
Pythonでは、「正規表現」を使った複雑な文字列の検出・抽出ができます。正規表現とは、文字列の形式を指定するための機能です。正規表現が使えるようになると、今までより格段に文字列を操作しやすくなります。
しかし、正規表現は通常の文字列とは異なる特殊な構文を使用するため、「わかりにくい」「難しい」と苦手意識を感じてしまう人は多いです。そこで今回は、Pythonの正規表現の使い方や応用テクニックについて、サンプルコード付きでわかりやすく解説します。
目次
Pythonの正規表現とは?

Pythonの「正規表現」は、文字列の集まりを記号で表現するための記述方法です。正規表現を使うと、指定したパターンに当てはまる文字列の検索や置換ができるようになります。たとえば、ある文字列から「郵便番号」のみを抽出したい場合の正規表現は、以下のとおりです。
以上の記述は、「0~9までの数字3桁」「ハイフン」「0~9までの数字4桁」というパターンで構成された文字列を示します。この正規表現を使って、Pythonで文字列から郵便番号を抽出するソースコードは次のとおりです。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = "テスト太郎 〒123-4567 東京都新宿区"
# 検索したい文字列のパターンを正規表現で指定する
pattern = "[0-9]{3}-[0-9]{4}"
# search関数で文字列を検索する
result = re.search(pattern, string)
# 検索結果を表示する
print(result.group())
//実行結果
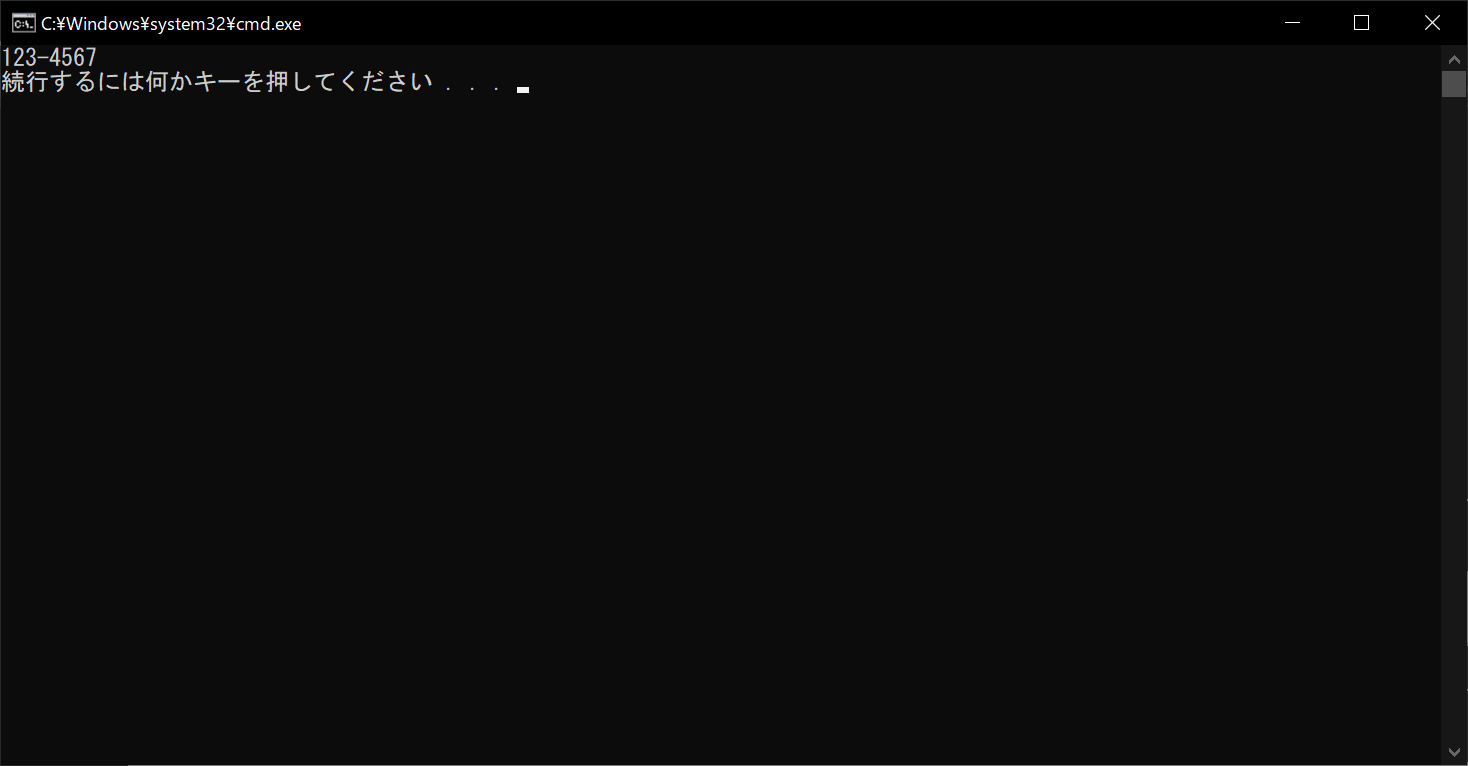
このように、文字列から郵便番号のみを抽出できました。正規表現を活用すると、非常に短いソースコードで、複雑なパターンの文字列の検索・抽出・置換などが簡単にできるようになります。
Pythonで正規表現を扱うためには「reモジュール」が必要
Pythonで正規表現を扱う際は、「reモジュール」が必要です。reモジュールは、Pythonで正規表現によって文字列を操作するための、さまざまな機能が網羅されたライブラリです。reモジュールは標準ライブラリなので、以下のようにimport文を記載するだけで使えます。外部モジュールのインストールなどの環境を構築する必要はありません。
【基本】Pythonの正規表現で文字列を抽出・検索・置換する方法

Pythonの正規表現で文字列を抽出・検索・置換するためには、reモジュールの関数を使いこなす必要があります。その関数の種類は主に以下6つで、それぞれ処理内容が異なるため、目的に合う関数を選ぶことが重要です。
| 関数 | 概要 |
| match | 先頭からパターンに一致する文字列を抽出する 先頭部分が一致しない場合は抽出できない |
| search | 全体の中で一致する最初の文字列を抽出する 複数マッチしても最初の文字列だけを返す |
| findall | 全体の中で一致するすべての文字列を抽出する マッチした文字列の位置情報は取得できない |
| finditer | 全体の中で一致するすべての文字列を抽出する マッチした文字列の位置情報も取得できる |
| fullmatch | 文字列全体がパターンと一致しているか確認する ひとつでも異なる部分がある場合は不一致となる |
| sub | パターンに一致した文字列を別の文字列に置換する 一致するすべての文字列が置換される |
上記の関数で抽出した文字列は、「matchオブジェクト」という形式で返ります。matchオブジェクトは、以下のような関数でさまざまな情報を取得できます。先ほどの例では、group関数でマッチした文字列を表示しました。
| 関数 | 概要 |
| group | マッチした文字列を取得する |
| span | マッチした文字列の開始・終了位置を取得する |
| start | マッチした文字列の開始位置を取得する |
| end | マッチした文字列の終了位置を取得する |
以上の点を踏まえて、各メソッドの使い方をサンプルコードで確認していきましょう。
match|先頭からパターンに一致する文字列を抽出する
「match」は、先頭からパターンに一致する文字列を抽出するための関数で、構文は以下のとおりです。
match関数の注意点は、文字列の先頭から検索することです。文字列の途中から一致するものが出現する場合は、不一致となります。match関数は以下のサンプルコードのように使います。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = "123-4567 東京都新宿区 テスト太郎"
# 検索したい文字列のパターンを正規表現で指定する
pattern = "[0-9]{3}-[0-9]{4}"
# match関数で文字列を検索する
result = re.match(pattern, string)
# 検索対象の文字列を表示する
print(string)
# 検索結果を表示する
print(result)
//実行結果
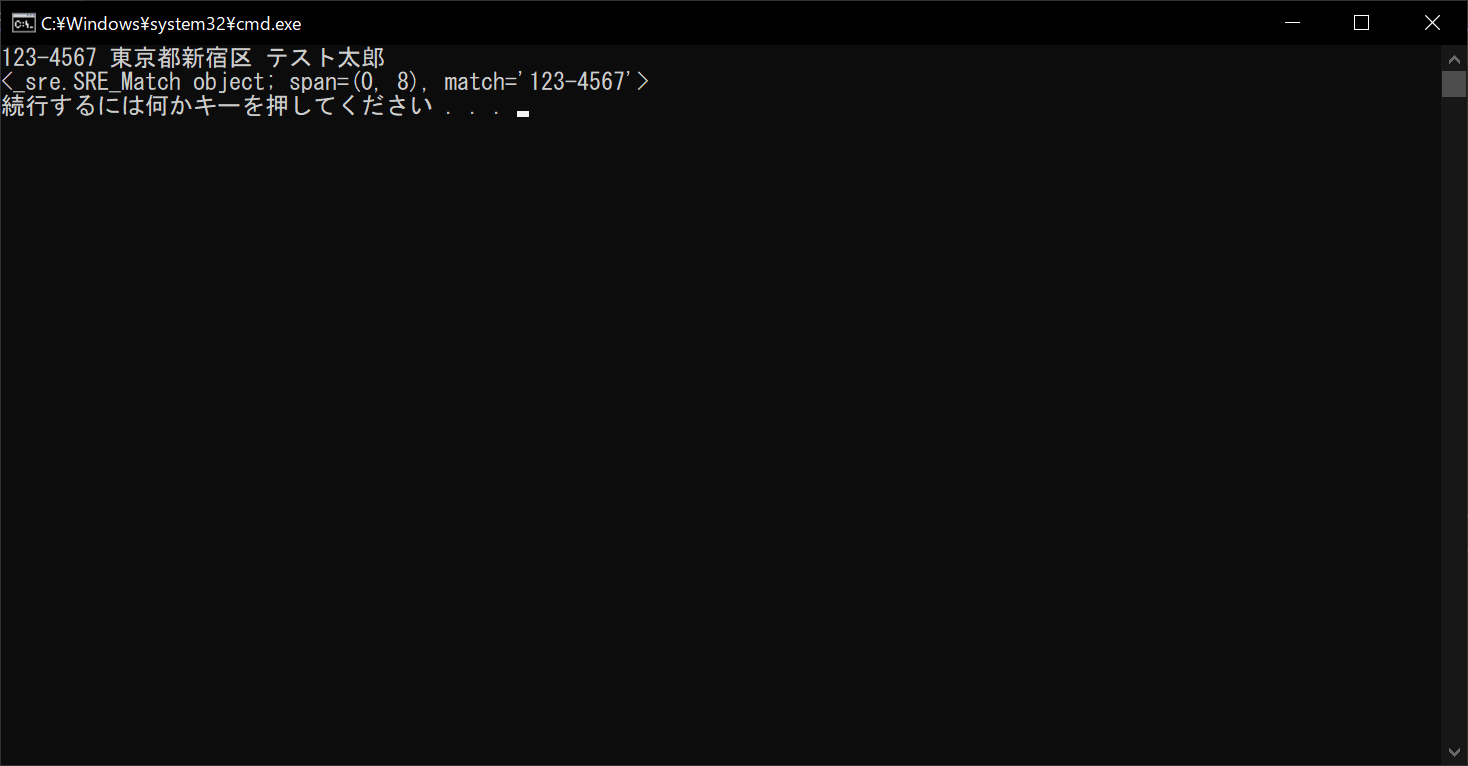
検索結果の表示内容がわかりにくいかもしれませんが、「span」の中身は抽出した部分の位置を「開始位置, 終了位置 – 1」という形式で表示しています。つまりこの場合は、文字列の0番目から7番目までが、正規表現で指定した文字列に該当するということです。最後の「match」は、実際に抽出した文字列を表し、この場合は「123-4567」となります。
なお、match関数は前述したとおり文字列の先頭からしか判定しないので、最初にパターンと異なるものがある場合は検出されません。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = "〒123-4567 東京都新宿区 テスト太郎"
# 検索したい文字列のパターンを正規表現で指定する
pattern = "[0-9]{3}-[0-9]{4}"
# match関数で文字列を検索する
result = re.match(pattern, string)
# 検索対象の文字列を表示する
print(string)
# 検索結果を表示する
print(result)
//実行結果
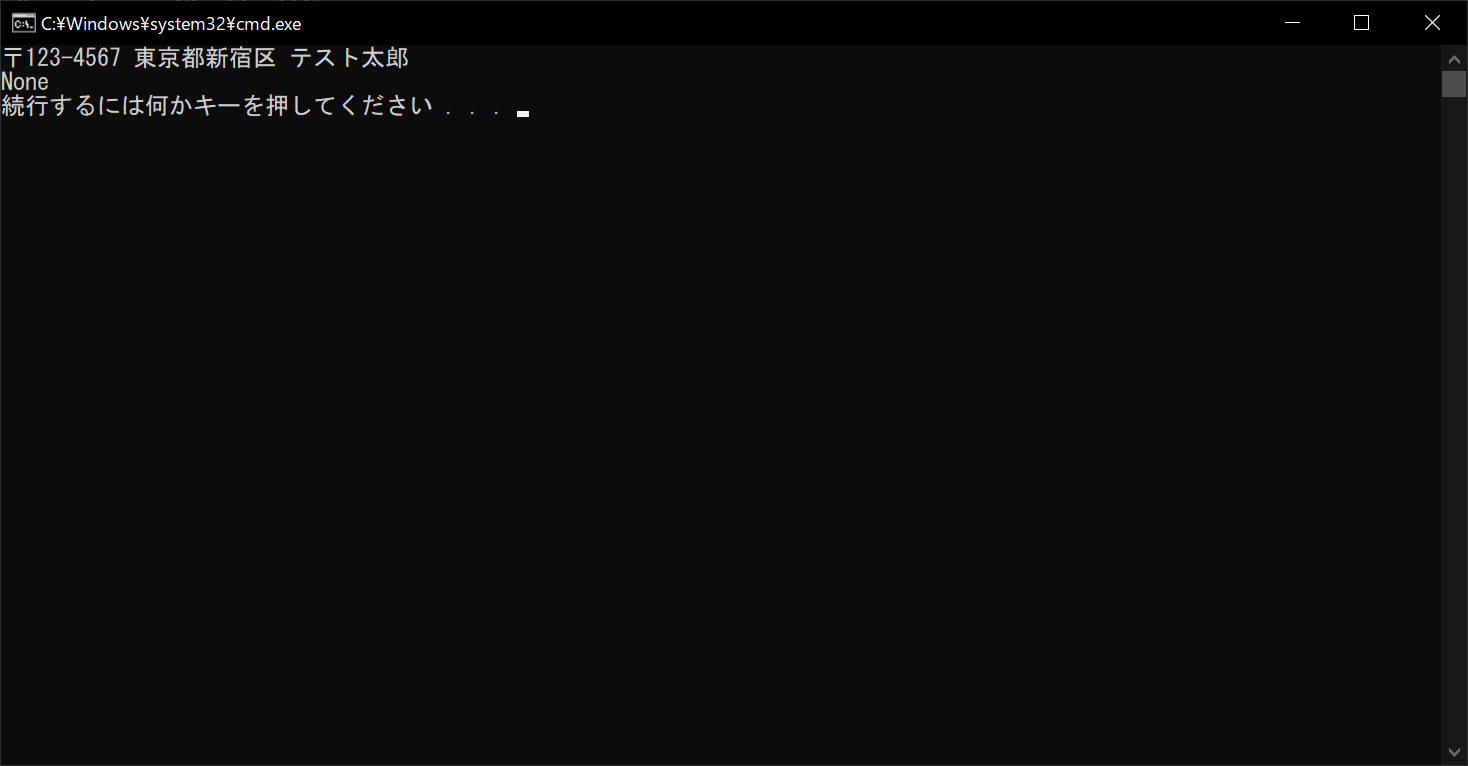
以上のように、検索・抽出したい文字列のパターンに該当するものがない場合は、結果として「None」が返ります。なお、NoneのMatchオブジェクトに対して、「group」や「span」などの関数を使用すると、エラーとなるので注意が必要です。
search|全体の中で一致する最初の文字列を抽出する
「search」は、全体の中で一致する最初の文字列を抽出するための関数で、構文は以下のとおりです。
引数の種類や並びは、先ほどのmatch関数と同じです。search関数の注意点は、文字列の中に一致する部分が複数ある場合でも、最初のものしか検出されないことです。search関数の使い方を、以下のサンプルコードで確認しましょう。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = "東京都新宿区 〒123-4567 テスト太郎 123-4567"
# 検索したい文字列のパターンを正規表現で指定する
pattern = "[0-9]{3}-[0-9]{4}"
# search関数で文字列を検索する
result = re.search(pattern, string)
# 検索対象の文字列を表示する
print(string)
# 検索結果を表示する
print(result)
//実行結果
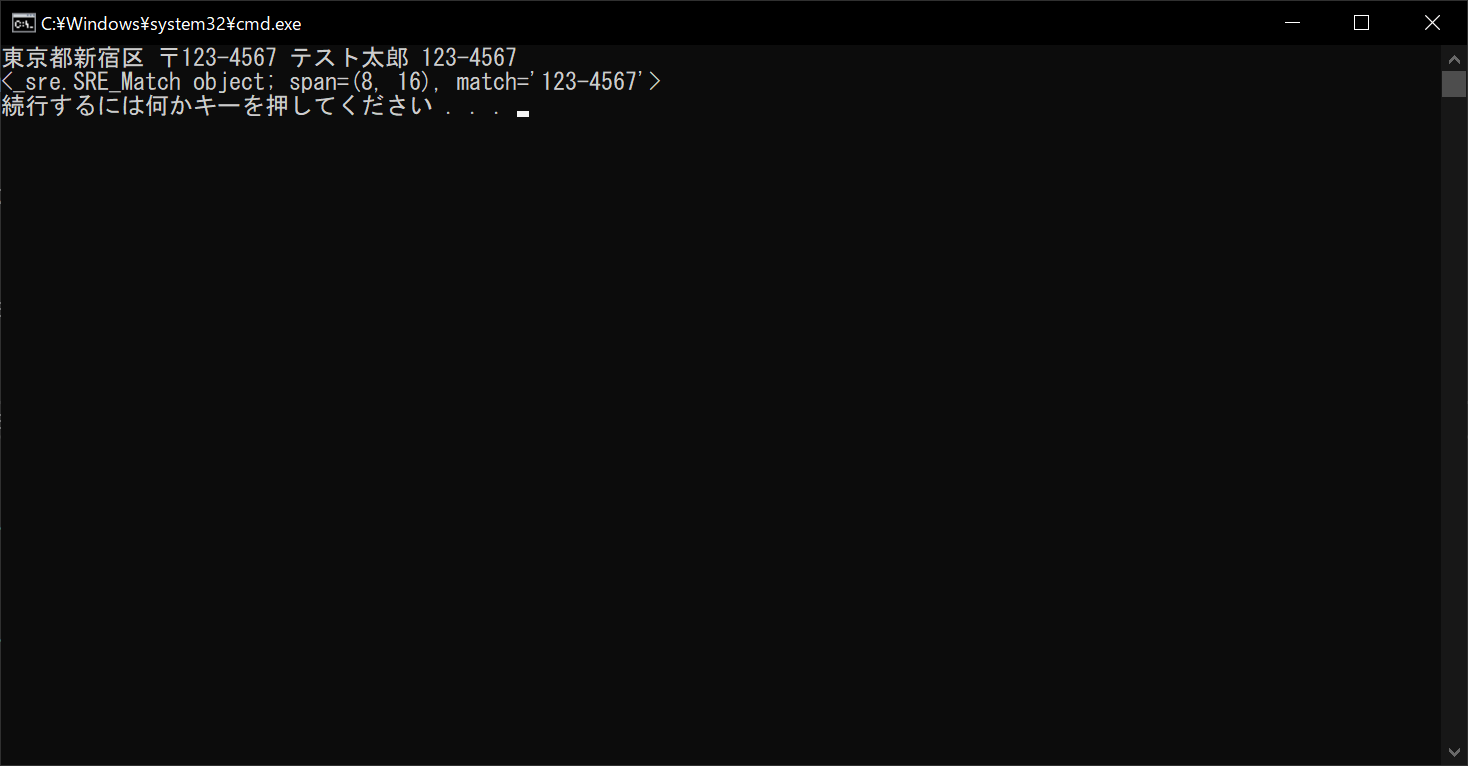
match関数とは異なり、search関数は文字列の途中に該当する部分があっても、問題なく検出できます。ただし「span」の部分を見るとわかるように、2つ目以降の該当部分は無視される形となります。そのため、複数の部分を抽出する必要がある場合は、後述する「findall」や「finditer」を使うのが適切です。
findall|全体の中で一致するすべての文字列を抽出する
「findall」は、全体の中で一致するすべての文字列を抽出するための関数で、構文は以下のとおりです。
findall関数の注意点は、「マッチした文字列の位置情報を取得できない」ことです。findall関数の戻り値はmatchオブジェクトではなく、文字列のリストだからです。実際に、findall関数の使い方と戻り値を、以下のサンプルコードで確認してみましょう。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = "東京都新宿区 〒123-4567 テスト太郎 987-6543"
# 検索したい文字列のパターンを正規表現で指定する
pattern = "[0-9]{3}-[0-9]{4}"
# findall関数で文字列を検索する
result = re.findall(pattern, string)
# 検索対象の文字列を表示する
print(string)
# 検索結果を表示する
print(result)
//実行結果
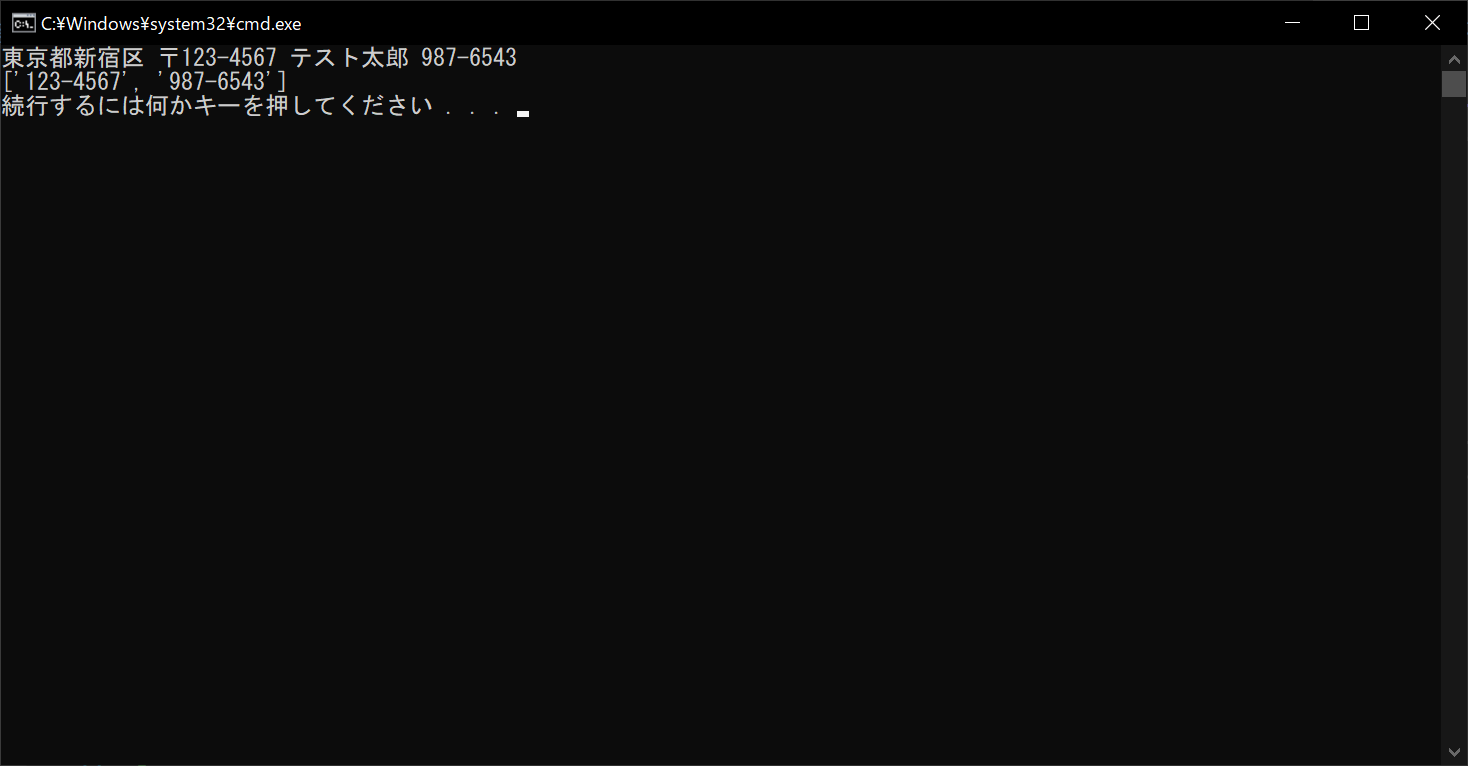
以上のように、戻り値「result」を表示すると、郵便番号が2つ並びます。それぞれの位置情報が必要な場合は、後述する「finditer」を使いましょう。
finditer|全体の中で一致するすべての文字列を抽出する
「finditer」は、全体の中で一致するすべての文字列を抽出するための関数で、構文は以下のとおりです。
前述したfindall関数と構文は同じですが、finditer関数はマッチした文字列の位置情報も取得できることがポイントです。実際に、以下のサンプルコードで確認してみましょう。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = "東京都新宿区 〒123-4567 テスト太郎 987-6543"
# 検索したい文字列のパターンを正規表現で指定する
pattern = "[0-9]{3}-[0-9]{4}"
# finditer関数で文字列を検索する
result = re.finditer(pattern, string)
# 検索対象の文字列を表示する
print(string)
# 検索結果を表示する
for r in result:
print(r)
//実行結果
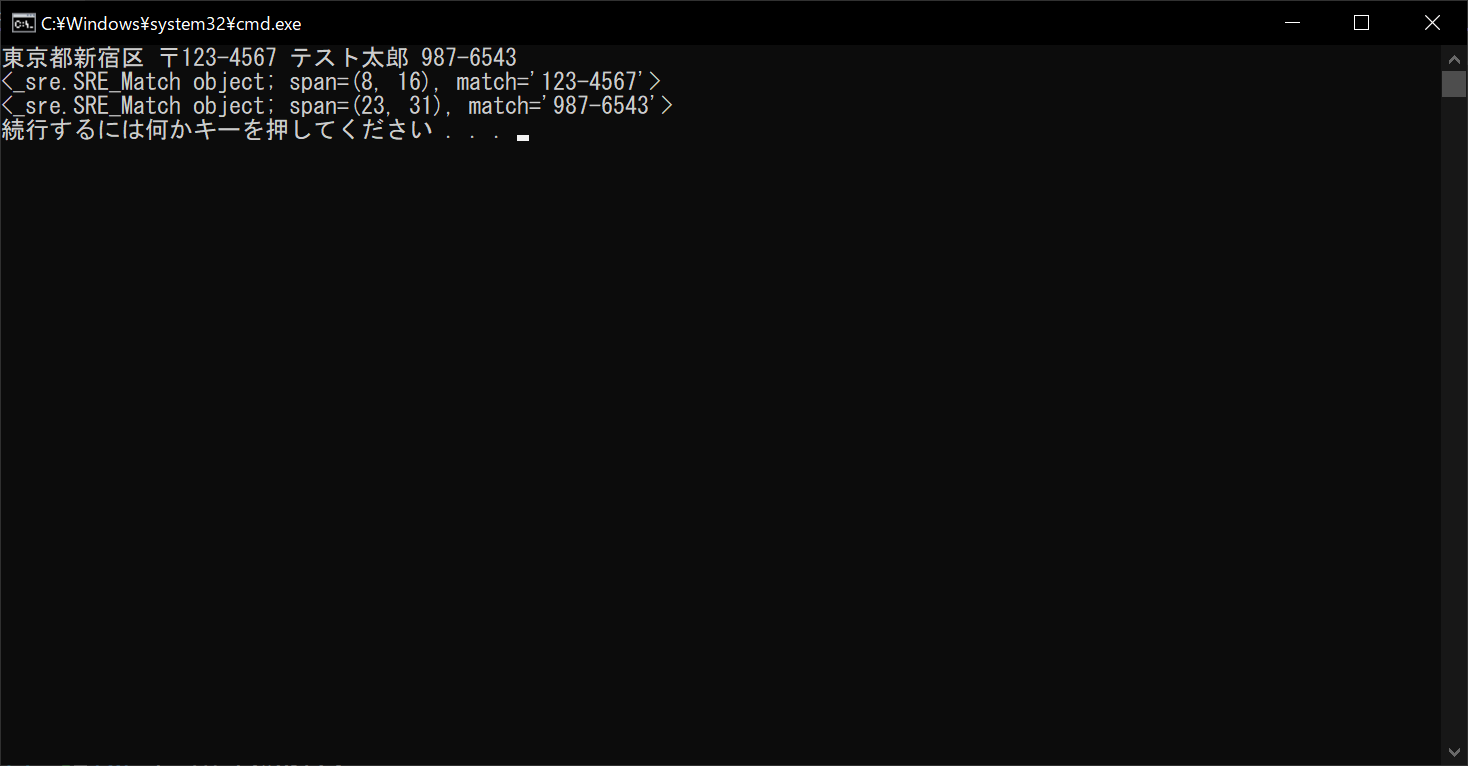
以上のように、finditer関数の戻り値はmatchオブジェクトなので、forループで回すことによってそれぞれの位置情報を取得できます。
fullmatch|文字列全体がパターンと一致しているか確認する
「fullmatch」は、文字列全体がパターンと一致しているか確認するための関数で、構文は以下のとおりです。
これまでに解説した関数は、文字列の一部が正規表現のパターンの「部分一致」を検出するものでした。一方でfullmatch関数は、正規表現のパターンと検索対象の文字列が「完全一致」である場合に限り、matchオブジェクトを返します。fullmatch関数の使い方は以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = "123-4567 東京都新宿区 テスト太郎"
# 検索したい文字列のパターンを正規表現で指定する
pattern = "[0-9]{3}-[0-9]{4}"
# fullmatch関数で文字列を検索する
result = re.fullmatch(pattern, string)
# 検索対象の文字列を表示する
print(string)
# 検索結果を表示する
print(result)
//実行結果
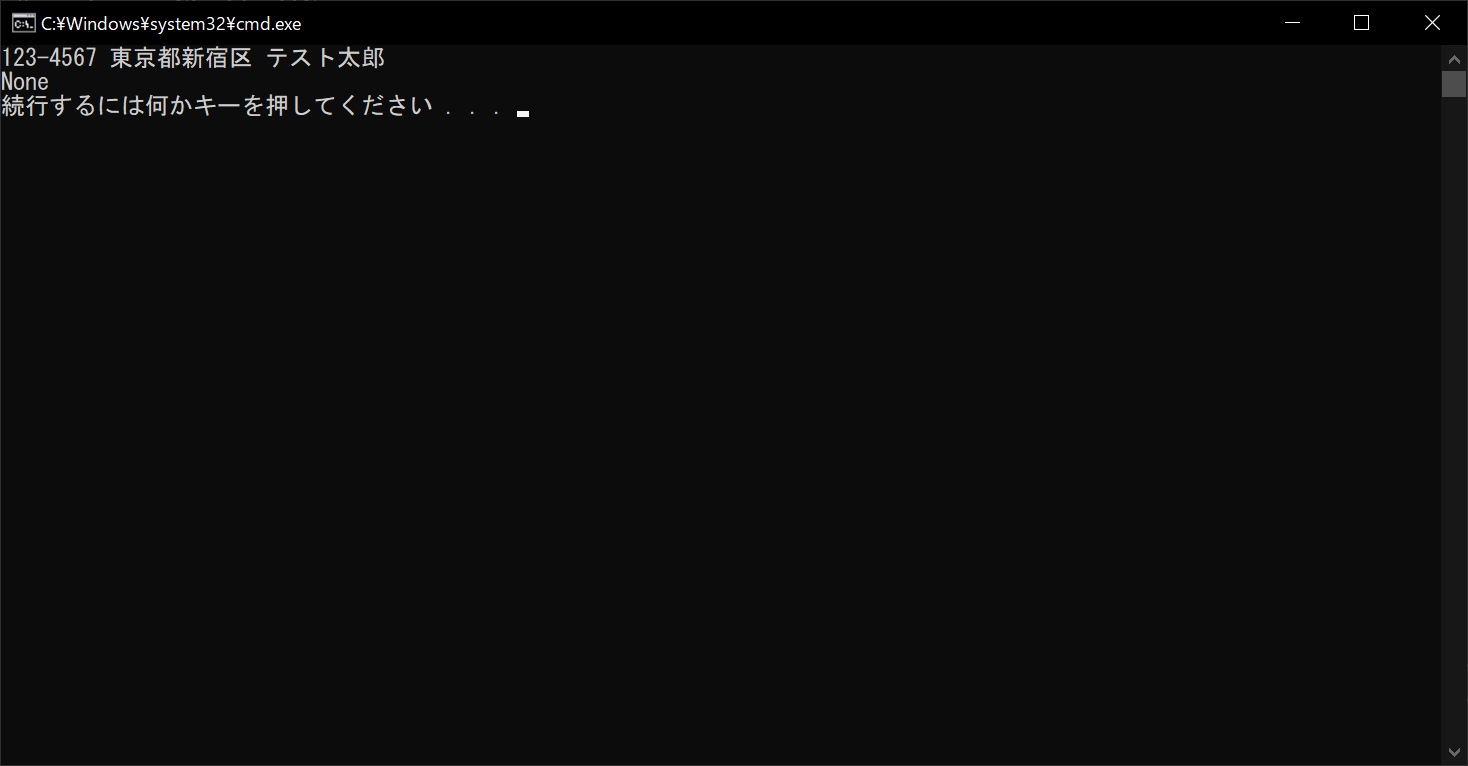
上記のサンプルプログラムでは、これまで同様に正規表現で郵便番号を抽出するようにしていしています。しかし、マッチング関数に「fullmatch」を使用しているため、文字列が郵便番号のみの場合しかマッチしません。今回は、文字列に郵便番号以外も含まれているため、結果は「None」となりました。
sub|パターンに一致した文字列を別の文字列に置換する
「sub」は、パターンに一致した文字列を別の文字列に置換するための関数で、構文は以下のとおりです。
これまでに解説した関数と異なり、sub関数は「文字列の置換」という作業を行います。そのため第2引数には「置換後の文字列」を指定する必要があり、引数の数が1つ増えます。また、sub関数は文字列内の一致する部分すべてを置換するため、正規表現のパターン設定に注意が必要です。sub関数の使い方は、以下のサンプルコードのとおりです。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 置換対象の文字列を設定する
string = "東京都新宿区 〒123-4567 テスト太郎 123-4567"
# 置換したい文字列のパターンを正規表現で指定する
pattern = "[0-9]{3}-[0-9]{4}"
# 置換後の文字列を指定する
replace = "987-6543"
# sub関数で文字列を置換する
result = re.sub(pattern, replace, string)
# 置換対象の文字列を表示する
print(string)
# 置換結果を表示する
print(result)
//実行結果
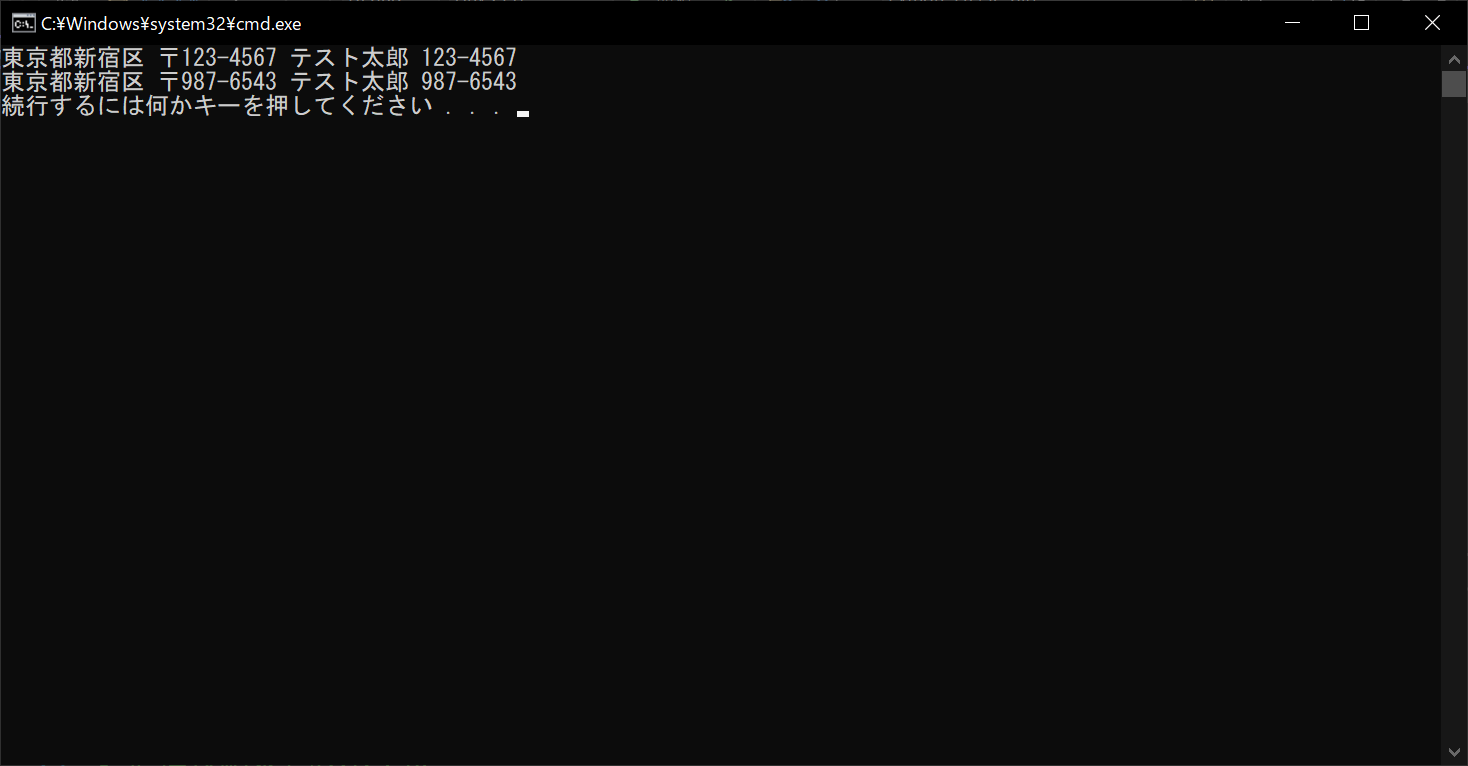
上記のサンプルプログラムでは、文字列の郵便番号の部分を「987-6543」に置き換えています。該当部分は2か所ありますが、どちらも置換されていることがポイントです。
【発展】正規表現のパターンを表す記号と記述方法

Pythonのreモジュールで使える、正規表現の基本的な関数は以上のとおりです。しかし、正規表現を扱ううえで最も重要なのが、正規表現のパターンを表す「記号」と「記述方法」です。しかし、正規表現で使用する記号にはさまざまな種類があるので、ここでは以下6つのカテゴリーに分類して解説します。
- 文字列の先頭や末尾を指定する正規表現の記号
- 繰り返し回数を指定する正規表現の記号
- グループ単位で繰り返し回数を指定する正規表現の記号
- 集合を指定する正規表現の記号
- 文字列の候補を指定する正規表現の記号
- 特殊シーケンスを用いた正規表現の記号
文字列の先頭や末尾を指定する正規表現の記号
以下の記号は、文字列の先頭および末尾から、文字列のパターンを指定するためのものです。
| 正規表現の記号 | 概要 |
| ^ | 文字列の先頭からパターンに一致するか判定する |
| $ | 文字列の末尾からパターンに一致するか判定する |
これらの記号がどのように機能するか、以下のサンプルコードで実際に確認してみましょう。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = "Sample Code"
# 検索対象の文字列を表示する
print("文字列:" + string)
# 「^Sa」の検索結果を表示する
print("「^Sa」:", end="")
print(re.search("^Sa", string))
# 「^am」の検索結果を表示する
print("「^am」:", end="")
print(re.search("^am", string))
# 「de$」の検索結果を表示する
print("「de$」:", end="")
print(re.search("de$", string))
# 「od$」の検索結果を表示する
print("「od$」:", end="")
print(re.search("od$", string))
//実行結果
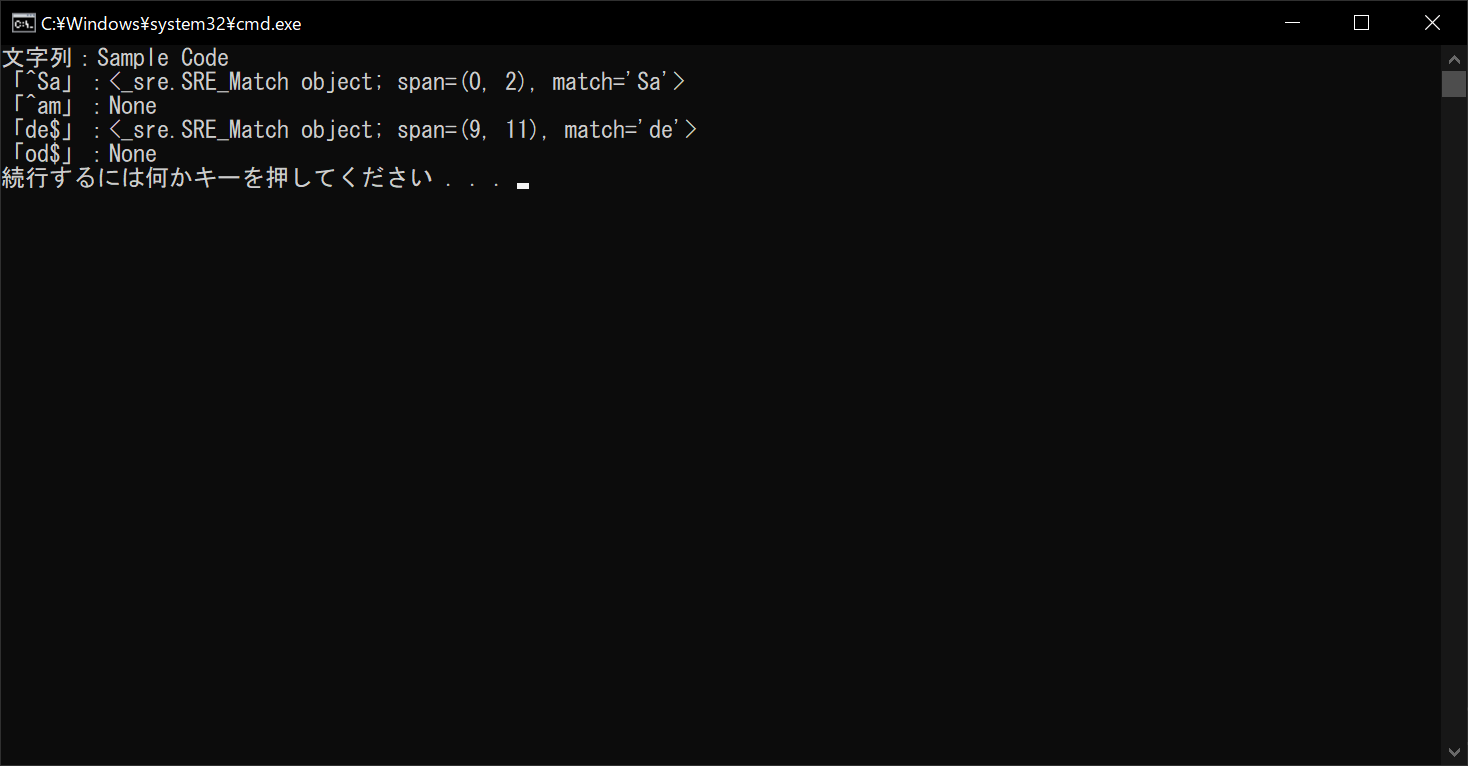
「Sample Code」という文字列は、「Sa」の2文字で始まり「de」で終わります。そのため、「^Sa」と「de$」はマッチしますが、ほかの正規表現はマッチしません。
繰り返し回数を指定する正規表現の記号
以下の記号は、直前に指定したひとつの文字が、繰り返し現れる回数を指定するためのものです。
| 正規表現の記号 | 概要 |
| ? | 0回もしくは1回 |
| * | 0回以上 |
| + | 1回以上 |
| {m} | m回 |
| {m,} | m回以上 |
| {m,n} | m回以上、n回まで |
これらの記号がどのように機能するか、以下のサンプルコードで実際に確認してみましょう。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = "xyyyyyyyz"
# 検索対象の文字列を表示する
print("文字列:" + string)
# 「xy?」の検索結果を表示する
print("「xy?」:", end="")
print(re.search("xy?", string))
# 「xy*」の検索結果を表示する
print("「xy*」:", end="")
print(re.search("xy*", string))
# 「xy+」の検索結果を表示する
print("「xy+」:", end="")
print(re.search("xy+", string))
# 「y{3}」の検索結果を表示する
print("「y{3}」:", end="")
print(re.search("y{3}", string))
# 「y{3,}」の検索結果を表示する
print("「y{3,}」:", end="")
print(re.search("y{3,}", string))
# 「y{3,5}」の検索結果を表示する
print("「y{3,5}」:", end="")
print(re.search("y{3,5}", string))
//実行結果
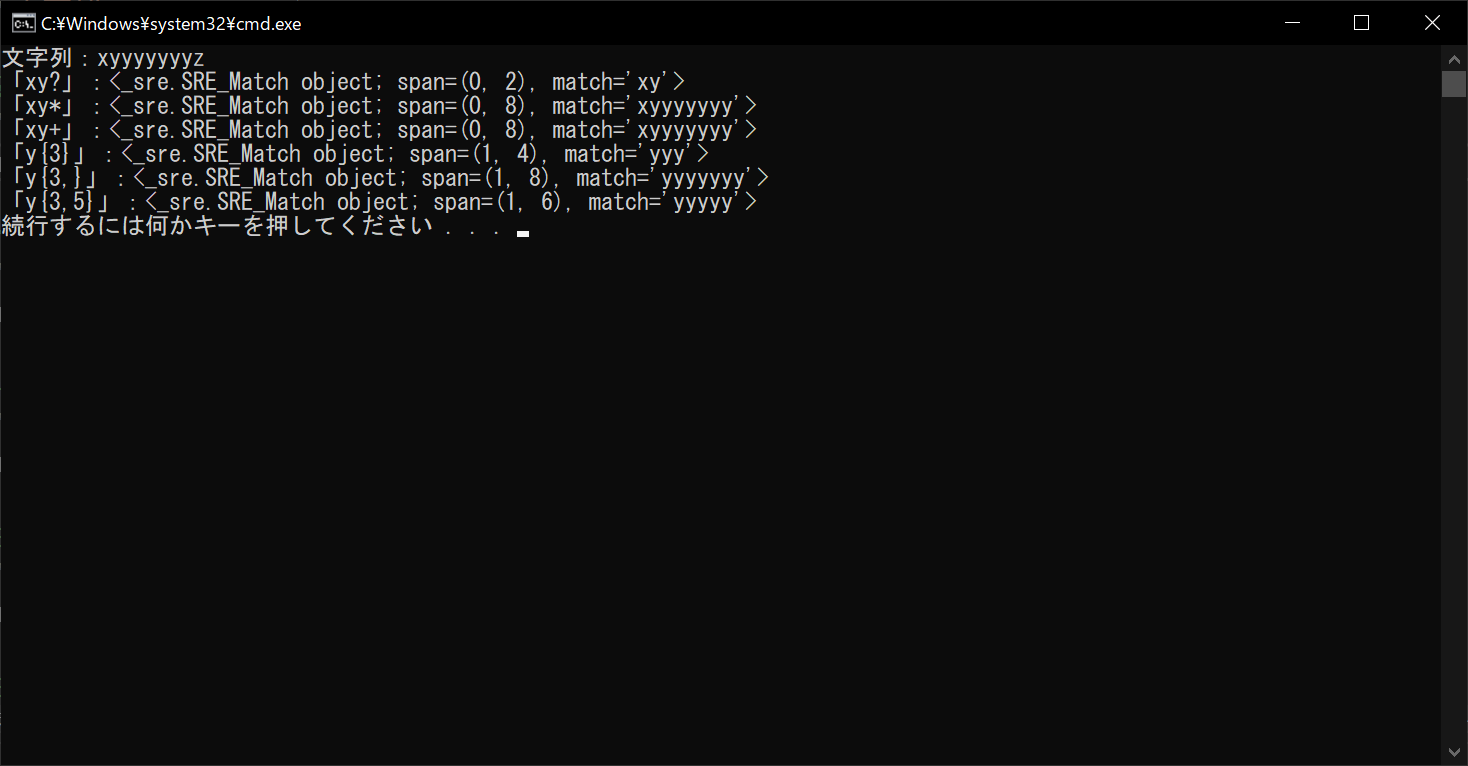
最初の「xy?」は、「xのあとにyが0回もしくは1回ある」というパターンを示す正規表現です。つまり、「x」または「xy」がこの条件に該当します。したがって、「xyyyyyyyz」の前半2文字分の「xy」が抽出されるということです。
次の「xy*」は、「xのあとにyが0回以上ある」パターンを示します。最初に「x」さえあれば、yが何回あっても・なくても該当するため、「z」が来るまでの文字列「xyyyyyyy」が抽出されます。「xy+」は、「必ず1回以上はyがある」パターンを示すため、今回は「xy*」と同じく「xyyyyyyy」が該当します。
「y{3}」「y{3,}」「y{3,5}」は、それぞれyが「3回」「3回以上」「3~5回」あるパターンを示す正規表現です。今回の例では、いずれもパターンに該当します。なお、「xyyz」のような文字列の場合はyが2回しか連続しないため、3つの正規表現はいずれも不一致となります。
グループ単位で繰り返し回数を指定する正規表現の記号
以下の記号は、複数の文字列をひとつのグループとして、繰り返し現れる回数を指定するためのものです。
| 正規表現の記号 | 概要 |
| ( ) | 丸カッコで囲った文字列をグループ化する |
前述した「繰り返し回数を指定する記号」は、直前の1文字だけを対象としました。丸カッコで文字列を囲えば、その文字列をひとつのまとまりとして、繰り返し回数を指定できます。実際にどのように機能するか、以下のサンプルコードで確認してみましょう。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = "xyzyzyzyzyz"
# 検索対象の文字列を表示する
print("文字列:" + string)
# 「x(yz)?」の検索結果を表示する
print("「x(yz)?」:", end="")
print(re.search("x(yz)?", string))
# 「x(yz)*」の検索結果を表示する
print("「x(yz)*」:", end="")
print(re.search("x(yz)*", string))
# 「x(yz)+」の検索結果を表示する
print("「x(yz)+」:", end="")
print(re.search("x(yz)+", string))
# 「x(yz){3}」の検索結果を表示する
print("「x(yz){3}」:", end="")
print(re.search("x(yz){3}", string))
# 「x(yz){3,}」の検索結果を表示する
print("「x(yz){3,}」:", end="")
print(re.search("x(yz){3,}", string))
# 「x(yz){3,5}」の検索結果を表示する
print("「x(yz){3,5}」:", end="")
print(re.search("x(yz){3,5}", string))
//実行結果
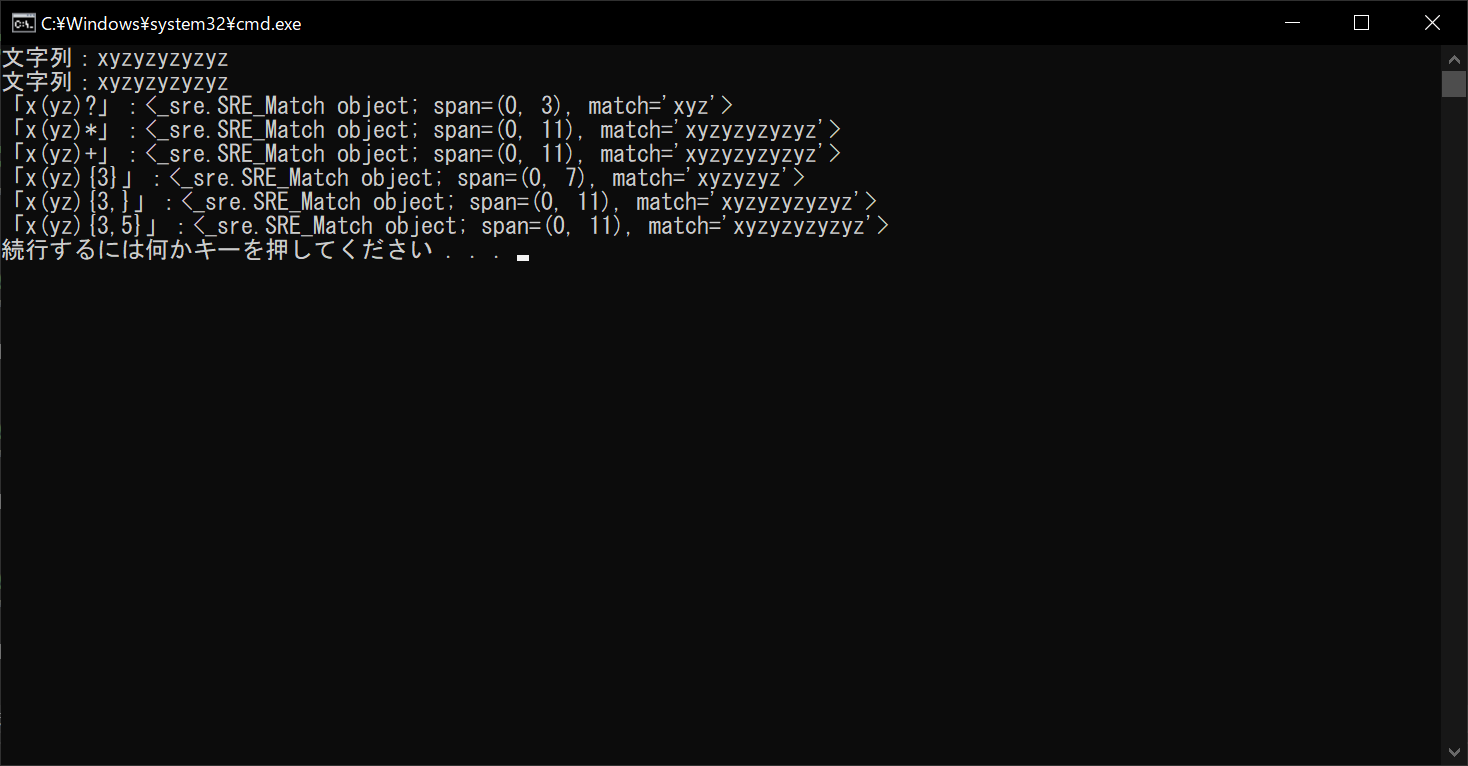
繰り返し回数を指定する正規表現の振る舞い自体は、先ほどのサンプルコードと同じです。しかし、「yz」という文字列を対象として、繰り返し回数のパターンを設定できていることがポイントです。
集合を指定する正規表現の記号
以下の記号は、特定の条件に該当する文字列の集合を指定するためのものです。
| 正規表現の記号 | 概要 |
| [0-9] | すべての数字 |
| [a-zA-Z] | すべてのアルファベット |
| [a-zA-Z0-9] | すべてのアルファベットと数字 |
| [^a-zA-Z0-9] | すべてのアルファベットと数字以外 集合に^(ハット)を付けると、集合の条件の否定となり、集合の条件を満たさない場合、一致となります。 |
指定したい範囲の「最初」と「最後」をハイフンでつなぐことで、集合を表現できます。複数の集合を指定するときは、そのまま続けて記載すればOKです。また、キャレット(ハット)記号「^」を先頭につけると否定となり、集合の条件を満たさないものを指定できます。これらの記号がどのように機能するか、以下のサンプルコードで確認してみましょう。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = "12345ABCDEサンプル"
# 検索対象の文字列を表示する
print("文字列:" + string)
# 「[0-9]」の検索結果を表示する
print("「[0-9]」:", end="")
print(re.search("[0-9]", string))
# 「[0-9]+」の検索結果を表示する
print("「[0-9]+」:", end="")
print(re.search("[0-9]+", string))
# 「[a-zA-Z]」の検索結果を表示する
print("「[a-zA-Z]」:", end="")
print(re.search("[a-zA-Z]", string))
# 「[a-zA-Z]+」の検索結果を表示する
print("「[a-zA-Z]+」:", end="")
print(re.search("[a-zA-Z]+", string))
# 「[a-zA-Z0-9]」の検索結果を表示する
print("「[a-zA-Z0-9]」:", end="")
print(re.search("[a-zA-Z0-9]", string))
# 「[a-zA-Z0-9]+」の検索結果を表示する
print("「[a-zA-Z0-9]+」:", end="")
print(re.search("[a-zA-Z0-9]+", string))
# 「[^a-zA-Z0-9]」の検索結果を表示する
print("「[^a-zA-Z0-9]」:", end="")
print(re.search("[^a-zA-Z0-9]", string))
# 「[^a-zA-Z0-9]+」の検索結果を表示する
print("「[^a-zA-Z0-9]+」:", end="")
print(re.search("[^a-zA-Z0-9]+", string))
//実行結果
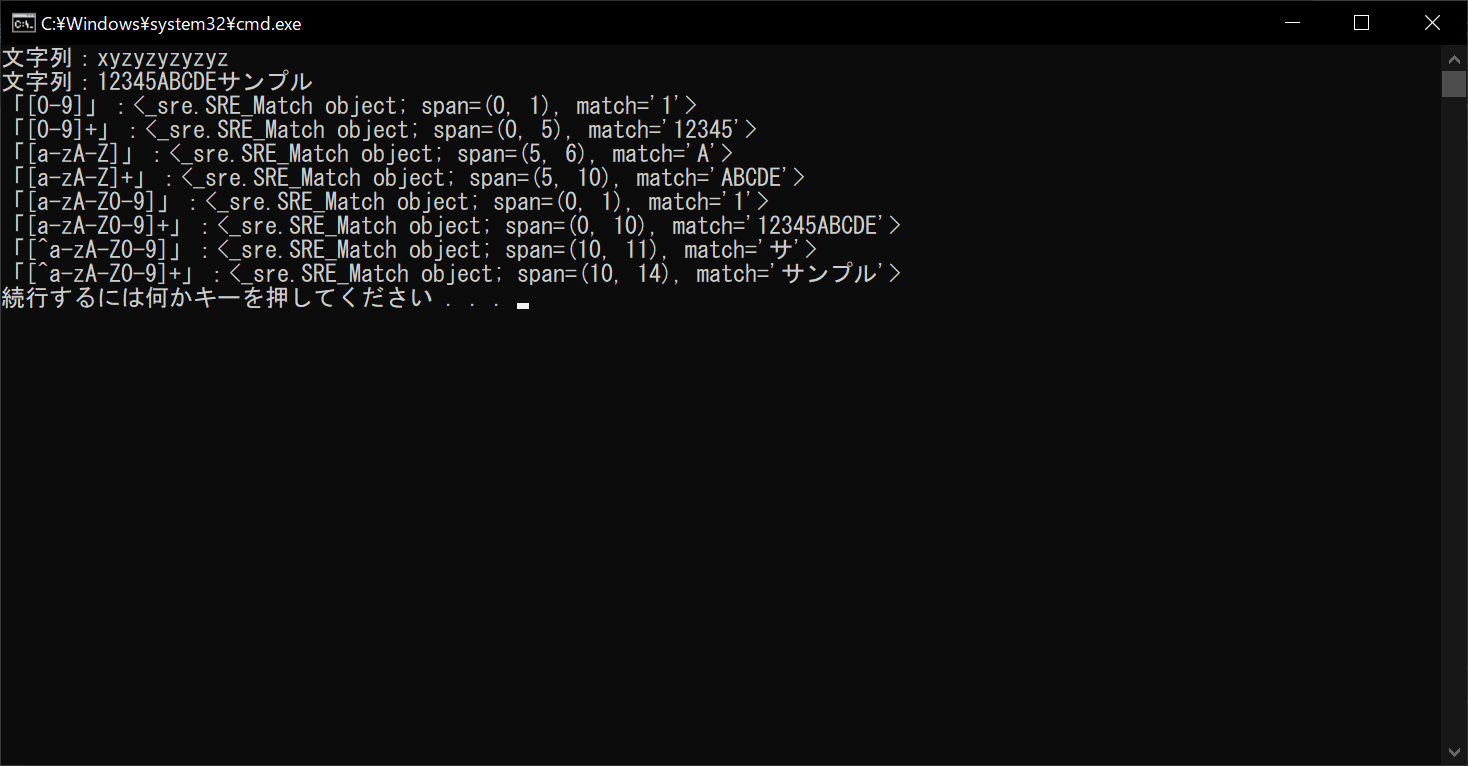
上記のように、正規表現によって半角数字・半角英字・半角英数字をそれぞれ区別して、文字列から抽出できます。ただし、これらの正規表現はいずれも「半角」限定で、全角は検出できないので注意が必要です。
文字列の候補を指定する正規表現の記号
以下の記号は、文字列の候補を用意して、いずれかを満たす場合に文字列を抽出するためのものです。
| 正規表現の記号 | 概要 |
| | | 指定した文字列のいずれかを含む |
| [ ] | 指定した文字列のいずれかを含む |
上記の「|」と「[ ]」は書き方は異なりますが、どちらも同じ動作となります。これらの記号がどのように機能するか、以下のサンプルコードで実際に確認してみましょう。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = "xyzxyzxyz"
# 検索対象の文字列を表示する
print("文字列:" + string)
# 「(x|y)z」の検索結果を表示する
print("「(x|y)z」:", end="")
print(re.search("(x|y)z", string))
# 「x|yz」の検索結果を表示する
print("「x|yz」:", end="")
print(re.search("x|yz", string))
# 「[xy]z」の検索結果を表示する
print("「[xy]z」:", end="")
print(re.search("[xy]z", string))
//実行結果
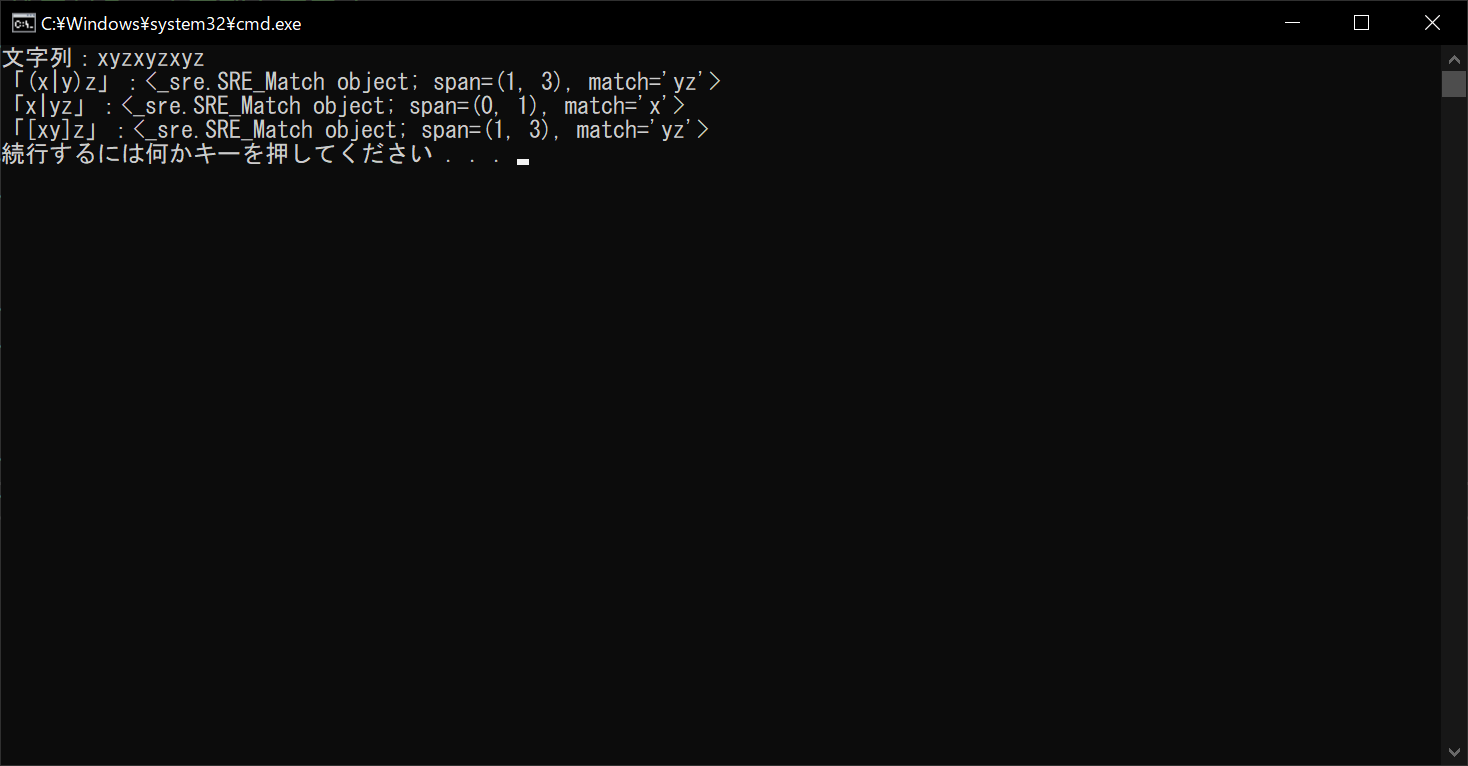
「(x|y)z」と「x|yz」では、結果が異なることに注意が必要です。「(x|y)z」は「xもしくはy」を意味しますが、「x|yz」は「xもしくはyz」となります。そのため、文字列ではなく文字の候補を指定するのであれば、「[xy]z」と記載するほうがわかりやすいでしょう。
特殊シーケンスを用いた正規表現の記号
「すべての数字」や「すべての文字」などのパターンは、以下のような「円マーク」や「バックスラッシュ」による「特殊シーケンス」で、簡易的に表現できます。
| 正規表現の記号 | 概要 |
| \d | すべての数字 |
| \D | すべての数字以外 |
| \w | すべての文字とアンダーバー |
| \W | すべての文字とアンダーバー以外 |
| \s | 空白 |
| \S | 空白以外 |
| \A | 文字列の先頭(^と同じ) |
| \Z | 文字列の末尾($と同じ) |
特殊シーケンスを使うと、通常よりはるかに簡潔に記載できることがわかります。これらの記号がどのように機能するか、以下のサンプルコードで実際に確認してみましょう。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = "abc_def_ghi 123_456_789"
# 検索対象の文字列を表示する
print("文字列:" + string)
# 「\d+」の検索結果を表示する
print("「\d+」:", end="")
print(re.search("\d+", string))
# 「\w+」の検索結果を表示する
print("「\w+」:", end="")
print(re.search("\w+", string))
# 「\W+」の検索結果を表示する
print("「\W+」:", end="")
print(re.search("\W+", string))
# 「\s+」の検索結果を表示する
print("「\s+」:", end="")
print(re.search("\s+", string))
# 「\S+」の検索結果を表示する
print("「\S+」:", end="")
print(re.search("\S+", string))
# 「\Aabc」の検索結果を表示する
print("「\Aabc」:", end="")
print(re.search("\Aabc", string))
# 「789\Z」の検索結果を表示する
print("「789\Z」:", end="")
print(re.search("789\Z", string))
//実行結果
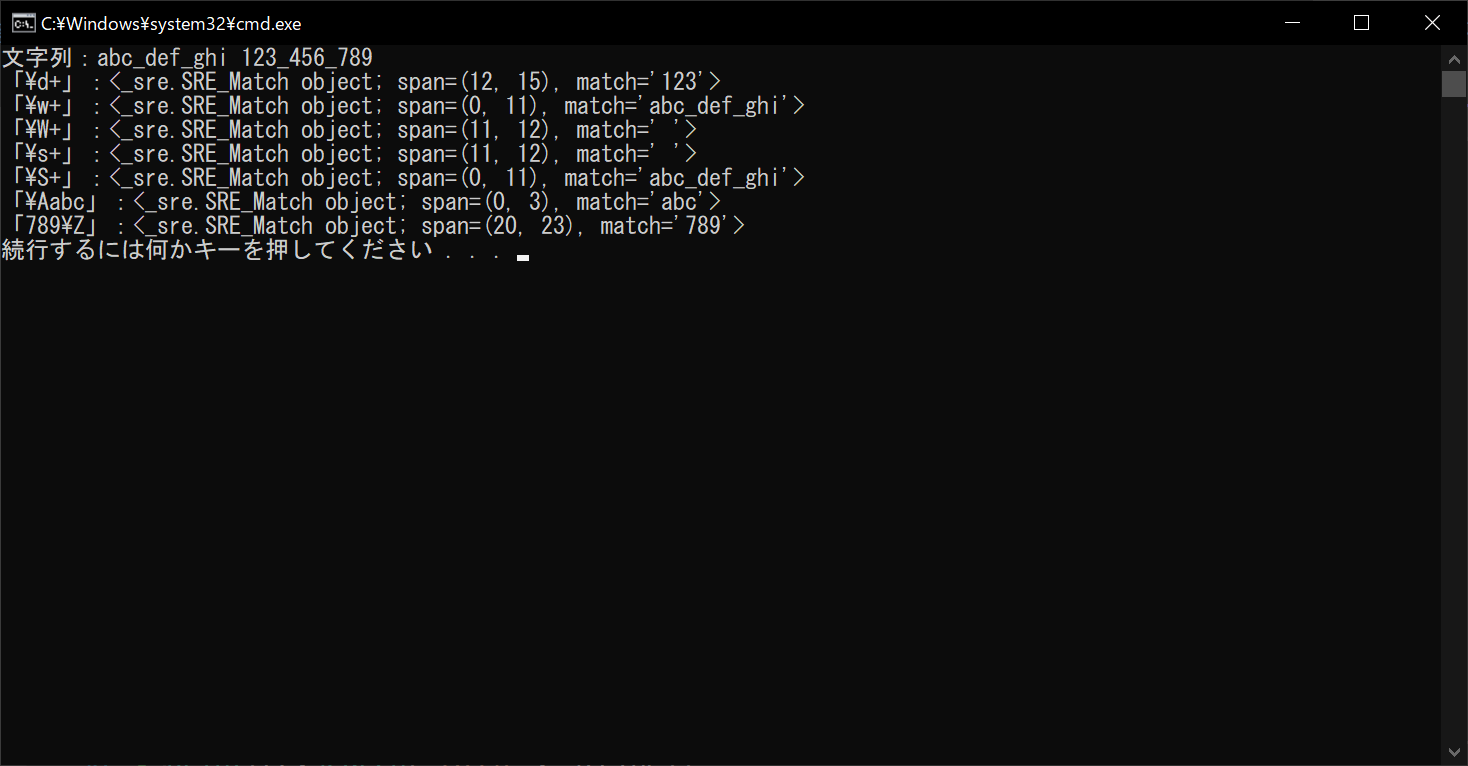
ただし、「\d」や「\w」などの特殊シーケンスは、半角のASCII文字だけではなく、日本語や中国語などのような「全角文字(マルチバイト文字)」も含まれます。半角英数字に限定してマッチングしたい場合は、後述する「フラグ引数」の使用が必要です。
正規表現パターンのコンパイルによる効率化

reモジュールでは、正規表現のパターンを「コンパイル」することによって、同じパターンを効率的に再利用することや、より高度な検索や抽出ができるようになります。正規表現パターンのコンパイルは、以下の構文で「re.compile関数」を使うことで可能です。
pattern = re.compile(正規表現のパターン)
# コンパイルしたオブジェクトでマッチングを行う
result = pattern.match(検索対象の文字列)
手順自体はいたって簡単で、まずはre.compile関数で正規表現パターンのオブジェクトを作成し、「pattern変数」に格納します。実際にマッチングを行うときは、pattern変数のmatch関数やsearch関数などで、引数として検索対象の文字列を引き渡すだけです。正規表現のパターンをコンパイルすることで、さまざまな文字列に対して効率的なマッチングが行えます。詳細を以下のサンプルコードで確認しましょう。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 正規表現パターンをコンパイルする
pattern = re.compile("\w+")
# match関数で「123」とマッチングする
print("「123」:", end="")
print(pattern.match("123"))
# search関数で「abc」とマッチングする
print("「abc」:", end="")
print(pattern.search("abc"))
# match関数で「テスト」とマッチングする
print("「テスト」:", end="")
print(pattern.match("テスト"))
//実行結果
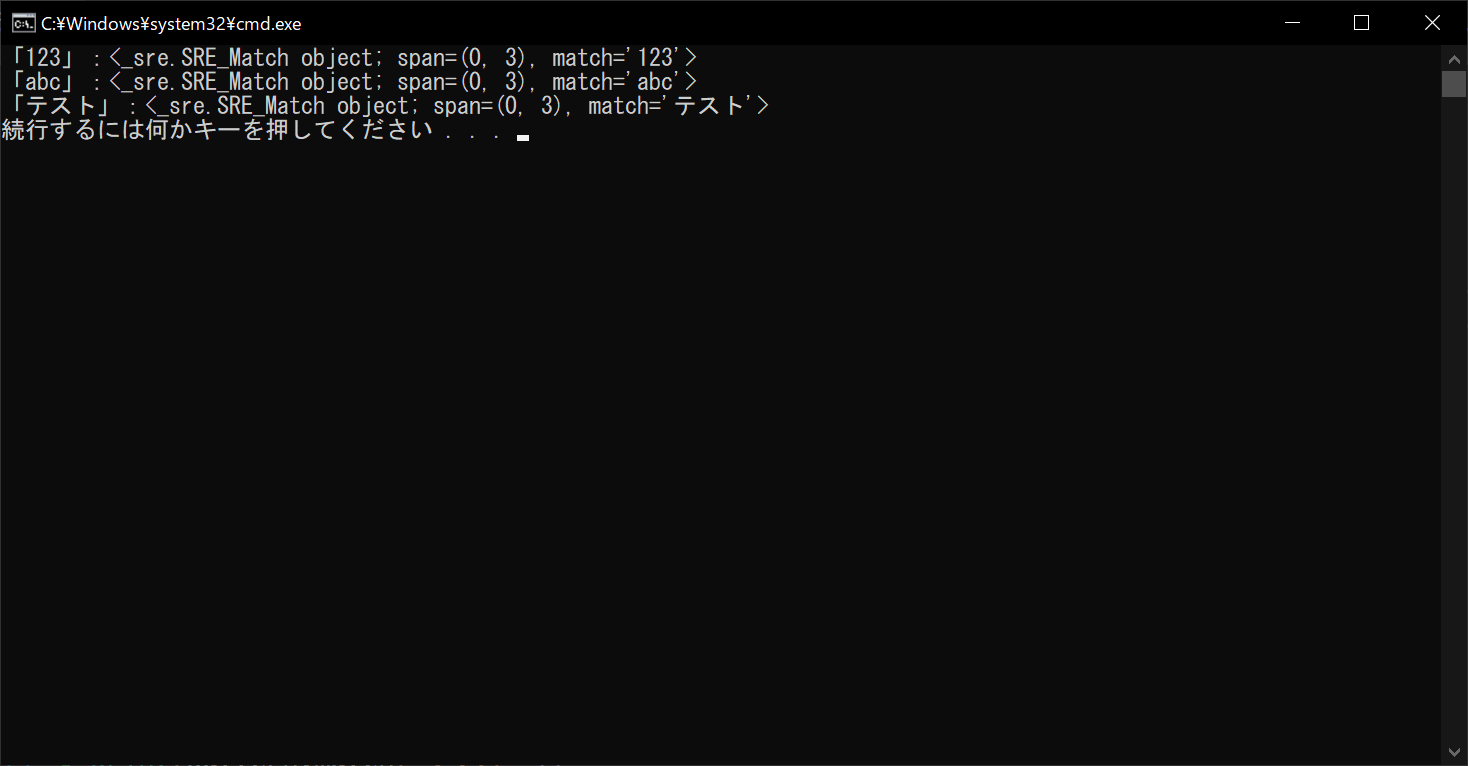
上記のサンプルプログラムでは、「\w+」という正規表現パターンをコンパイルして、以降のマッチングで使いまわしています。コンパイル済みのパターンを再利用すると、マッチング処理の負荷が下がり、実行速度の向上が期待できます。
【応用】フラグ引数によるマッチ条件の制御

reモジュールの正規表現に関する各種関数では、「フラグ引数」を引き渡すことにより、マッチ条件を詳細に指定できます。
- 大文字と小文字を区別せずにマッチングを行う
- 各行の先頭と末尾でマッチングを行う
- 正規表現パターンを分割してコメントを付加する
- 正規表現パターンに名前を付けて参照する
- 半角のASCII文字限定でマッチングする
大文字と小文字を区別せずにマッチングを行う
大文字と小文字を区別せずにマッチングを行いたいときは、フラグ引数「re.IGNORECAE」を渡しましょう。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = "xyzXYZxyz"
# 検索対象の文字列を表示する
print("文字列:" + string)
# 「[a-z]+」で大文字・小文字を区別してマッチングする
print("「[a-z]+」:", end="")
print(re.search("[a-z]+", string))
# 「[a-z]+」で大文字・小文字を区別せずにマッチングする
print("「[a-z]+」:", end="")
print(re.search("[a-z]+", string, re.IGNORECASE))
//実行結果
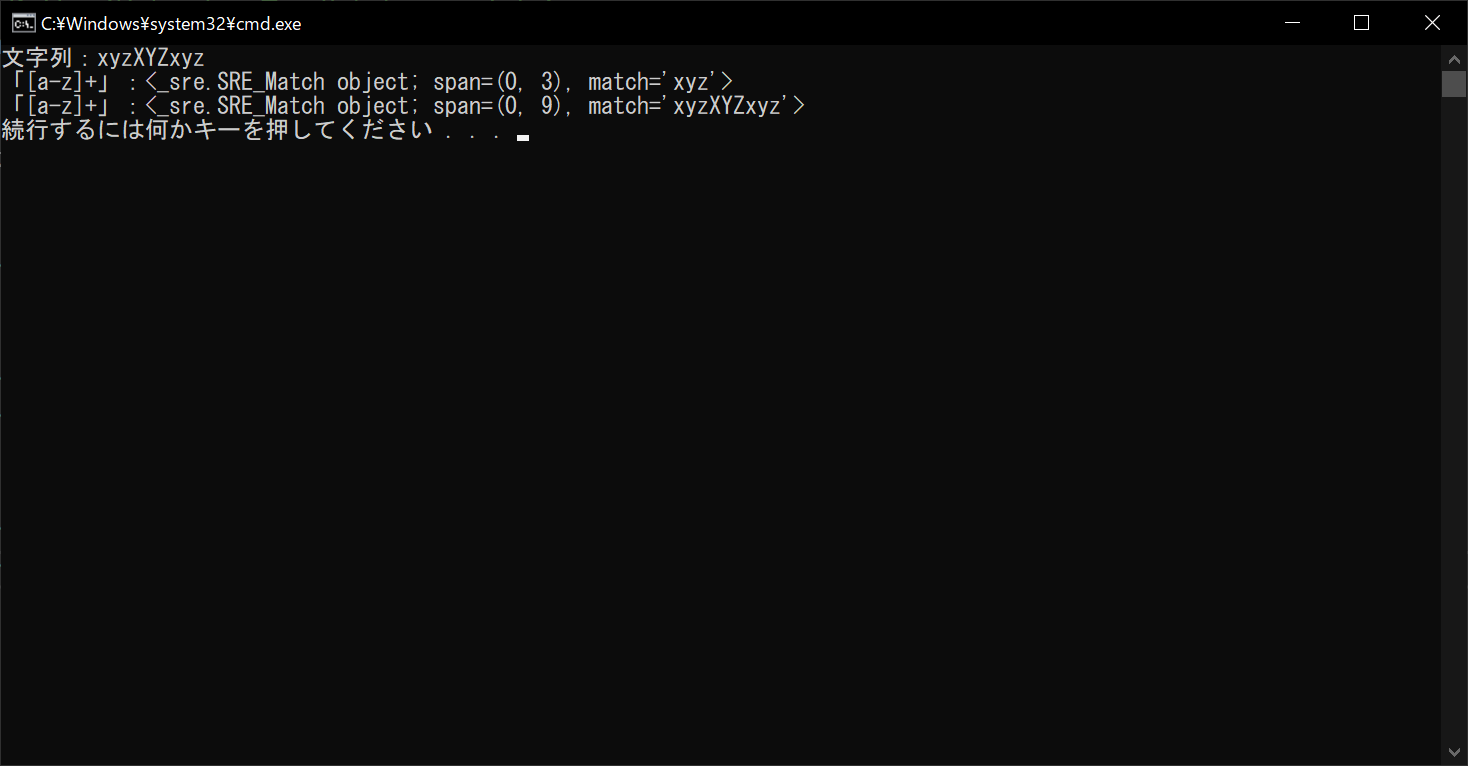
フラグ引数を渡さないときは、マッチングの抽出結果が「abc」の3文字だけで途切れています。しかし、フラグ引数を渡すことで大文字の部分も該当するようになるため、文字列全体がマッチします。
各行の先頭と末尾でマッチングを行う
各行の先頭と末尾でマッチングを行いたいときは、フラグ引数「re.MULTILINE」を渡しましょう。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = """abc, 789, ZYX
def, 456, WVU
ghi, 789, TSR"""
# 検索対象の文字列を表示する
print("文字列:" + string)
# 「^[a-z]+」で先頭行のみマッチングする
print("「^[a-z]+」:", end="")
print(re.findall("^[a-z]+", string))
# 「^[a-z]+」で全行にマッチングする
print("「^[a-z]+」:", end="")
print(re.findall("^[a-z]+", string, re.MULTILINE))
//実行結果
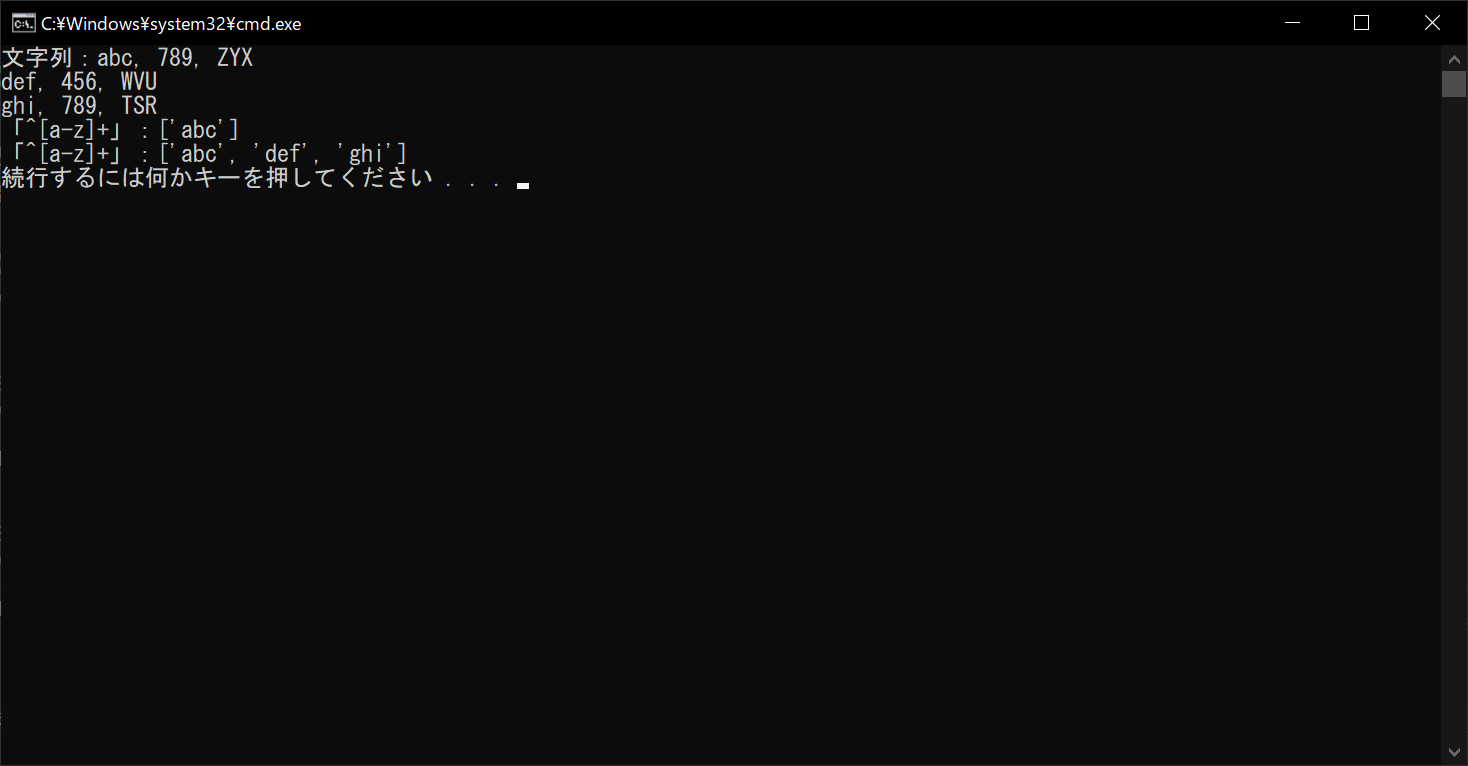
フラグ引数を渡さない場合は、1行分しかマッチングが行われません。しかし、フラグ引数を渡すことにより、複数行にわたって文字列の抽出ができるようになります。
正規表現パターンを分割してコメントを付加する
正規表現パターンを分割してコメントを付加したいときは、フラグ引数「re.VERBOSE」を渡しましょう。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 正規表現パターンをコンパイルする
pattern = re.compile("""
[0-9]{4}- #年
[0-9]{1,2}- #月
[0-9]{1,2} #日
""", re.VERBOSE)
# 文字列「Today is 2023-1-1」とマッチングを行う
print("「Today is 2023-1-1」:", end="")
print(pattern.findall("Today is 2023-1-1"))
//実行結果
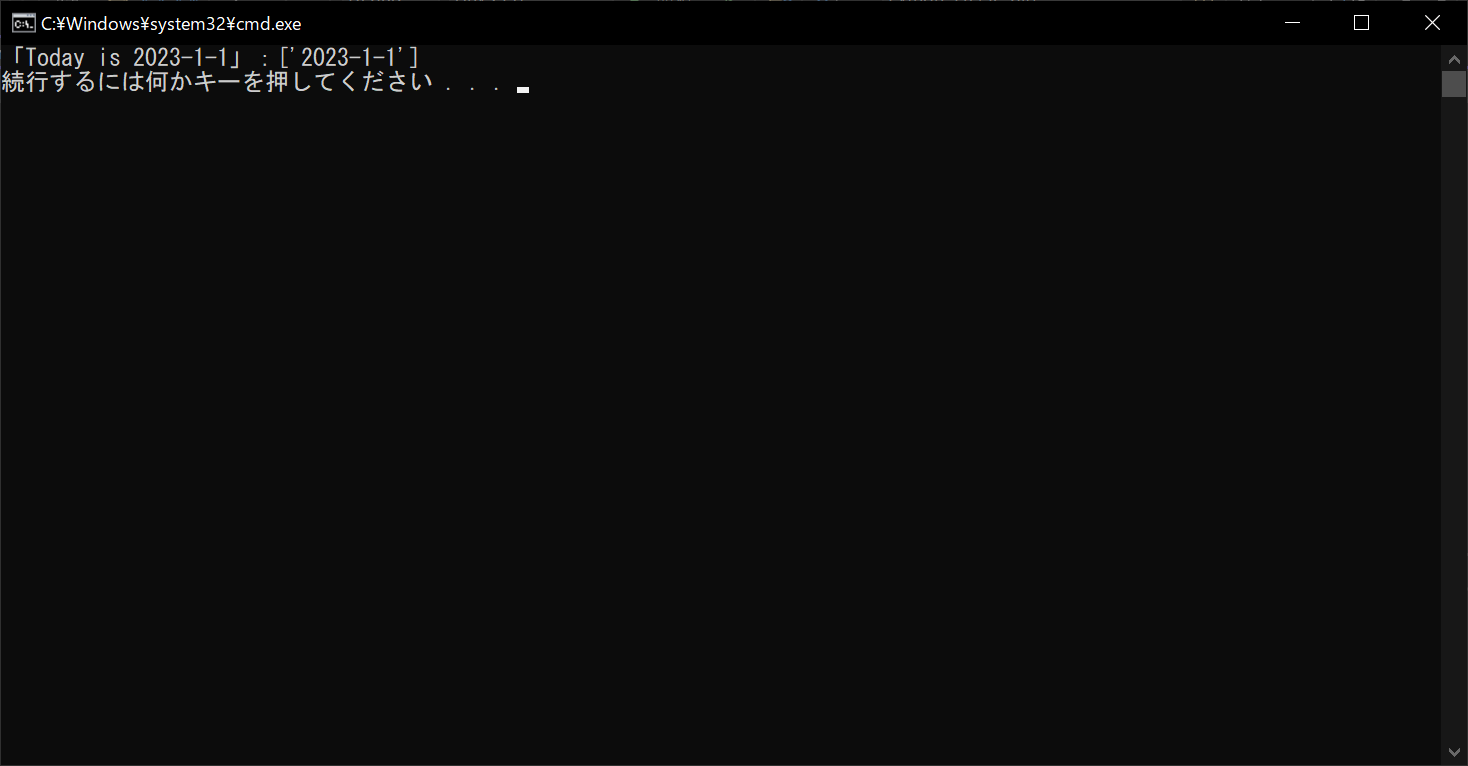
各行における「#年」「#月」「#日」はコメントとして扱われ、検索対象の文字列には含まれていないことがわかります。
正規表現パターンに名前を付けて参照する
正規表現パターンに名前を付けて参照したいときは、グループ化したい文字列を「(?P<グループ名>パターン)」と囲みましょう。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 正規表現パターンをコンパイルする
pattern = re.compile("""
(?P<Year>[0-9]{4})- #年
(?P<Month>[0-9]{1,2})- #月
(?P<Day>[0-9]{1,2}) #日
""", re.VERBOSE)
# 文字列「Today is 2023-1-1」とマッチングを行う
print("「Today is 2023-1-1」:", end="")
result = pattern.search("Today is 2023-1-1")
# グループごとにマッチング結果を表示する
print(result.group("Year"))
print(result.group("Month"))
print(result.group("Day"))
//実行結果
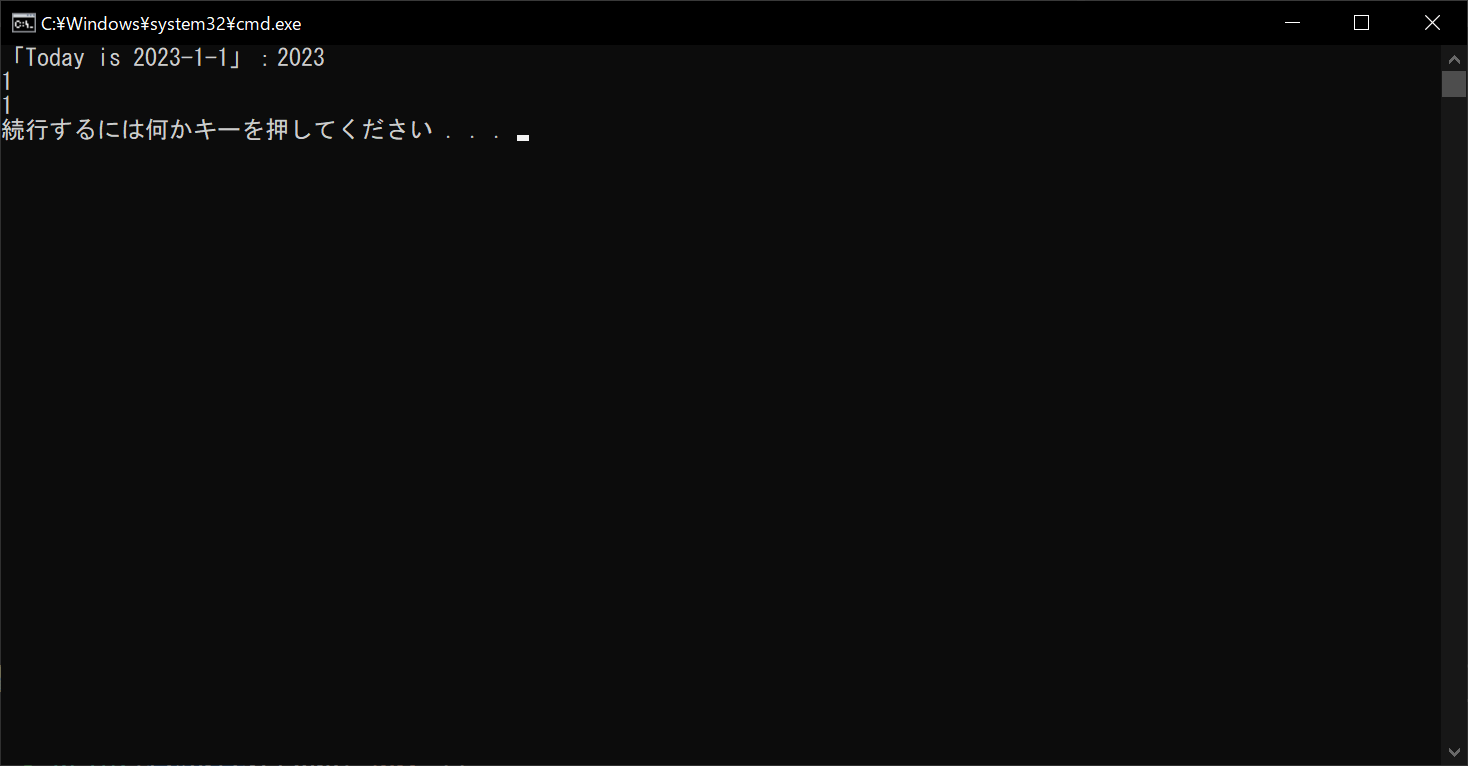
group関数の引数に「グループ名」を渡すことで、その部分の検出文字列を取得できます。
半角のASCII文字限定でマッチングする
前述したように、「\d」や「\w」などの特殊シーケンスは、「全角文字(マルチバイト文字)」も該当するため、正確なマッチングができないことがあります。半角のASCII文字限定でマッチングさせたいときは、フラグ引数「re.ASCII」を渡しましょう。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
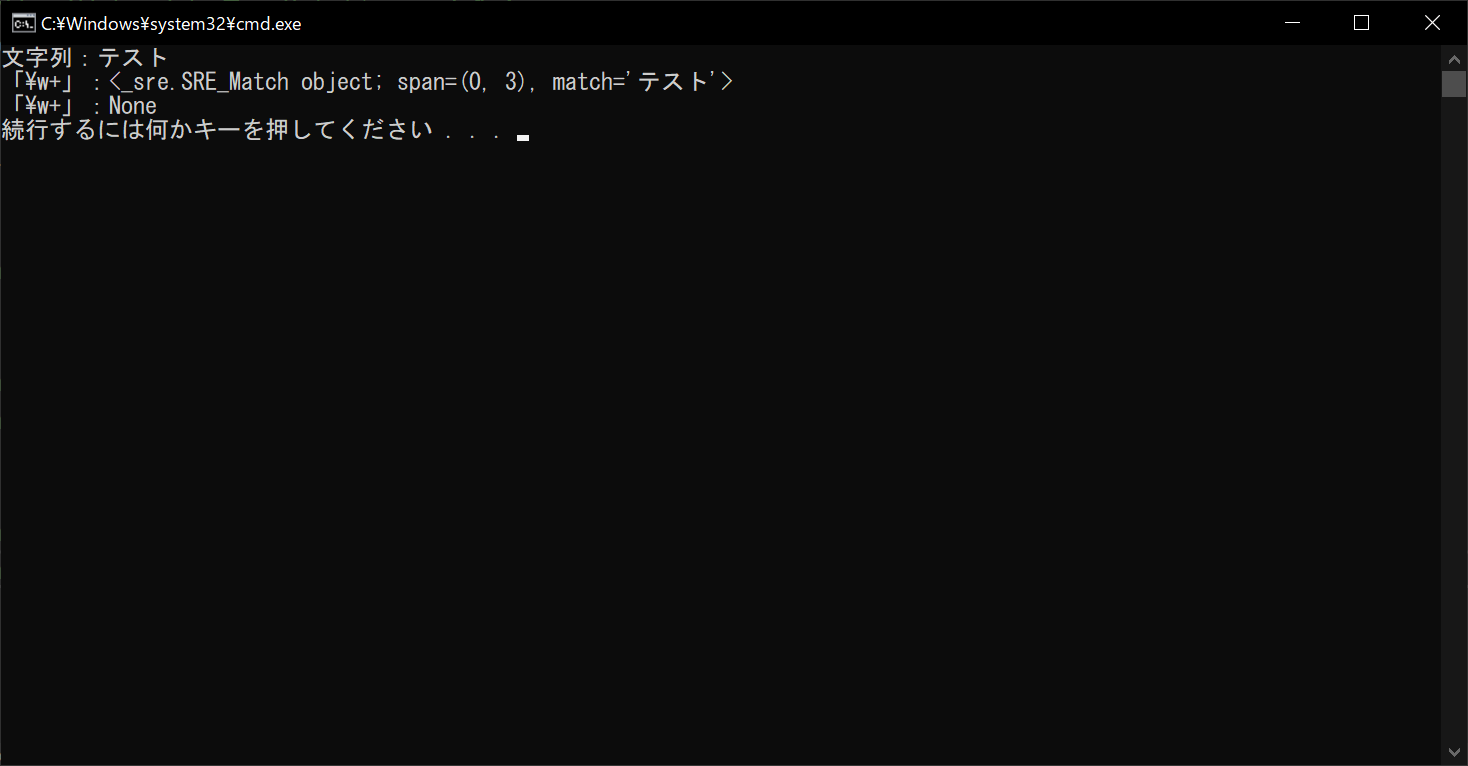
string = "テスト"
# 検索対象の文字列を表示する
print("文字列:" + string)
# 「\w+」で通常マッチングを行う
print("「\w+」:", end="")
print(re.match("\w+", string))
# 「\w+」でASCII文字に限定してマッチングを行う
print("「\w+」:", end="")
print(re.match("\w+", string, re.ASCII))
//実行結果
Pythonの正規表現で知っておくと便利な知識

以下2つについて理解しておくと、Pythonの正規表現がさらに便利に使えるようになります。
- 特殊文字をパターンに含めるための記号
- 「貪欲マッチ」と「非貪欲マッチ」の違いと指定方法
特殊文字をパターンに含めるための記号
「*」や「?」など、正規表現のパターン記号として使用する「特殊文字」を検索したい場合は、そのまま正規表現に含めるとエラーが出ます。なぜなら、「*」や「?」はパターン記号として認識され、不正な正規表現パターンとなるからです。そのため、特殊記号を抽出したい場合は、その直前に「バックスラッシュ」を付ける必要があります。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = "xyz?"
# 検索対象の文字列を表示する
print("文字列:" + string)
# 「?」で通常マッチングを行う
# ただしエスケープ文字「\」が必要
# エスケープ文字「\」がないとエラーが出る
print("「\?」:", end="")
print(re.search("\?", string))
//実行結果
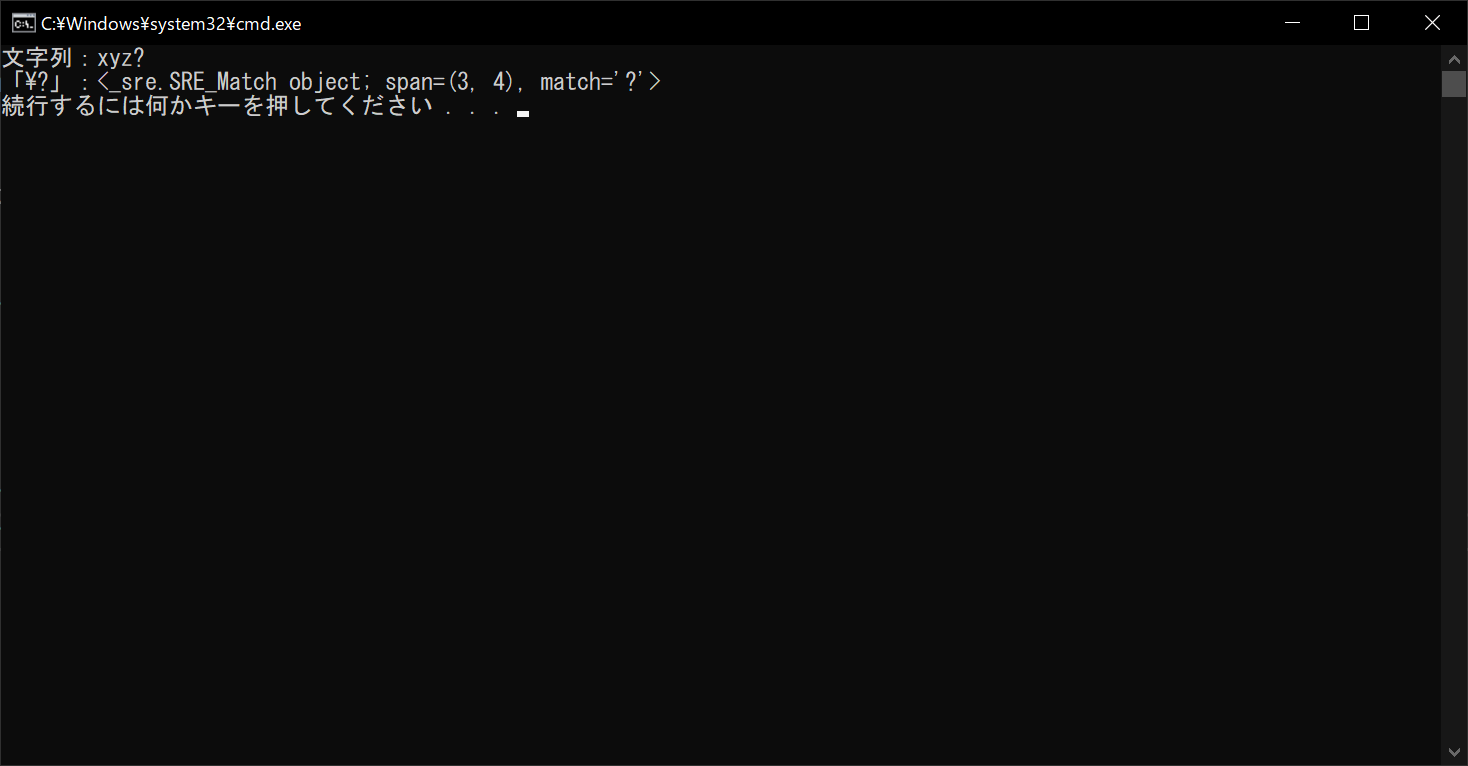
上記のサンプルプログラムでは、「?」を検出するための正規表現として、「\?」を指定しています。バックスラッシュを付けることにより、「?」が正規表現パターンの記号ではなく、検出したい文字として認識されます。
「貪欲マッチ」と「非貪欲マッチ」の違いと指定方法
繰り返し回数を指定する記号「?」「*」「+」は、できるだけ長いテキストにマッチさせる「貪欲マッチ」が行われます。これを一番短いテキストとのマッチングに変更したい場合は、各記号の直後に「?」を付けることで「非貪欲マッチ」に変更できます。
//サンプルプログラム
# coding: Shift-JIS
# Pythonの「reモジュール」をimportする
import re
# 検索対象の文字列を設定する
string = "<abc><xyz>"
# 検索対象の文字列を表示する
print("文字列:" + string)
# 「<.*>」で貪欲マッチを行う
print("「<.*>」:", end="")
print(re.search("<.*>", string))
# 「<.*?>」で貪欲マッチを行う
print("「<.*?>」:", end="")
print(re.search("<.*?>", string))
//実行結果
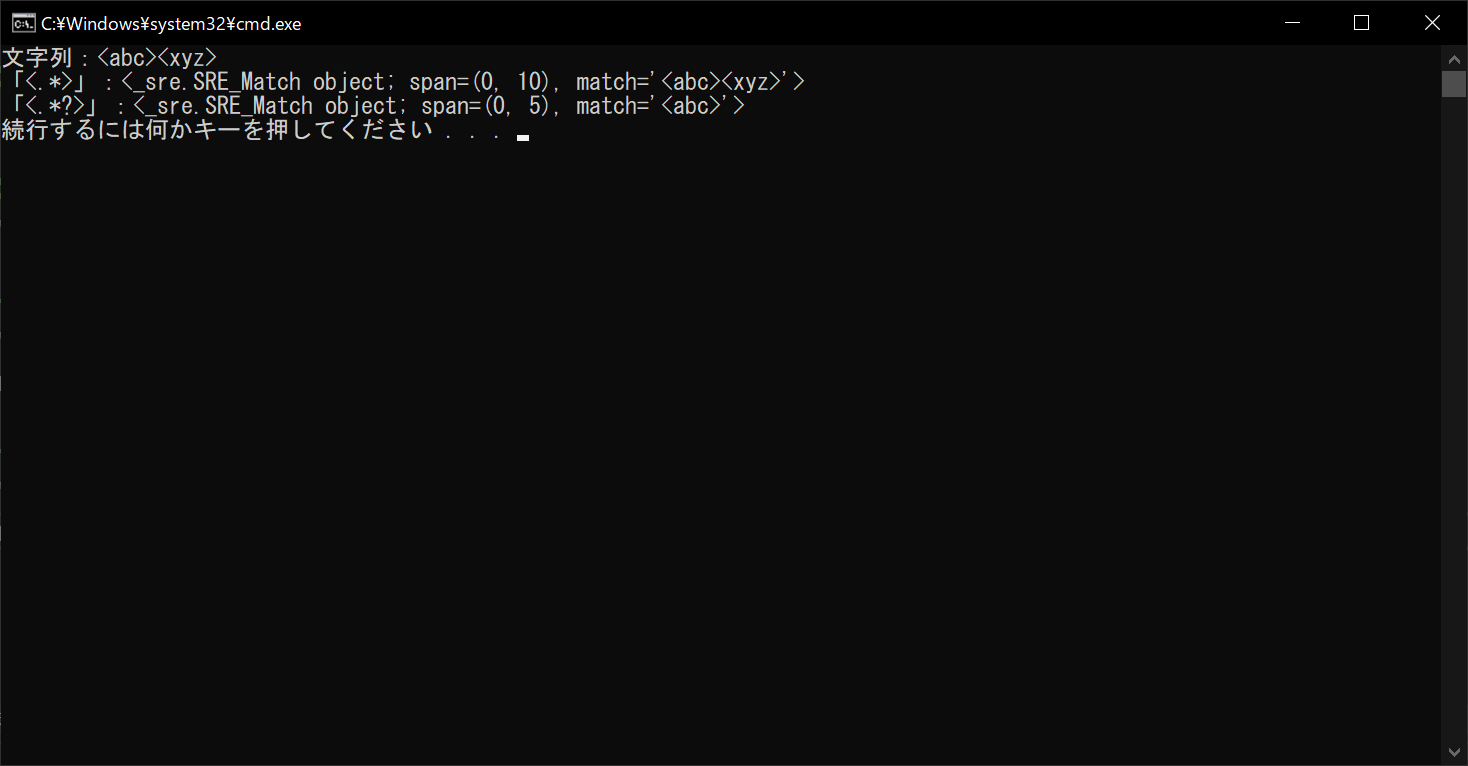
Pythonの正規表現で文字列を効率的に扱おう

Pythonの正規表現は、文字列を自在に扱うための必須知識です。特殊な記法を理解する必要があるため、最初は扱いづらく感じるかもしれません。しかし、正規表現は単なる「記号の並び」なので、記号の意味や使い方さえ覚えていけば使いこなせるようになります。
まずは「?」「*」「+」など、繰り返し回数を指定する単純な記号から覚えてみましょう。実際に文字列とのマッチングを繰り返していくと、次第に理解が深まっていきます。正規表現が使えるようになると、今までより高度な文字列操作を楽しめるでしょう。











アクセスランキング 人気のある記事をピックアップ!
コードカキタイがオススメする記事!

2024.06.17
子供におすすめのプログラミングスクール10選!学習メリットや教室選びのコツも紹介
#プログラミングスクール

2022.01.06
【完全版】大学生におすすめのプログラミングスクール13選!選ぶコツも詳しく解説
#プログラミングスクール

2024.01.26
【未経験でも転職可】30代におすすめプログラミングスクール8選!
#プログラミングスクール

2024.01.26
初心者必見!独学のJava学習方法とおすすめ本、アプリを詳しく解説
#JAVA

2024.01.26
忙しい社会人におすすめプログラミングスクール15選!失敗しない選び方も詳しく解説
#プログラミングスクール

2022.01.06
【無料あり】大阪のおすすめプログラミングスクール14選!スクール選びのコツも紹介
#プログラミングスクール

2024.01.26
【目的別】東京のおすすめプログラミングスクール20選!スクール選びのコツも徹底解説
#プログラミングスクール

2024.01.26
【無料あり】福岡のおすすめプログラミングスクール13選!選び方も詳しく解説
#プログラミングスクール

2024.01.26
【徹底比較】名古屋のおすすめプログラミングスクール13選!選び方も詳しく解説
#プログラミングスクール

2024.01.26
【徹底比較】おすすめのプログラミングスクール18選!失敗しない選び方も徹底解説
#プログラミングスクール