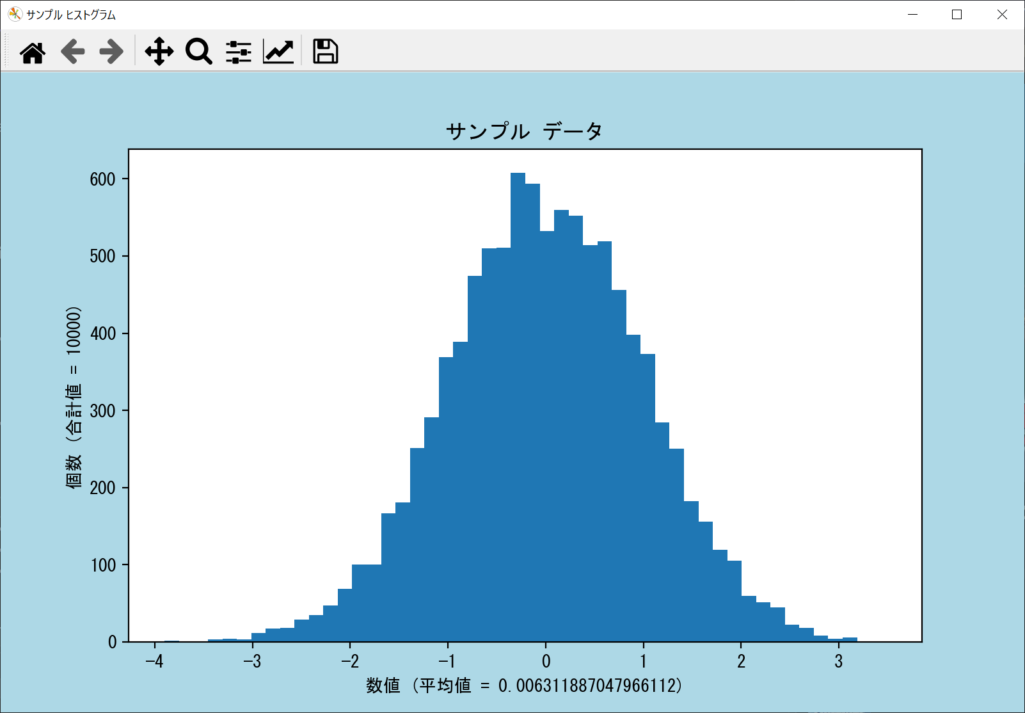
上記のサンプルプログラムは、再現性のある正規分布の乱数リストを生成し、ヒストグラムを表示するものです。今回は乱数発生器を作成したうえでリストを生成していますが、ヒストグラムの作成・描画手順は同じなので、詳細はソースコードを確認してください。
- range引数|ヒストグラムの階級の幅を変える
- density引数|ヒストグラムを正規化する
- weights|ヒストグラムの重みを設定する
- cumulative引数|累積ヒストグラムを表示する
- bottom引数|度数の底を上げ下げする
- histtype引数|ビン(バー)の外観を変更する
- orientation引数|ヒストグラムの向きを変更する
- rwidth|ビン(バー)の太さを変更する
- log引数|度数を対数スケールに変更する
- color引数|ビン(バー)の色を変更する
range引数|ヒストグラムの階級の幅を変える
ヒストグラムのX軸つまり階級の幅は、デフォルト状態ではデータの内容に応じて自動調整されます。これを手動で変更したい場合は、axes.hist()関数の「range引数」にタプル形式で「(最小値, 最大値)」のように指定しましょう。詳細は以下のサンプルコードのとおりです。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 50
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data = rng.standard_normal(num_data)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# range引数でヒストグラムの階級幅(最小値, 最大値)を指定する
axes.hist(data, bins = num_bins, range = (-10, 10))
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# プロットを表示する
plt.show()
// 実行結果
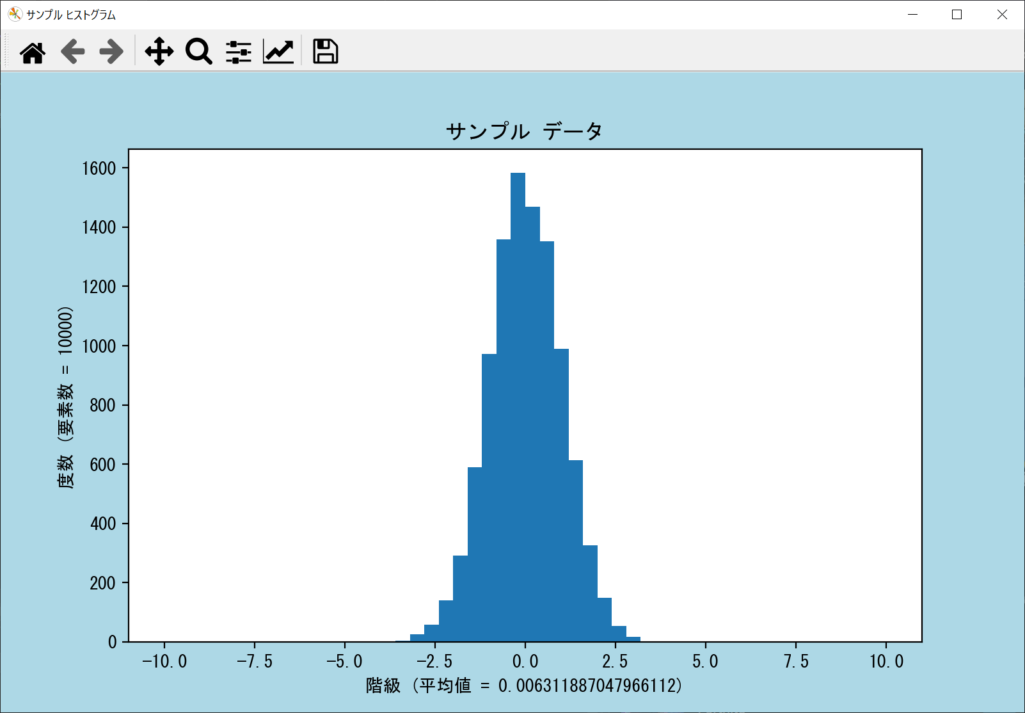
density引数|ヒストグラムを正規化する
ヒストグラムを正規化したい場合は、axes.hist()関数の「density引数」をTrueに設定しましょう。ヒストグラムを正規化することで、ビン(バー)の面積が「1」になります。ヒストグラムのdensity引数の使い方について、以下のサンプルコードで確認しましょう。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 50
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data = rng.standard_normal(num_data)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# density引数をTrueにするとヒストグラムを正規化できる
axes.hist(data, bins = num_bins, density = True)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# プロットを表示する
plt.show()
// 実行結果
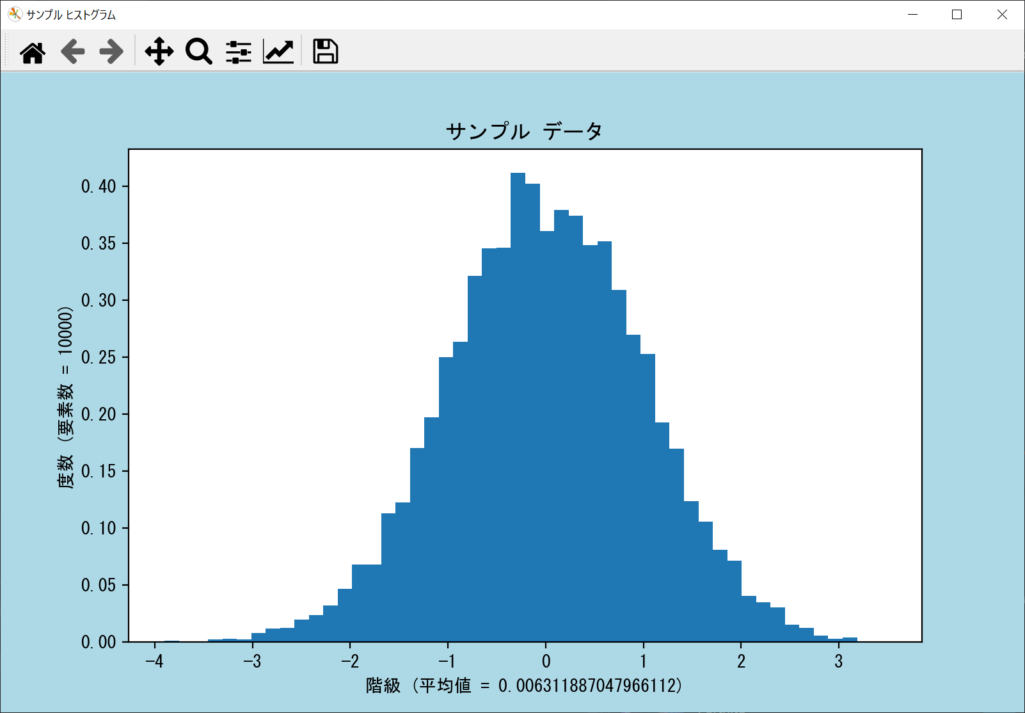
weights引数|ヒストグラムの重みを設定する
ヒストグラムに重みを付けたい場合は、axes.hist()関数の「weights引数」に重みリストを指定します。重みリストには、それぞれのデータに乗算したい値を設定するため、データと重みのリストは必ず同じサイズです。weights引数の使い方について、以下のサンプルコードで確認しましょう。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 50
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data = rng.standard_normal(num_data)
# 任意の平均値・標準偏差の乱数リストを生成する
# 乱数発生器を生成したうえでnormal()を呼び出すことがポイント
# np.random.normal()よりも高速な乱数生成が行える
# ここでは平均値1・標準偏差10の乱数リストを生成する
weight = rng.normal(0, 10, num_data)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# weights引数で重みリストを指定する
axes.hist(data, bins = num_bins, weights = weight)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# プロットを表示する
plt.show()
// 実行結果
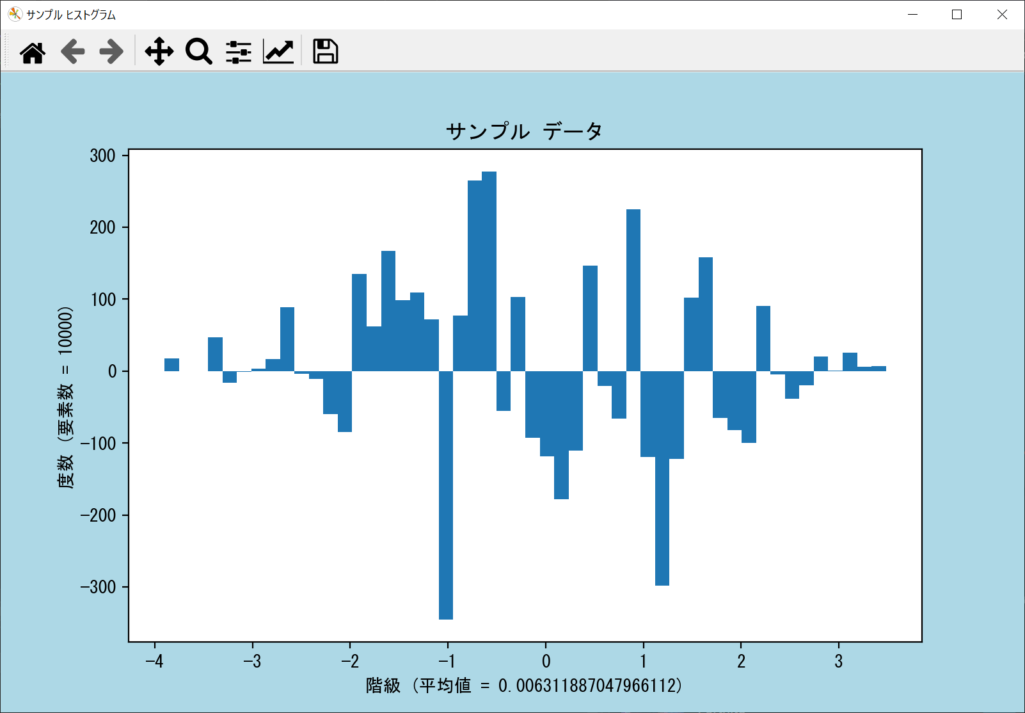
cumulative引数|累積ヒストグラムを表示する
「累積ヒストグラム」とは、直前までの全区間の度数を足し合わせた累計値を、その区間の度数とするヒストグラムです。必ず右肩上がりの棒グラフになることが特徴で、どの区間までの影響度が強いかを見極める場合に使われます。
累積ヒストグラムは、axes.hist()関数の「cumulative引数」をTrueにすると表示でき、「-1」にすると逆順で右肩下がりのグラフとなります。詳細は以下のサンプルコードのとおりです。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 50
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data = rng.standard_normal(num_data)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# cumulative引数で累積ヒストグラムを設定する
axes.hist(data, bins = num_bins, cumulative = True)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# プロットを表示する
plt.show()
// 実行結果
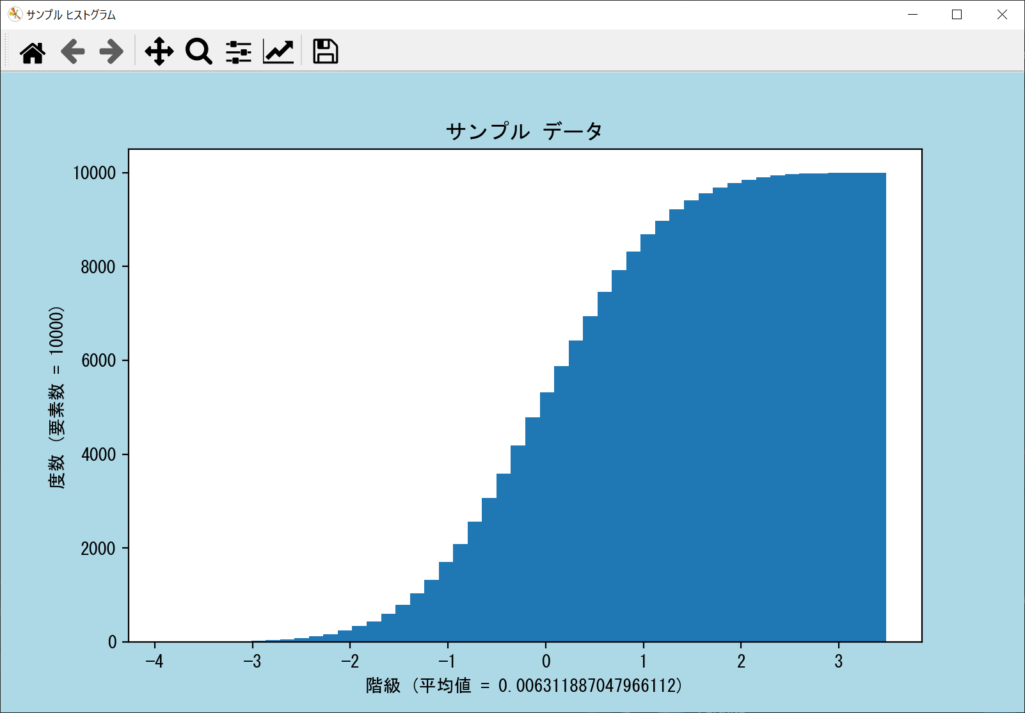
今回は正規分布のデータを使用しているため、平均値に近づくほど累積値の変化が大きく、端になるほど変化が小さくなっています。正規分布ではないデータの場合、累積ヒストグラムを使うと「どの階級の変化が大きいか」を可視化できるため、データ利活用に役立つでしょう。
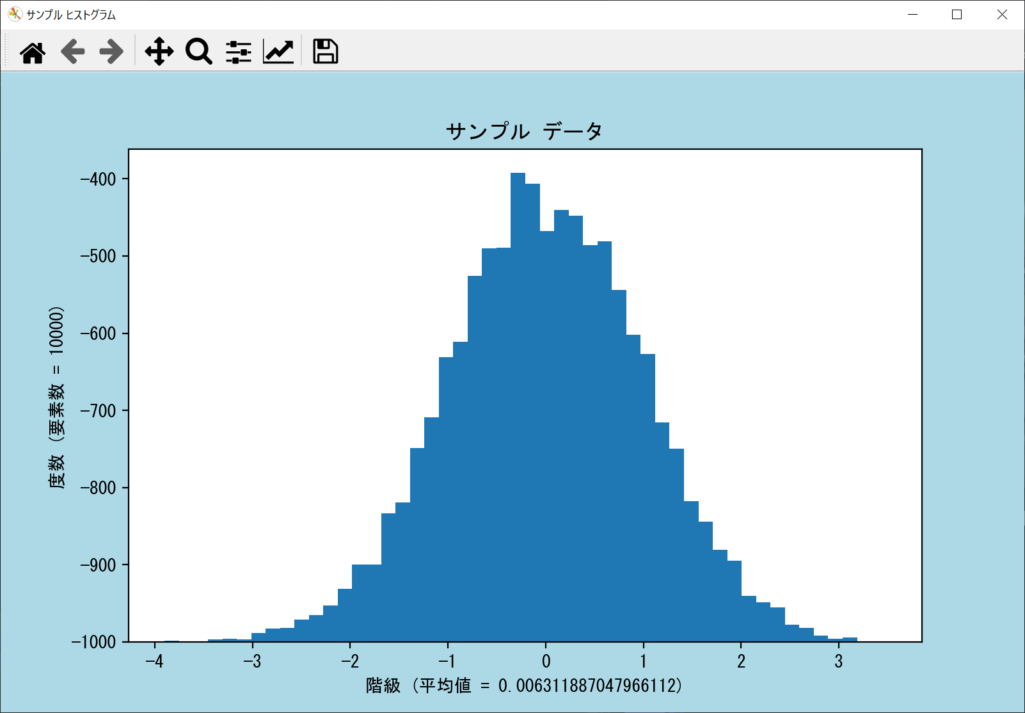
bottom引数|度数の底を上げ下げする
ヒストグラム全体の度数の「底」、つまり原点の上げ下げを行いたい場合は、axes.hist()関数の「bottom引数」に差分値を指定します。正の値の場合は底上げ、負の値の場合は引き下げとなります。bottom引数の使い方について、以下のサンプルコードで確認しましょう。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 50
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data = rng.standard_normal(num_data)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# bottom引数でヒストグラム全体の度数の「底」を上げ下げできる
axes.hist(data, bins = num_bins, bottom = -1000)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# プロットを表示する
plt.show()
// 実行結果
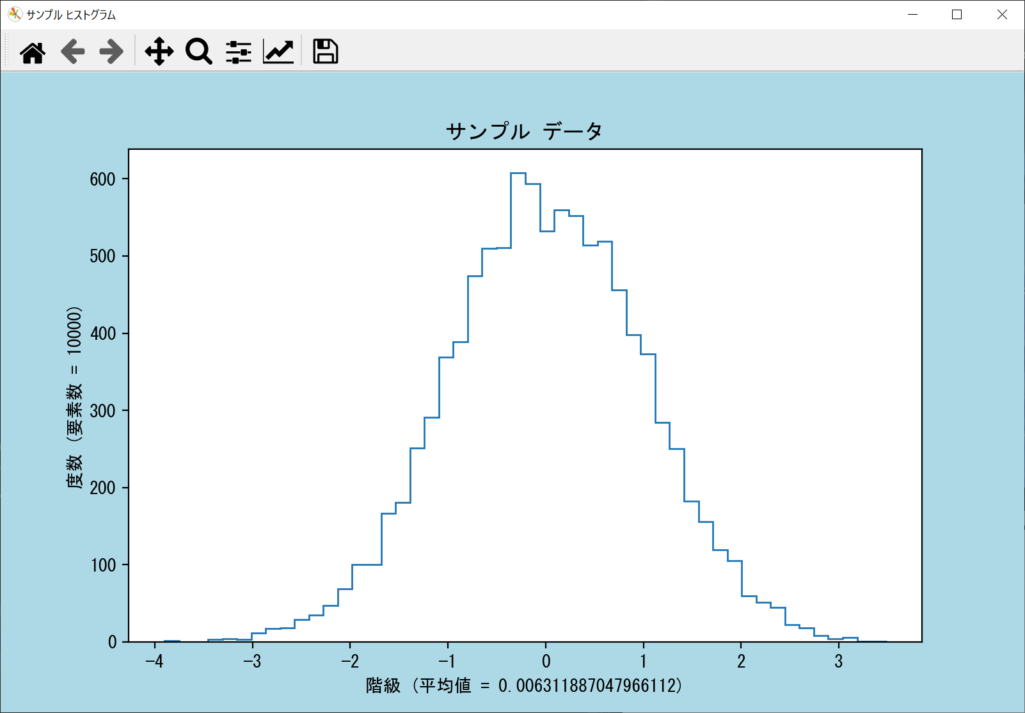
histtype引数|ビン(バー)の外観を変更する
これまで解説したサンプルプログラムは、すべて塗りつぶし形式のヒストグラムでした。ビン(バー)の外観を変更したい場合は、axes.hist()関数の「histtype引数」を指定し、値は「bar」「barstacked」「step」「stepfilled」から選びます。デフォルト状態ではbarの塗りつぶしですが、これをstepに変更することで、以下のように枠線だけの表示が可能です。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 50
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data = rng.standard_normal(num_data)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# histtype引数でヒストグラムのビン(バー)の外観を変更できる
axes.hist(data, bins = num_bins, histtype = "step")
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# プロットを表示する
plt.show()
// 実行結果
orientation引数|ヒストグラムの向きを変更する
通常のヒストグラムは横軸に階級・縦軸に度数となっています。これを逆にして、横軸を度数・縦軸を階級にしたい場合は、axes.hist()関数の「orientation引数」をhorizontalにしましょう。デフォルトはverticalですが、horizontalにすることで以下のように横向きのヒストグラムになります。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 50
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data = rng.standard_normal(num_data)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# orientation引数でヒストグラムの向きを変更できる
axes.hist(data, bins = num_bins, orientation = "horizontal")
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"度数 (要素数 = {len(data)})")
axes.set_ylabel(f"階級 (平均値 = {np.average(data)})")
# プロットを表示する
plt.show()
// 実行結果
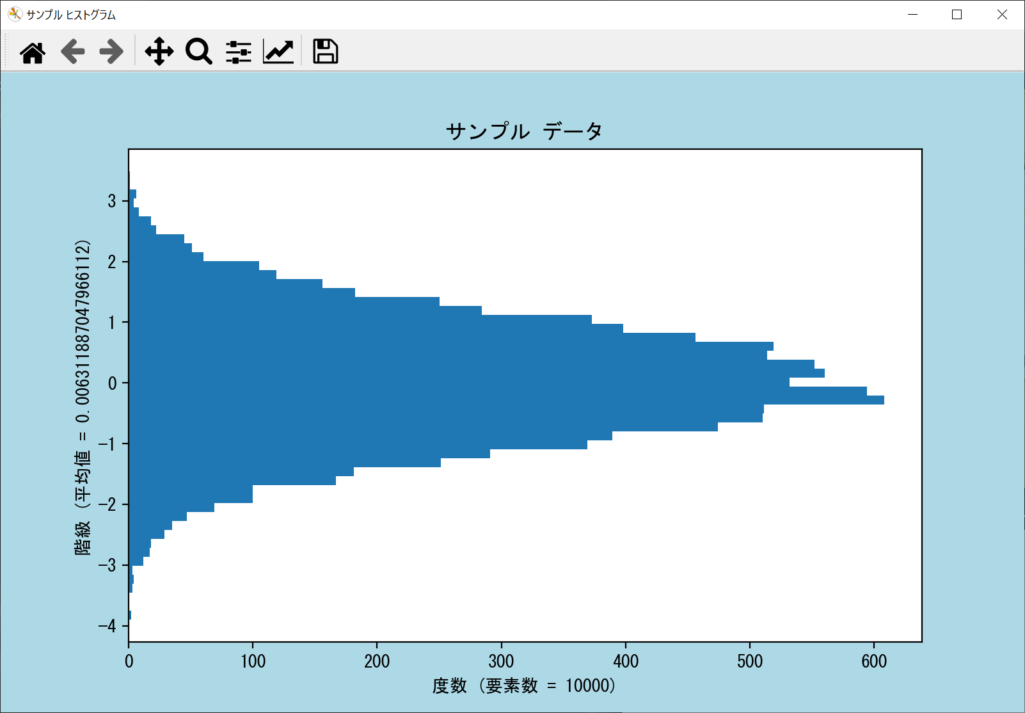
ただし、X軸とY軸のラベルはそのままの状態なので、手動で入れ替える必要があります。
rwidth引数|ビン(バー)の太さを変更する
これまでのサンプルプログラムは、各階級のビン(バー)が密接した状態です。各ビンの太さを変更したい場合は、axes.hist()関数の「rwidth引数」を1.0から0.0に近付けると、各ビンが細くなってビンごとの間隔が大きくなります。詳細は以下のサンプルコードのとおりです。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 50
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data = rng.standard_normal(num_data)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# rwidth引数でヒストグラムのビン(バー)の太さを変更できる
axes.hist(data, bins = num_bins, rwidth = 0.5)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# プロットを表示する
plt.show()
// 実行結果

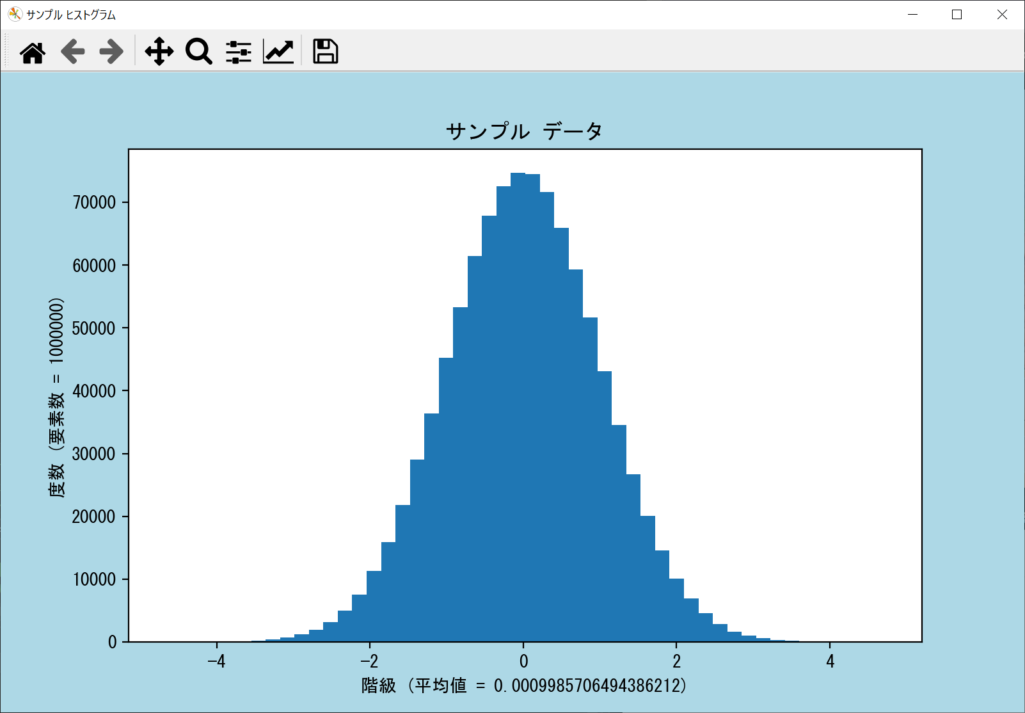
log引数|度数を対数スケールに変更する
ヒストグラムの度数を対数スケールに変更したい場合は、axes.hist()関数の「log引数」をTrueにしましょう。対数スケールのヒストグラムは、大きなデータの傾向を把握したいときに役立ちます。詳細は以下のサンプルコードのとおりです。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 1000000
num_bins = 50
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data = rng.standard_normal(num_data)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# log引数で度数を対数スケールで表示できる
axes.hist(data, bins = num_bins, log = True)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# プロットを表示する
plt.show()
// 実行結果
log = False
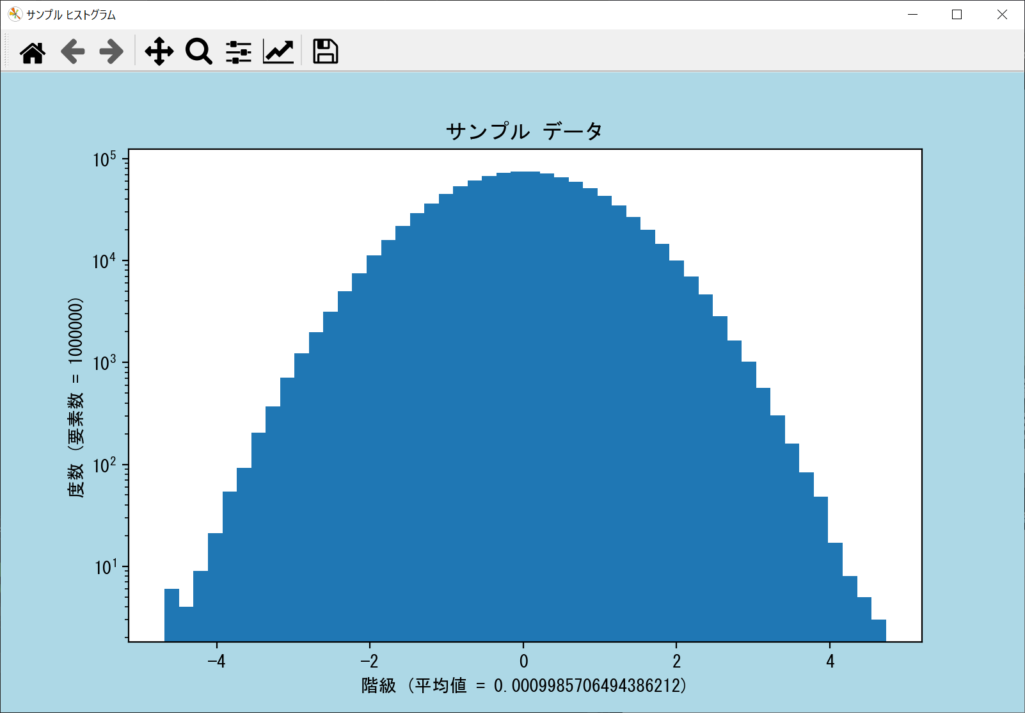
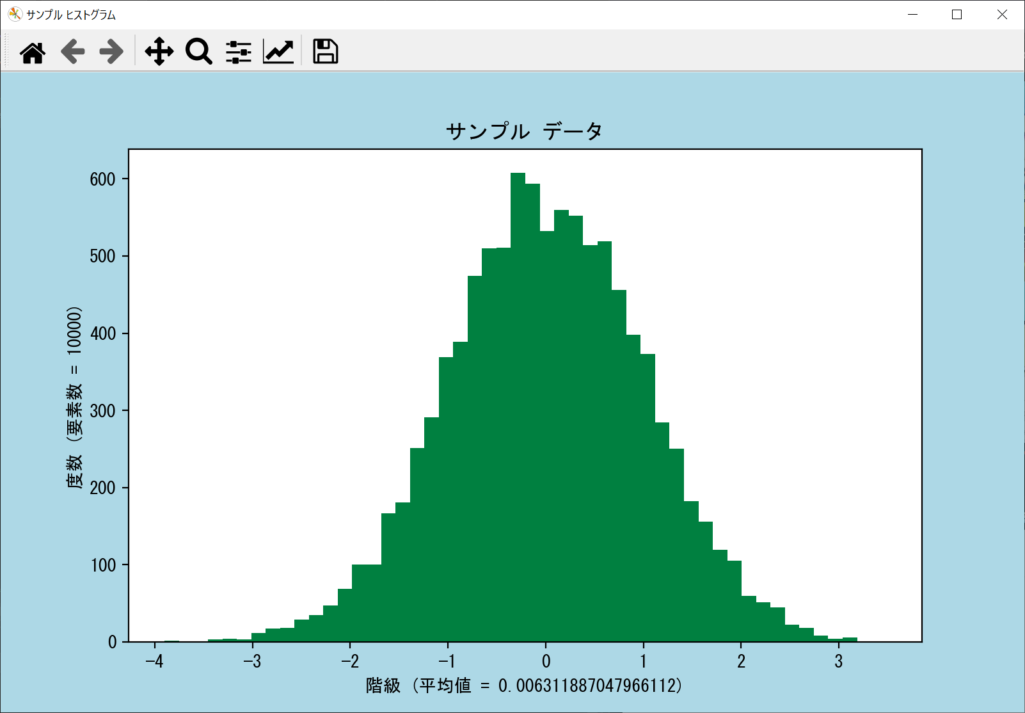
color引数|ビン(バー)の色を変更する
ヒストグラムのビン(バー)の色は、デフォルトで青になっています。これを変更したい場合は、axes.hist()関数の「color引数」を以下の値にすることで、自由なデザインが可能です。
| 値 | 色 |
|---|---|
| “b” | 青 |
| “k” | 黒 |
| “r” | 赤 |
| “g” | 緑 |
| “y” | 黄 |
| “w” | 白 |
| “c” | シアン |
| “m” | マゼンダ |
以上の値ではなく、「color = (0.0, 0.0, 1.0)」RGBの各要素を0.0~1.0の範囲で指定すると、より自由な色設定ができます。詳細は以下のサンプルコードのとおりです。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 50
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data = rng.standard_normal(num_data)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# color引数でビン(バー)の色を変更できる
axes.hist(data, bins = num_bins, color = (0.0, 0.5, 0.25))
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# プロットを表示する
plt.show()
// 実行結果
【応用編】ヒストグラムで複雑なデータを表示するための知識

- 複数のヒストグラムを描画する
- 複数のヒストグラムを横並びで表示する
- 各ヒストグラムを縦積みで表示する
- axes.hist()の戻り値を活用する
- 縦軸をパーセント表示にする
- 2次元のヒストグラムを表示する
- 複数のデータセットのヒストグラムを表示する
- 各ヒストグラムの凡例を表示する
複数のヒストグラムを描画する
複数のヒストグラムを1つのグラフに描画したいときは、単にaxes.hist()を複数回呼び出すだけでOKです。詳細を以下のサンプルコードで確認しましょう。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 50
# 2つのデータをわかりやすく表示するための差分値を定義する
base_1, sigma_1 = 50, 10
base_2, sigma_2 = 150, 30
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data_1 = base_1 + rng.standard_normal(num_data) * sigma_1
data_2 = base_2 + rng.standard_normal(num_data) * sigma_2
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# color引数でビン(バー)の色を変更できる
# このようにaxes.hist()を複数回呼び出すだけで、複数のヒストグラムを表示できる
axes.hist(data_1, bins = num_bins, color = (1.0, 0.0, 0.0))
axes.hist(data_2, bins = num_bins, color = (0.0, 0.0, 1.0))
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel("階級")
axes.set_ylabel("度数")
# プロットを表示する
plt.show()
// 実行結果
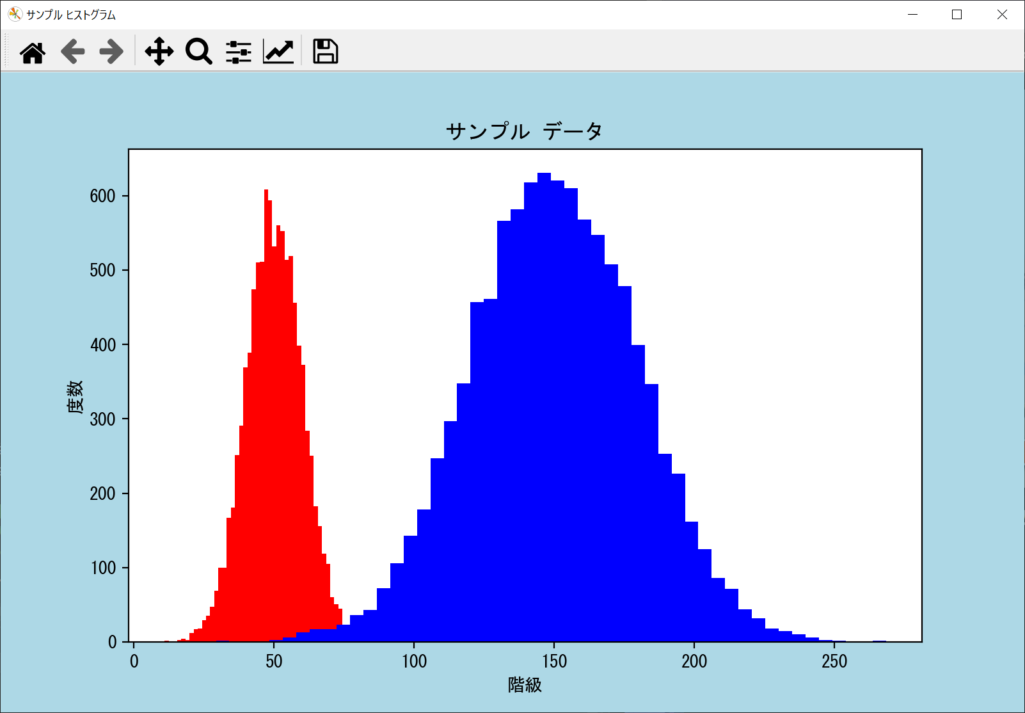
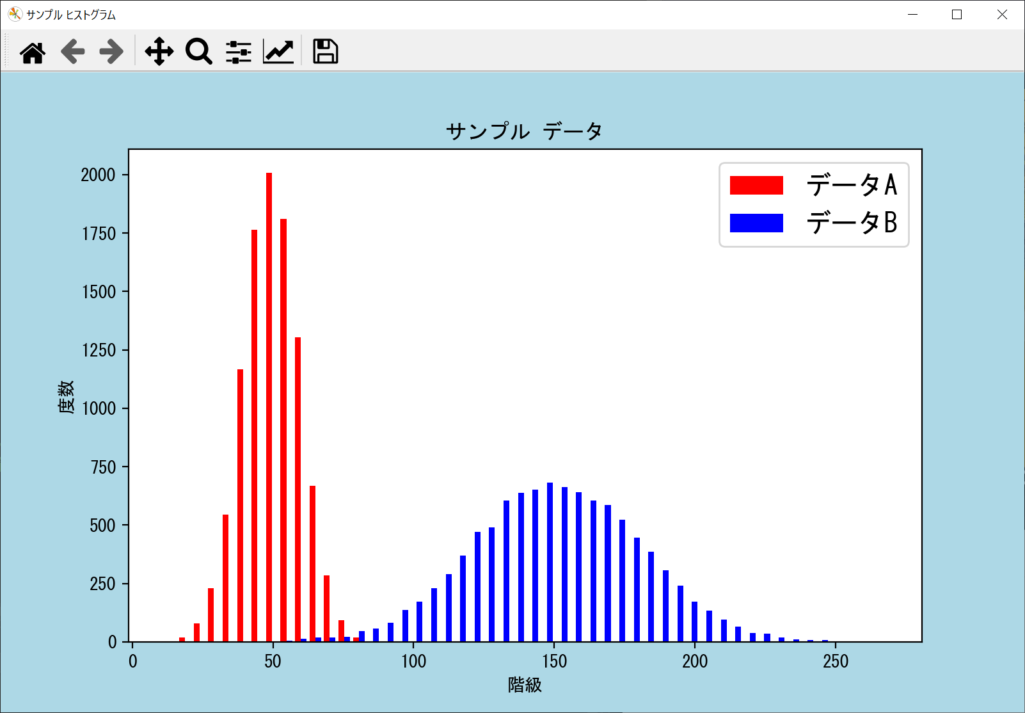
プログラム前半では、2つのグラフをわかりやすく表示するために、データリストの値を操作しています。それ以外はこれまでと同様、axes.hist()を複数回呼び出すだけで、ヒストグラムをいくつでも表示することが可能です。なお、ヒストグラム同士が重なって見づらくなる場合は、axes.hist()のalpha引数を利用して、値を1.0から0.0に近付けると半透明になります。
複数のヒストグラムを横並びで表示する
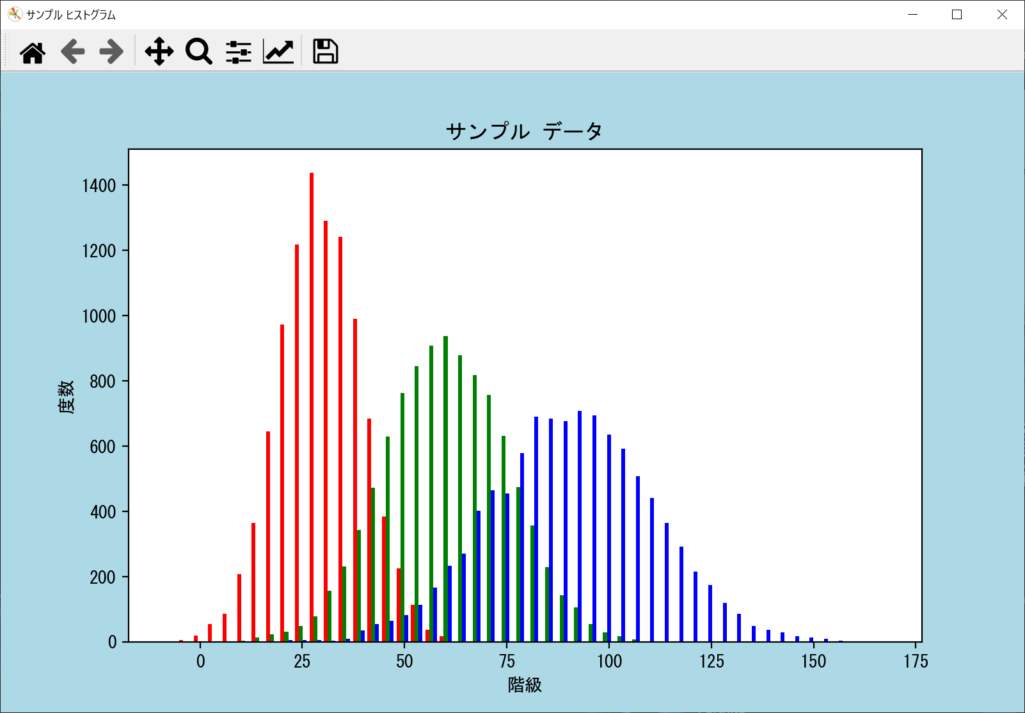
複数のヒストグラムを1つのグラフに表示するとき、グラフ同士が重なって値を比較しにくいことがあります。その場合は以下のように、axes.hist()を1回だけ呼び出し、リスト形式で複数のデータや色を並べることで、横並びでビン(バー)の表示が可能です。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 50
# 2つのデータをわかりやすく表示するための差分値を定義する
base_1, sigma_1 = 30, 10
base_2, sigma_2 = 60, 15
base_3, sigma_3 = 90, 20
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data_1 = base_1 + rng.standard_normal(num_data) * sigma_1
data_2 = base_2 + rng.standard_normal(num_data) * sigma_2
data_3 = base_3 + rng.standard_normal(num_data) * sigma_3
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# color引数でビン(バー)の色を変更できる
# このように複数のデータをリスト形式でまとめて指定することで、バーを横並びにできる
axes.hist([data_1, data_2, data_3], bins = num_bins, color = ["r", "g", "b"])
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel("階級")
axes.set_ylabel("度数")
# プロットを表示する
plt.show()
// 実行結果
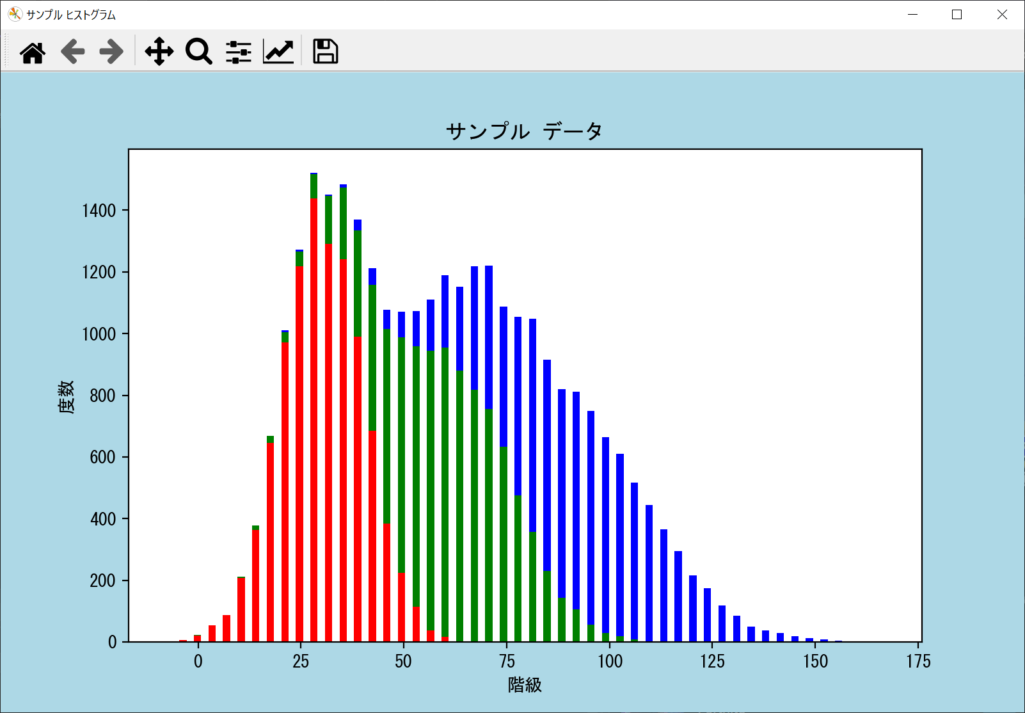
各ヒストグラムを縦積みで表示する
各階級ごとのデータの総量を把握したいときは、横並びではなく「縦積み」にするのが便利です。ヒストグラムを縦積み表示したい場合は、先ほどと同じようにリスト形式で並べて、axes.hist()の「stacked引数」をTrueにしましょう。詳細は以下のサンプルコードのとおりです。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 50
# 2つのデータをわかりやすく表示するための差分値を定義する
base_1, sigma_1 = 30, 10
base_2, sigma_2 = 60, 15
base_3, sigma_3 = 90, 20
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data_1 = base_1 + rng.standard_normal(num_data) * sigma_1
data_2 = base_2 + rng.standard_normal(num_data) * sigma_2
data_3 = base_3 + rng.standard_normal(num_data) * sigma_3
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# color引数でビン(バー)の色を変更できる
# 複数のデータをリスト形式で指定し、stackedをTrueにすることで縦積みができる
axes.hist([data_1, data_2, data_3], bins = num_bins, color = ["r", "g", "b"], stacked = True, rwidth = 0.5)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel("階級")
axes.set_ylabel("度数")
# プロットを表示する
plt.show()
// 実行結果
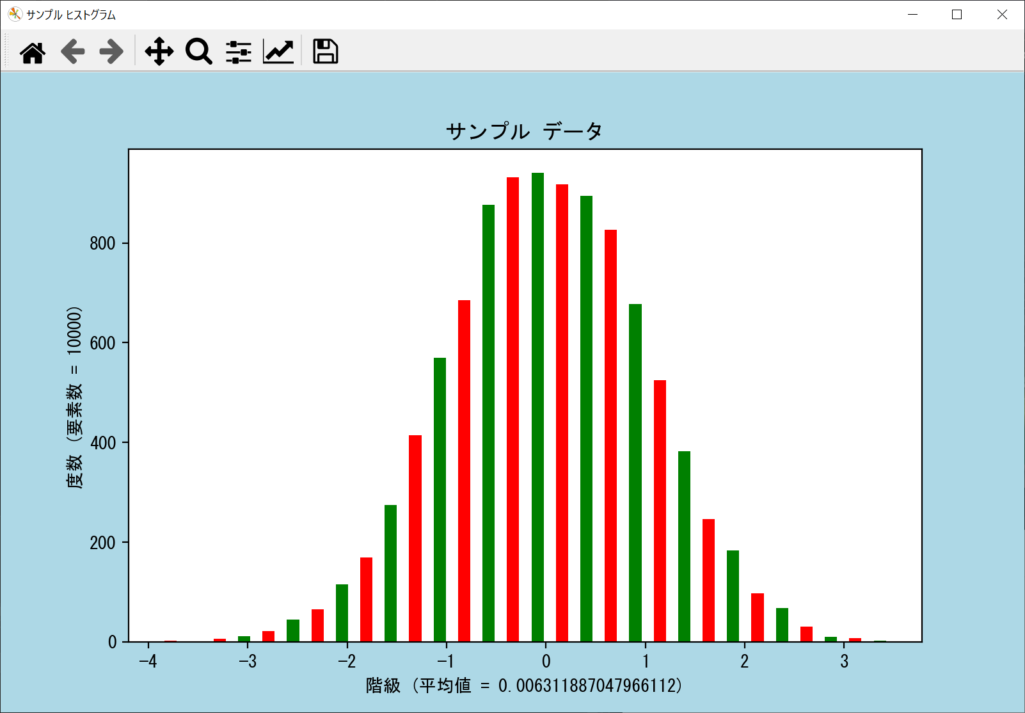
axes.hist()の戻り値を活用する
axes.hist()関数には、実は以下のように3つの戻り値があります。これらの値を活用することで、より便利なヒストグラムの作成・表示が可能です。
| 戻り値 | 概要 |
|---|---|
| N | 階級ごとの度数 |
| bins | 各階級の値 |
| patches | 描写用のmatplotlibオブジェクト |
いずれもリスト形式で、ビンごとの情報が格納されています。以下のサンプルコードのように、patches引数を利用することで、ビン(バー)の表示色をダイレクトに変更可能です。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 30
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data = rng.standard_normal(num_data)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# rwidth引数でヒストグラムのビン(バー)の太さを変更できる
# 戻り値として「N」「bins」「patches」の3つを受ける
N, bins, patches = axes.hist(data, bins = num_bins, rwidth = 0.5)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# forループを回して、偶数のビンを赤・奇数のビンを緑に変更する
for i in range(len(patches)):
# リストのインデックスによって処理内容を変える
if i % 2 == 0:
patches[i].set_facecolor("r")
else:
patches[i].set_facecolor("g")
# プロットを表示する
plt.show()
// 実行結果
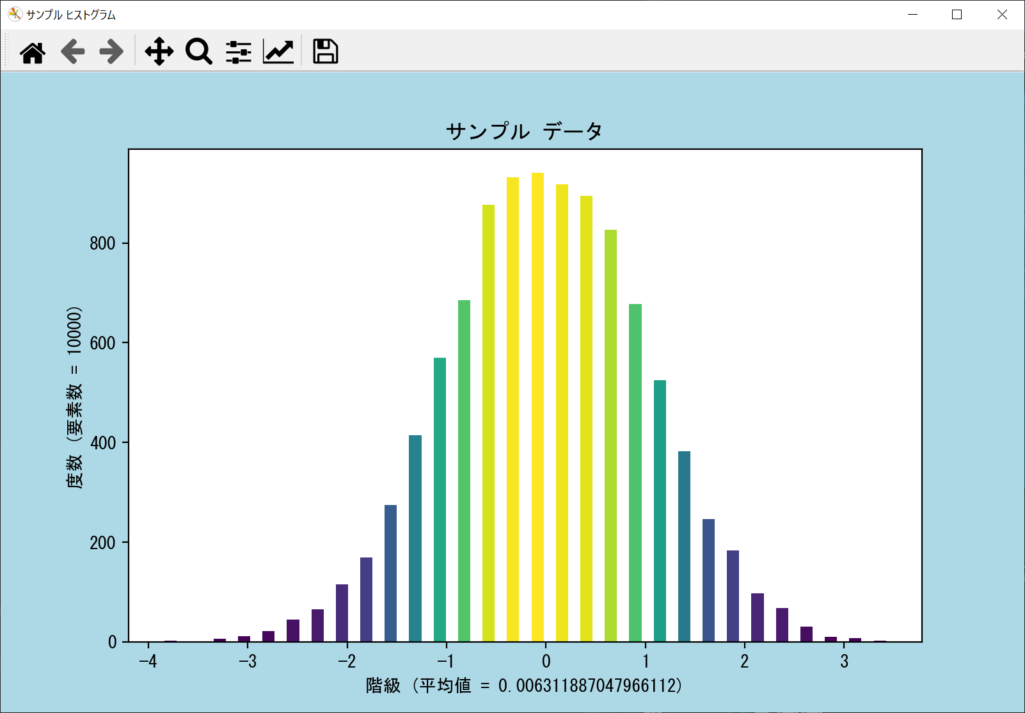
axes.hist()関数の戻り値を活用すれば、以下のようにビン(バー)の長さに応じて、自動的に色を変更するプログラムを作れます。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 30
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data = rng.standard_normal(num_data)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# rwidth引数でヒストグラムのビン(バー)の太さを変更できる
# 戻り値として「N」「bins」「patches」の3つを受ける
N, bins, patches = axes.hist(data, bins = num_bins, rwidth = 0.5)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# ビンの高さに応じて色分けを行う
colors = N / N.max()
# matplotlibのカラーマップの範囲で、先ほどの色データを0〜1に正規化する
normals = matplotlib.colors.Normalize(colors.min(), colors.max())
# colorsとpatchesのオブジェクトをループして、それぞれの色を設定する
for color, patch in zip(colors, patches):
color = plt.cm.viridis(normals(color))
patch.set_facecolor(color)
# プロットを表示する
plt.show()
// 実行結果
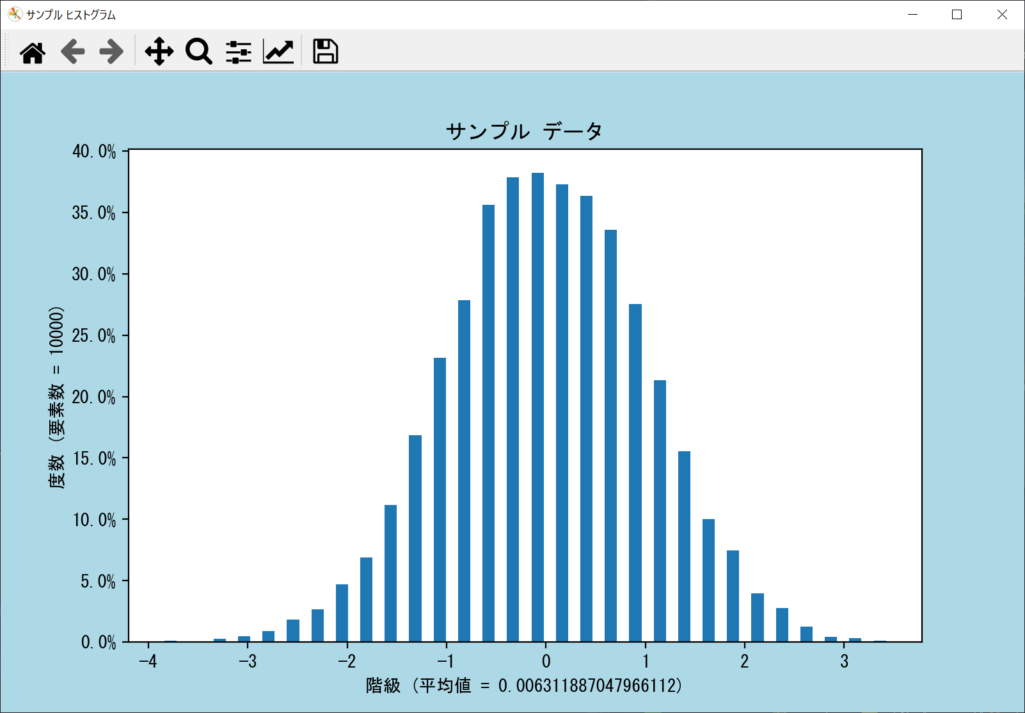
縦軸をパーセント表示にする
縦軸を度数からパーセント表記に変更も可能です。axes.hist()のdensity引数をTrueにしたうえで、axes.yaxis.set_major_formatter()を呼び出すことで、ヒストグラムの縦軸がパーセント表記になります。引数には「matplotlib.ticker.PercentFormatter(xmax = 1)」を指定しましょう。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 30
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data = rng.standard_normal(num_data)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# density引数をTrueにするとヒストグラムを正規化できる
# rwidth引数でヒストグラムのビン(バー)の太さを変更できる
axes.hist(data, bins = num_bins, density = True, rwidth = 0.5)
# Y軸をパーセンテージ表示するためにフォーマットを設定する
axes.yaxis.set_major_formatter(matplotlib.ticker.PercentFormatter(xmax = 1))
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# プロットを表示する
plt.show()
// 実行結果
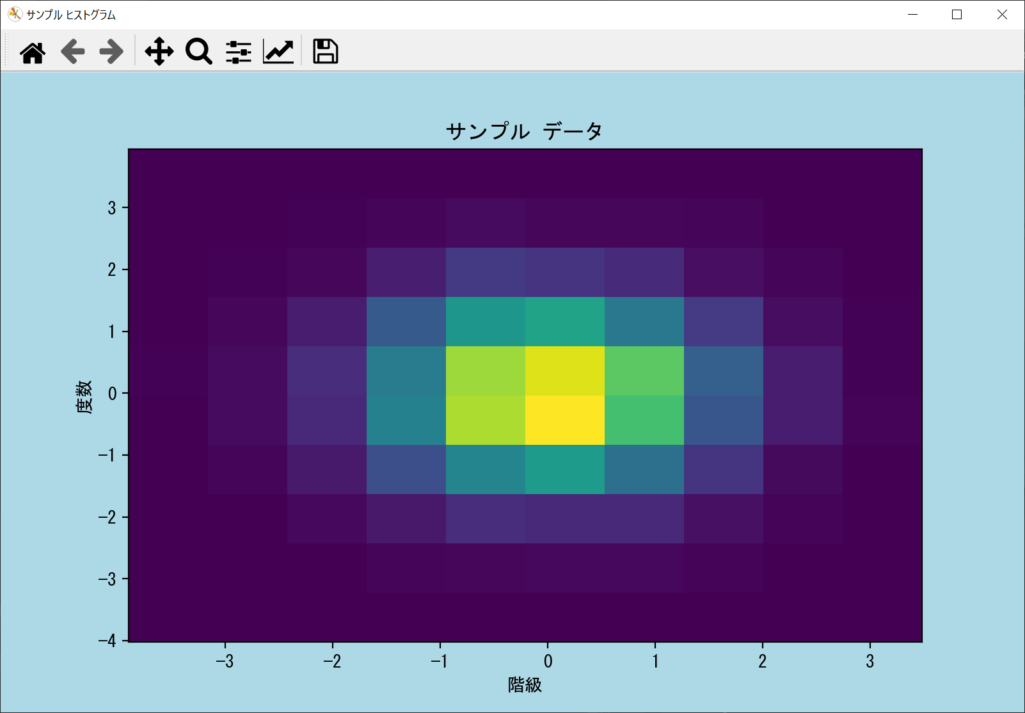
2次元のヒストグラムを表示する
これまでは1つのデータリストを使った1次元のヒストグラムでしたが、2つのデータリストで2次元のヒストグラムの表示も可能です。その場合は、axes.hist()ではなく「axes.hist2d()」を呼び出します。引数には、2つのデータリストを指定するだけでOKです。詳細を以下のサンプルコードで確認しましょう。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 30
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data_1 = rng.standard_normal(num_data)
data_2 = rng.standard_normal(num_data)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# 2次元のヒストグラムを作成・表示する
axes.hist2d(data_1, data_2)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級")
axes.set_ylabel(f"度数")
# プロットを表示する
plt.show()
// 実行結果
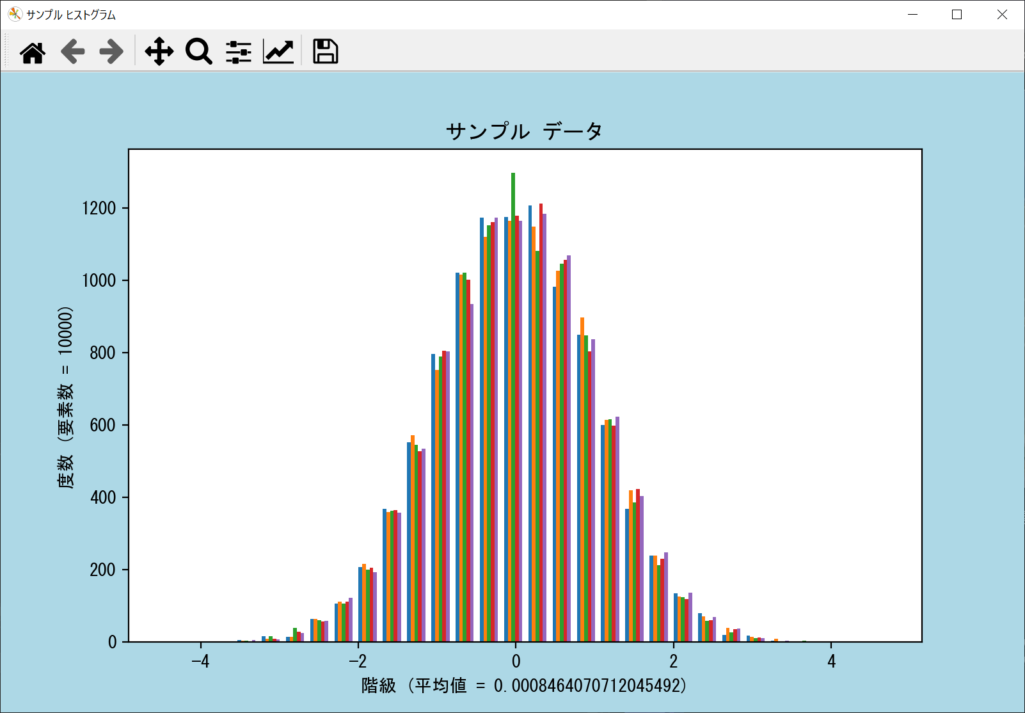
複数のデータセットのヒストグラムを表示する
複数のデータセットのヒストグラムを表示するときは、データを2次元リストで用意しておくと、axes.hist()を1回呼び出すだけで自動的に横並び・色分けが行われます。詳細は以下のサンプルコードのとおりです。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 30
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでnormal()を呼び出すことがポイント
# np.random.normal()よりも高速な乱数生成が行える
# 2次元リスト形式で5つのデータを生成する
data = rng.normal(size = (num_data, 5))
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# rwidth引数でヒストグラムのビン(バー)の太さを変更できる
axes.hist(data, bins = num_bins, rwidth = 0.75)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# プロットを表示する
plt.show()
// 実行結果
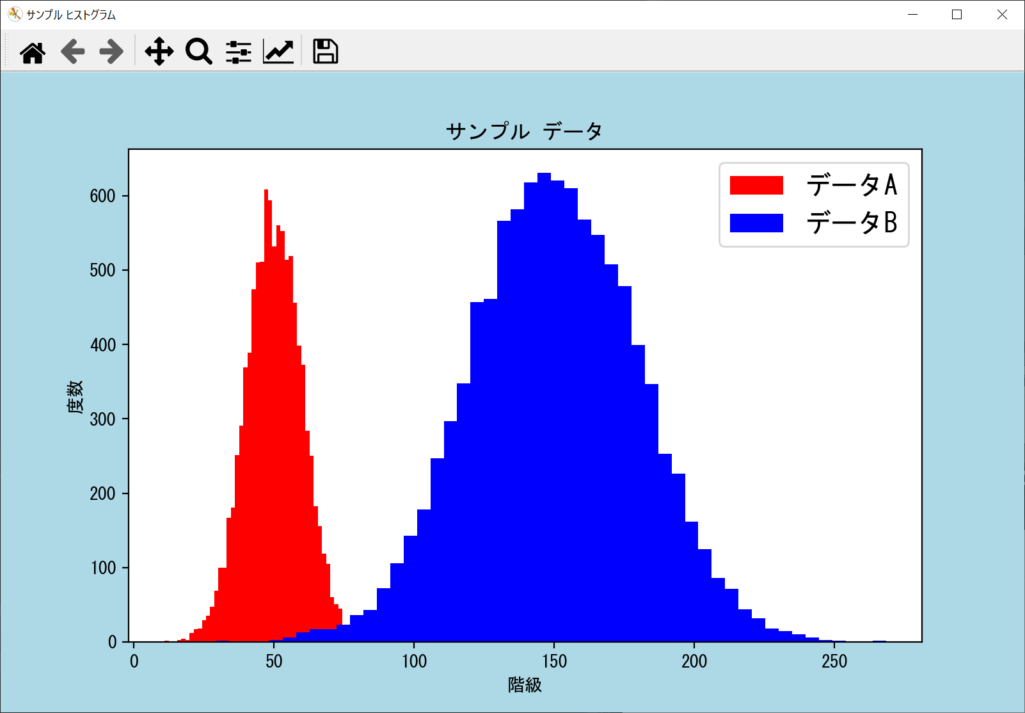
各ヒストグラムの凡例を表示する
複数のデータリストをヒストグラム化する場合は、「どのデータが何を示すか」を表示すると、よりわかりやすいヒストグラムになります。これを「凡例」と呼び、前述したようにaxes.hist()で「label引数」を指定したうえで、plt.legend()を呼び出せばOKです。詳細は以下のサンプルコードのとおりです。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 50
# 2つのデータをわかりやすく表示するための差分値を定義する
base_1, sigma_1 = 50, 10
base_2, sigma_2 = 150, 30
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data_1 = base_1 + rng.standard_normal(num_data) * sigma_1
data_2 = base_2 + rng.standard_normal(num_data) * sigma_2
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel("階級")
axes.set_ylabel("度数")
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# color引数でビン(バー)の色を変更できる
# このようにaxes.hist()を複数回呼び出すだけで、複数のヒストグラムを表示できる
# label引数で凡例のラベルを指定する
axes.hist(data_1, bins = num_bins, color = (1.0, 0.0, 0.0), label = "データA")
axes.hist(data_2, bins = num_bins, color = (0.0, 0.0, 1.0), label = "データB")
# 凡例をグラフ上に表示する
# fontsize引数で凡例の大きさを指定する
# loc引数で凡例の表示位置を指定する
plt.legend(fontsize = 15, loc = "upper right")
# プロットを表示する
plt.show()
// 実行結果
plt.legend()の引数にはさまざまな種類がありますが、基本的には「fontsize」と「loc」の2つを指定しておけば問題ありません。「loc引数」は、以下の11種類から選びます。
- "best"
- "right"
- "center"
- "upper left"
- "upper right"
- "upper center"
- "lower left"
- "lower right"
- "lower center"
- "center left"
- "center right"
グラフを横並びで表示したい場合は、axes.hist()でリスト形式でまとめて記載しましょう。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 50
# 2つのデータをわかりやすく表示するための差分値を定義する
base_1, sigma_1 = 50, 10
base_2, sigma_2 = 150, 30
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
data_1 = base_1 + rng.standard_normal(num_data) * sigma_1
data_2 = base_2 + rng.standard_normal(num_data) * sigma_2
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel("階級")
axes.set_ylabel("度数")
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# color引数でビン(バー)の色を変更できる
# label引数で凡例のラベルを指定する
axes.hist(x = [data_1, data_2], bins = num_bins, color = [(1.0, 0.0, 0.0), (0.0, 0.0, 1.0)], label = ["データA", "データB"])
# 凡例をグラフ上に表示する
# fontsize引数で凡例の大きさを指定する
# loc引数で凡例の表示位置を指定する
plt.legend(fontsize = 15, loc = "upper right")
# プロットを表示する
plt.show()
// 実行結果
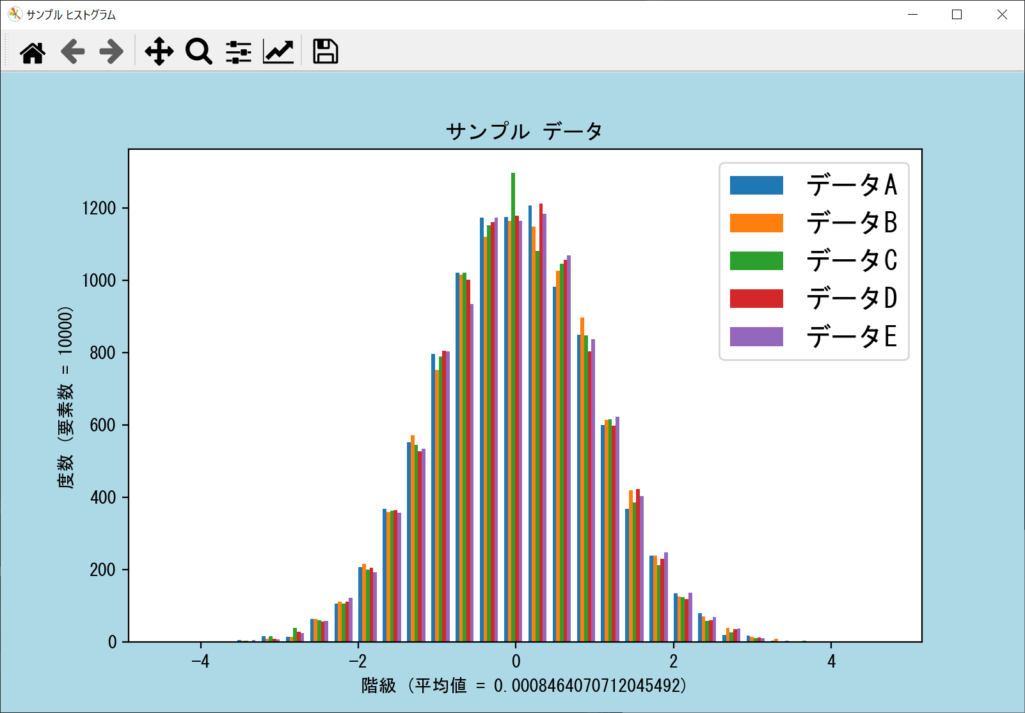
複数のデータセットを2次元リストで作成する場合は、以下のようにaxes.hist()のlabel引数だけリスト形式にすれば、以下のように凡例を表示できます。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 30
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでnormal()を呼び出すことがポイント
# np.random.normal()よりも高速な乱数生成が行える
# 2次元リスト形式で5つのデータを生成する
data = rng.normal(size = (num_data, 5))
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# rwidth引数でヒストグラムのビン(バー)の太さを変更できる
# label引数で凡例のラベルをリスト形式で指定すれば、複数のデータセットにも対応可能
axes.hist(data, bins = num_bins, rwidth = 0.75, label = ["データA", "データB", "データC", "データD", "データE"])
# 凡例をグラフ上に表示する
# fontsize引数で凡例の大きさを指定する
# loc引数で凡例の表示位置を指定する
plt.legend(fontsize = 15, loc = "upper right")
# プロットを表示する
plt.show()
// 実行結果
【実践編】ヒストグラムでデータを活用するためのテクニック

ヒストグラムでデータを活用するためのテクニックとして、以下の3つをご紹介します。それぞれ詳しく見ていきましょう。
- 複数のプロット(グラフ画面)を表示する
- CSVファイルのデータでヒストグラムを作成する
- ヒストグラムをファイルに保存する
複数のプロット(グラフ画面)を表示する
これまでは1つのプロット(グラフ画面)に、1つもしくは複数のヒストグラムを表示していました。Matplotlibでは、必要な回数だけfigure.add_subplot()関数を呼び出し、複数のプロットを作成できます。ただし、前述したように引数で「行数」「列数」「プロット番号」を指定することが重要です。詳細は以下のサンプルコードのとおりとなります。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
# tight_layout引数:レイアウトの自動調整
figure = plt.figure(num = "サンプルヒストグラム", figsize = (12, 6), facecolor = "lightblue", tight_layout = True)
# プロットの行(row)と列(column)を指定する
row = 2
column = 3
# データやプロットを複数格納するためのリストを用意する
data = []
axes = []
# 必要なデータとプロットを生成する
for i in range(row * column):
# データを生成するための定数を定義する
num_data = 1000
num_bins = 20
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでstandard_normal()を呼び出すことがポイント
# np.random.randn()よりも高速な乱数生成が行える
count = i + 1
data.append((count * 10) + rng.standard_normal((num_data, 3)) * (count * 10))
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは複数なので、最初の2つの引数はプロットの行と列、最後の引数はプロット番号を指定する
axes.append(figure.add_subplot(row, column, count))
# すべてのヒストグラムの作成と表示を行う
for i in range(row * column):
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes[i].set_title("サンプルデータ" + str(i + 1))
axes[i].set_xlabel(f"階級 (平均値 = {np.average(data[i])})")
axes[i].set_ylabel(f"度数 (要素数 = {len(data[i])})")
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# rwidth引数でヒストグラムのビン(バー)の太さを変更できる
# label引数で凡例のラベルをリスト形式で指定すれば、複数のデータセットにも対応可能
axes[i].hist(data[i], bins = num_bins, rwidth = 0.75, label = ["データA", "データB", "データC"])
# 凡例をグラフ上に表示する
# fontsize引数で凡例の大きさを指定する
# loc引数で凡例の表示位置を指定する
axes[i].legend(fontsize = 8, loc = "upper right")
# プロットを表示する
plt.show()
// 実行結果
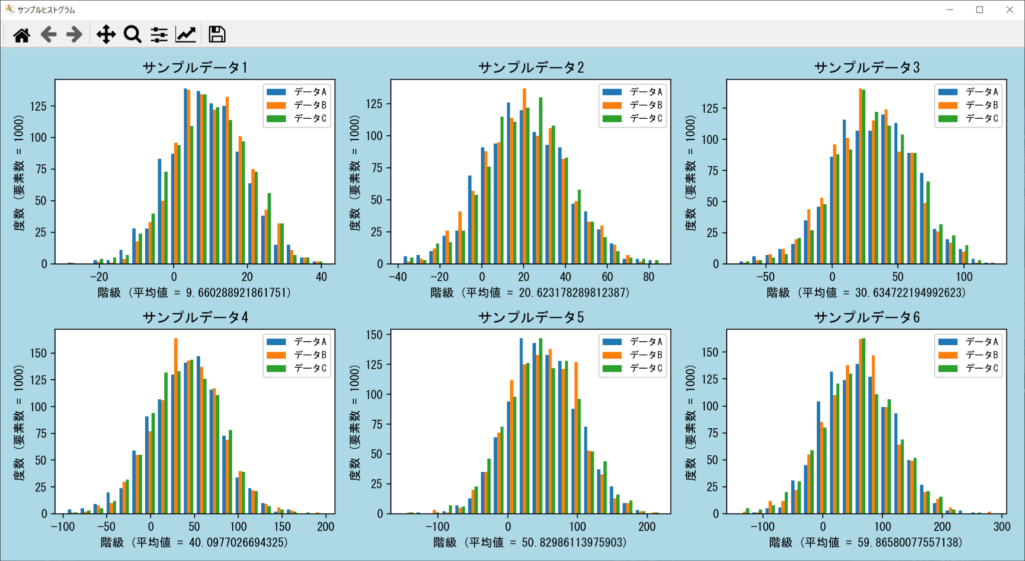
重要なポイントは、描画したいプロットの数だけfigure.add_subplot()を呼び出し、プロットごとに凡例を指定していることです。各プロットにはそれぞれ複数のデータセットを用意して、axes[i].hist()関数でlabelをまとめて設定しています。このように、データごとに複数のプロットを表示できると便利なので、ぜひ覚えておきましょう。
CSVファイルのデータでヒストグラムを作成する
これまではプログラム内でデータを作成し、そのままヒストグラムを作成していました。しかし、実際にヒストグラムでデータを可視化・分析する際は、既存ファイルからデータを読み込むことが多いです。そこで今回は、コンマ区切りで記載する「CSVファイル」から、データ取得とヒストグラム生成を行うサンプルコードを紹介します。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 「CSV」ライブラリをimportする
import csv
# write()関数|データをCSVファイルに書き出す
def write(filename, data):
np.savetxt(fname = filename, X = data, delimiter = ",", fmt = "%f")
# read()関数|データをCSVファイルから読み込む
def read(filename):
return np.loadtxt(fname = filename, delimiter = ",", dtype = "float")
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 30
num_rows = 5
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでnormal()を呼び出すことがポイント
# np.random.normal()よりも高速な乱数生成が行える
# 2次元リスト形式で5つのデータを生成する
data = rng.normal(size = (num_data, num_rows))
# CSVのファイル名を指定する
filename = "SampleData.csv"
# 生成したデータをCSVファイルとして書き出す
write(filename, data)
# CSVファイルからデータを読み込む
data = read(filename)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# rwidth引数でヒストグラムのビン(バー)の太さを変更できる
# label引数で凡例のラベルをリスト形式で指定すれば、複数のデータセットにも対応可能
axes.hist(data, bins = num_bins, rwidth = 0.75, label = ["データA", "データB", "データC", "データD", "データE"])
# 凡例をグラフ上に表示する
# fontsize引数で凡例の大きさを指定する
# loc引数で凡例の表示位置を指定する
plt.legend(fontsize = 15, loc = "upper right")
# プロットを表示する
plt.show()
// 実行結果
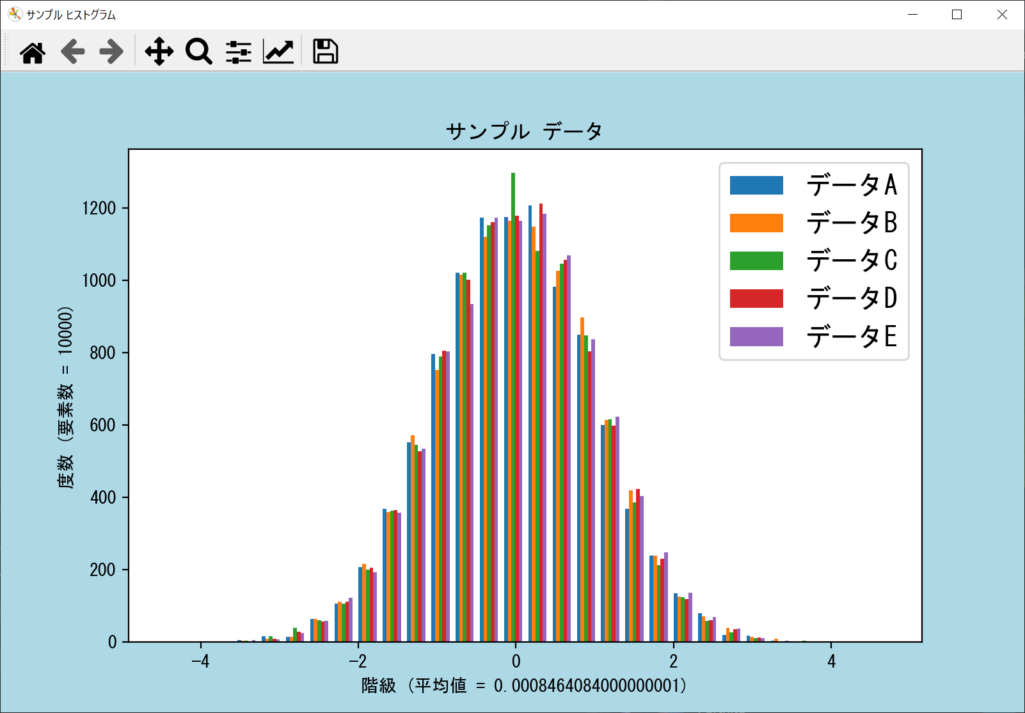
重要なポイントは、独自作成の「write()」と「read()」です。内部ではNumPyの「np.savetxt()」と「np.loadtxt()」を使って、CSVファイルの読み書きをシンプルに行っています。
いずれも「fname引数」でファイル名、「delimiter引数」で区切り文字を指定します。デフォルトの区切り文字は半角スペースなので、CSVファイルを使用する場合は必ずコンマの指定が必要です。np.savetxt()は「fmt = "%f"」・np.loadtxt()は「dtype = "float"」で、浮動小数点値を扱えます。
戻り値はNumPyのリスト形式となり、Matplotlibの各関数でそのまま使用可能です。上記のサンプルプログラムは、さまざまなCSVファイルのデータ可視化に役立つので、ぜひ参考にしてみてください。
ヒストグラムをファイルに保存する
Matplotlibには、作成したヒストグラムをファイル出力するための機能も備わっています。以下の構文で「pyplot.savefig()関数」を呼び出すと、さまざまな形式でヒストグラムのデータを保存が可能です。
plt.savefig("ファイル名", format = "ファイル形式", dpi = 解像度)
「format引数」ではファイルの拡張子として、以下の13種類から選べます。目的や活用法に応じて適切なものを選びましょう。
- emf
- eps
- jpeg
- jpg
- png
- ps
- raw
- rgba
- svg
- svgz
- tif
- tiff
「dpi引数」は画像の解像度を示し、300前後を指定しておけば、高画質で見やすいヒストグラムデータを出力できます。pyplot.savefig()の使い方について、以下のサンプルコードで確認しましょう。
// サンプルプログラム
# coding: UTF-8
# 「matplotlib」ライブラリをimportする
import matplotlib
# 「matplotlib.pyplot」ライブラリをimportする
# ソースコードを簡潔にするため、「plt」というエイリアスを付ける
import matplotlib.pyplot as plt
# 「numpy」ライブラリをimportする
# ソースコードを簡潔にするため、「np」というエイリアスを付ける
import numpy as np
# 「csv」ライブラリをimportする
import csv
# write()関数|データをCSVファイルに書き出す
def write(filename, data):
np.savetxt(fname = filename, X = data, delimiter = ",", fmt = "%f")
# read()関数|データをCSVファイルから読み込む
def read(filename):
return np.loadtxt(fname = filename, delimiter = ",", dtype = "float")
# 日本語を表示するために「MS Gothic」フォントを使用する
plt.rcParams["font.family"] = "MS Gothic"
# 再現性のある乱数発生器を生成する
# 適当な値の引数を渡すことで、常に同じ乱数が生成されるようになる
rng = np.random.default_rng(0)
# データを生成するための定数を定義する
num_data = 10000
num_bins = 30
num_rows = 5
# 平均値0・標準偏差1の正規分布から乱数リストを生成する
# 乱数発生器を生成したうえでnormal()を呼び出すことがポイント
# np.random.normal()よりも高速な乱数生成が行える
# 2次元リスト形式で5つのデータを生成する
data = rng.normal(size = (num_data, num_rows))
# CSVのファイル名を指定する
filename = "SampleData.csv"
# 生成したデータをCSVファイルとして書き出す
write(filename, data)
# CSVファイルからデータを読み込む
data = read(filename)
# 描画領域となるFigureオブジェクトを作成する
# num引数:ウィンドウのタイトル
# figsize引数:ウィンドウのサイズ
# facecolor引数:ウィンドウの背景色
figure = plt.figure(num = "サンプル ヒストグラム", figsize = (8, 5), facecolor = "lightblue")
# プロットを描画するためのAxesオブジェクトを追加する
# 描画するプロットは1つなので、引数は「111」でOK
axes = figure.add_subplot(111)
# プロットのタイトルとX軸・Y軸のラベルを設定する
# Matplotlibはシングルバイト文字しか扱えないため、日本語は表示できない
# しかし、冒頭でplt.rcParams["font.family"]を設定しているため、日本語を表示できる
axes.set_title("サンプル データ")
axes.set_xlabel(f"階級 (平均値 = {np.average(data)})")
axes.set_ylabel(f"度数 (要素数 = {len(data)})")
# データを基にしてヒストグラムを作成する
# bins引数でヒストグラムの階級数(分割数)を指定する
# rwidth引数でヒストグラムのビン(バー)の太さを変更できる
# label引数で凡例のラベルをリスト形式で指定すれば、複数のデータセットにも対応可能
axes.hist(data, bins = num_bins, rwidth = 0.75, label = ["データA", "データB", "データC", "データD", "データE"])
# 凡例をグラフ上に表示する
# fontsize引数で凡例の大きさを指定する
# loc引数で凡例の表示位置を指定する
plt.legend(fontsize = 15, loc = "upper right")
# 作成したプロットを保存する
plt.savefig("SampleHistogram.png", format = "png", dpi = 300)
# プロットを表示する
plt.show()
// 実行結果
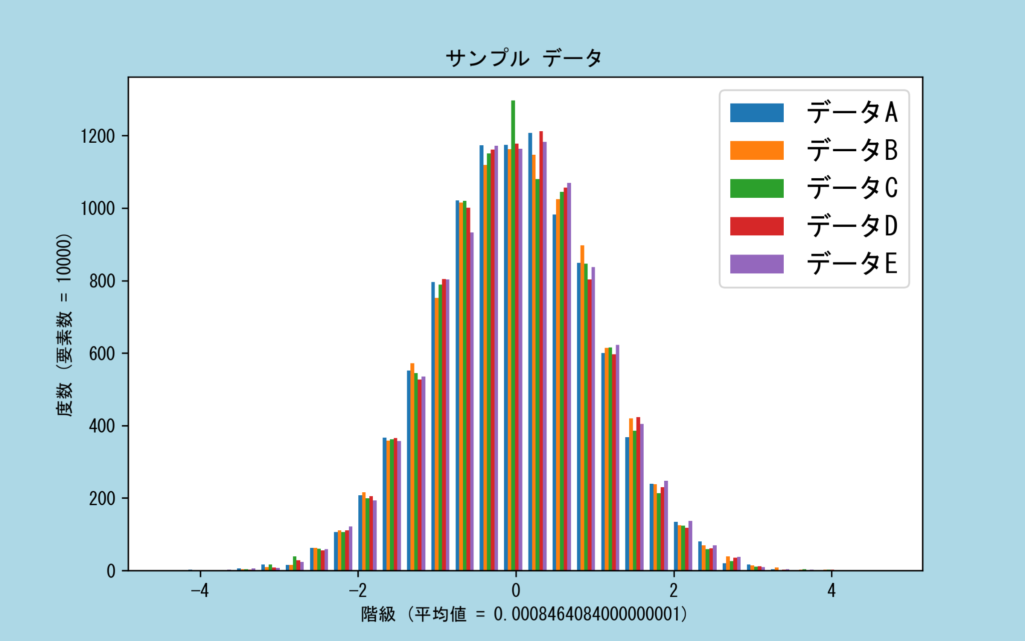
このサンプルプログラムでは、CSVファイルからデータを読み込んでヒストグラムを作成したあとに、PNGファイルへの書き出しを行っています。ファイル出力を行うことで、データの可視化と利活用がしやすくなるので、ぜひ活用してみてください。
PythonのMatplotlibでデータをヒストグラム化しよう

PythonのMatplotlibを活用することで、さまざまなデータをわかりやすい形で可視化できます。今回ご紹介したように、データさえ用意すれば、関数を呼び出すだけであらゆる種類のグラフを描画できます。作成したグラフはPDFや画像として出力できるので、データの可視化と利活用に便利です。この機会にぜひ、Matplotlibを活用してみてください。











アクセスランキング 人気のある記事をピックアップ!
コードカキタイがオススメする記事!

2024.06.17
子供におすすめのプログラミングスクール10選!学習メリットや教室選びのコツも紹介
#プログラミングスクール

2022.01.06
【完全版】大学生におすすめのプログラミングスクール13選!選ぶコツも詳しく解説
#プログラミングスクール

2024.01.26
【未経験でも転職可】30代におすすめプログラミングスクール8選!
#プログラミングスクール

2024.01.26
初心者必見!独学のJava学習方法とおすすめ本、アプリを詳しく解説
#JAVA

2024.01.26
忙しい社会人におすすめプログラミングスクール15選!失敗しない選び方も詳しく解説
#プログラミングスクール

2022.01.06
【無料あり】大阪のおすすめプログラミングスクール14選!スクール選びのコツも紹介
#プログラミングスクール

2024.01.26
【目的別】東京のおすすめプログラミングスクール20選!スクール選びのコツも徹底解説
#プログラミングスクール

2024.01.26
【無料あり】福岡のおすすめプログラミングスクール13選!選び方も詳しく解説
#プログラミングスクール

2024.01.26
【徹底比較】名古屋のおすすめプログラミングスクール13選!選び方も詳しく解説
#プログラミングスクール

2024.01.26
【徹底比較】おすすめのプログラミングスクール18選!失敗しない選び方も徹底解説
#プログラミングスクール